🤔Algorithm 과정 1. 한자리소수 -> 이 한자리 소수에서 파생되어 나온 두자리소수 -> ... 의 반복이므로 2. 한자리 소수는 [2, 3, 5, 7]이다. 3. 여기서 파생되는 소수는 다음과 같다. [2] - 23, 29 [3] - 31, 37 [5] - 53, 59 [7] - 71, 73, 79 위 과정을 계속 반복하여 입력된 자리수에 맞는 출력을 진행해주면 된다. 이는 재귀를 이용한 DFS를 통해 해결할 수 있으며 아래 그림을 통해 간단히 도식화 하였다.
🤫solution_2023 (시간초과)
import sys, math
sys.setrecursionlimit(10000)
input = sys.stdin.readline
N = int(input())
dec = [i for i in range(2, 8*10**(N))]
dec_front = []
for i in range(2, int(math.sqrt(10**(N+1))) + 1):
if i in dec:
dec_front.append(i)
dec = [j for j in dec if j % i != 0]
decimal = dec_front + dec
single_decimal = [2, 3, 5, 7]
def DFS(num):
if len(str(num)) == N:
print(num)
else:
for i in range(1, 10, 2):
if num*10 + i in decimal:
DFS(num*10 + i)
for i in single_decimal:
DFS(i)
🤫solution_2023
import sys
sys.setrecursionlimit(10000)
input = sys.stdin.readline
N = int(input())
single_decimal = [2, 3, 5, 7]
def decimal(num):
for i in range(2, num//2 + 1):
if num % i == 0:
return False
return True
def DFS(num):
if len(str(num)) == N:
print(num)
else:
for i in range(1, 10, 2):
if decimal(num*10 + i):
DFS(num*10 + i)
for i in single_decimal:
DFS(i)
cf. // 는 정수형 나눗셈이다.
🧐 백준 13023 (DFS) Gold V
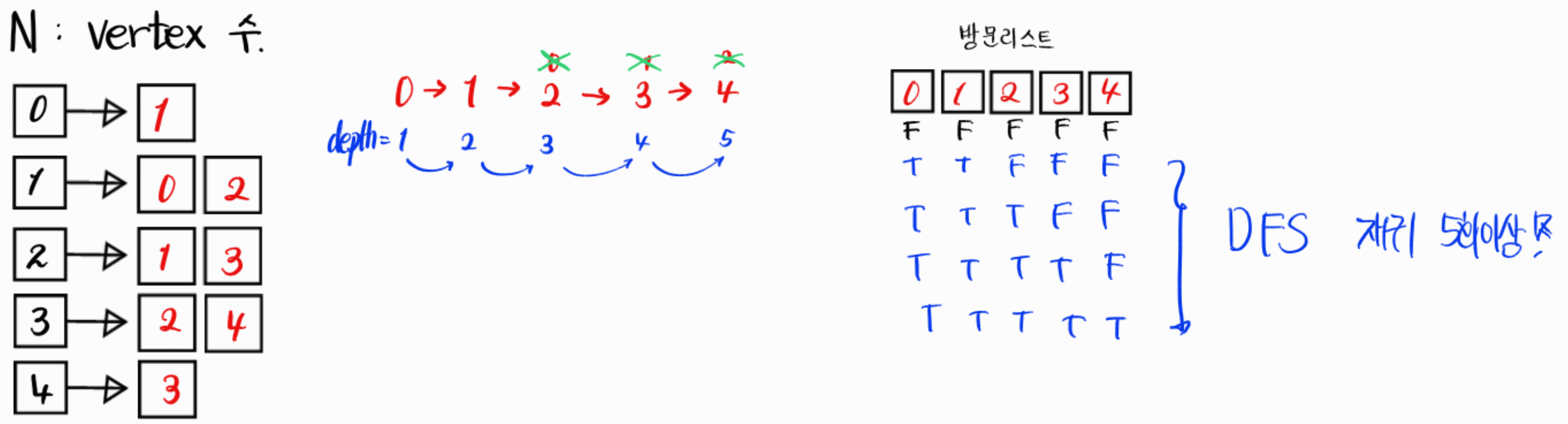
🤔Algorithm 과정 1. 그래프를 인접리스트로 저장한다. (무방향 그래프이기에 양쪽방향으로 간선을 모두 저장한다.) 2. 방문리스트를 모두 False로 초기화한다. 3. DFS를 수행하는데, 아래와 같이 진행한다. 4. 최종적으로 DFS의 재귀 횟수가 5회 이상이면 되므로 5회가 된 순간이 바로 임계점이다. 5. 따라서 재귀횟수가 5회면 바로 1을 출력하고 5회 미만이라면 0을 출력한다.
🤫solution_13023
# 백준 11724
# 친구 관계 5개를 찾는 문제 = 재귀 깊이가 5번 이상이면 된다.
import sys
input = sys.stdin.readline
V, m = map(int, input().split())
vertex = [[] for _ in range(V+1)]
# 방문 리스트 생성
visit_list = [False] * (V+1)
for _ in range(m):
u, v = map(int, input().split())
vertex[u].append(v)
vertex[v].append(u)
# print(vertex) => [[1], [0, 2], [1, 3], [2, 4], [3], []]
# 인접 리스트 생성 [0] [1] [2] [3] [4]
threshold = False
def DFS(curr_vertex, depth):
global threshold
if depth == 5:
threshold = True
return
visit_list[curr_vertex] = True
for i in vertex[curr_vertex]:
if not visit_list[i]:
DFS(i, depth+1)
visit_list[curr_vertex] = False
for i in range(V):
DFS(i, 1)
if threshold:
break
if threshold:
print(1)
else:
print(0)
DFS는 한 번 방문한 노드를 다시 방문하면 안된다. 따라서 노드 방문여부를 체크할 리스트가 필요하다.
DFS 탐색방식은 LIFO특성의 스택을 사용해 설명하자면, 아래와 같다.
1. DFS를 시작할 노드를 정한 후 사용할 자료구조 초기화 - DFS를 위해 필요한 초기 작업 아래와 같다. ‣ 인접리스트로 그래프를 표현 ‣ 방문리스트를 초기화하기 ‣ 시작 노드 스택에 삽입하기 - 스택에 시작노드를 1로 삽입할 때, 해당 위치의 방문리스트를 체크하면 T, F, F, F, F, F 이다.
2. 스택에서 노드를 꺼내 인접 노드를 다시 스택에 삽입 - 이제 pop을 수행하여 노드를 꺼내고 꺼낸 노드를 탐색순서에 기록한다. - 인접리스트의 인접노드를 스택에 삽입하며 방문리스트를 체크한다. - 이때, 방문리스트는 T, T, T, F, F, F 이다.
3. 스택에 값이 없을 때까지 반복 - 앞선 과정을 스택자료구조에 값이 없을 때까지 반복하며 이미 거친 노드는 재삽입 하지 않는 것이 핵심!
🤔 DFS 수도코드
DFS의 재귀 구현
DFS를 재귀로 구현하는 경우의 수도 코드는 다음과 같다.
쉽게 말하자면 정점을 방문하되 방문되었다고 표시하고 해당 정점의 인접 간선을 모두 탐색하는 것. 이때, 해당 정점이 방문되지 않았다면해당 정점에 대해서 다시 DFS를 call하는 형태
정점의 인접 간선을 하나씩 탐색 후 탐색이 불가능하면 빠져나와 다른 인접 간선을 이와 동일한 방식으로 탐색진행
<pseudocode>
DFS(G, v)
visit v;
mark v as visited;
for all directed edges from v to w that are in G.adjacentEdges(v) do
if vertex w is not marked as visited then
recursively call DFS(G, w)
<python code>
def recursive_dfs(v, visited=[]):
visited.append(v)
for w in graph[v]:
if not w in visited:
visited = recursive_dfs(w, visited)
return visited
이때, graph는 global 변수로 작용하게 되고, visited는 함수의 인자로 계속 넣어주는 형태이다.
이로 인해 visited를 리턴해서 계속 누적해주는 방식으로 진행을 해줘야한다.
DFS의 스택 구현
스택을 이용하는 경우에는 반복문을 이용해 구현할 수 있다. 스택을 이용해 모든 인접 간선을 추출하고 다시 도착점인 정점을 스택에 삽입하는 구조로 구현이 가능하다.
<pseudocode>
DFS_iterative(G,v)
let S be a stack
S.push(v)
while S is not empty do
v = S.pop()
if v is not marked as visited then
mark v as visited
for all edges from v to w in G.adjacentEdges(v) do
S.push(w)
스택에 한 번에 모든 인접 간선의 정점을 다 push하기 때문에 자칫 BFS로 오해하기 쉽다.
여기서 염두해야할 점은 stack에 push될 때가 아니라 pop이 되면서 방문을 check하는 구조이다.
따라서 정점 방문 순서로 본다면 확실히 DFS임을 알 수 있다.
<python code>
def iterative_dfs(start_v):
visited = []
stack = [start_v]
while stack:
v = stack.pop()
if v not in visited:
visited.append(v)
for w in graph[v]:
stack.append(w)
return visited
효율성
시간 복잡도
인접 행렬의 경우하나의 정점 당 n번 check를 해주어야 하기 때문에O(n^2)이다. 인접 리스트의 경우정점 방문 & 해당 정점의 인접 정점 방문이므로O(n+m)이다. 시간 복잡도의 경우에는 결국엔 어떤 정점을 탐색하느냐의 문제이기 때문에 공간 복잡도와 동일하다.
공간 복잡도
공간 복잡도의 경우, 그래프와 visited, 스택을 모두 고려해주어야 하기에 그래프의 공간복잡도는 다음과 같다. 인접 행렬의 경우에는 하나의 정점과 모든 정점 간의 연결 관계를 다 표현해주어야 하기 때문에 O(n^2)이다. 인접 리스트의 경우에는 그래프 내 정점 개수를 n, 간선 개수를 m이라고 할 때 O(n+m)이다.
결과적으로 공간복잡도는 그래프의 공간복잡도를 따라 가게 된다.
DFS의 효율성에 대해 말할 경우, 스택과 visited는 모두 O(n)의 공간복잡도를 가지고 있다 (정점 개수 n). 이는 그래프가 인접 행렬이나 인접 리스트로 구현되어 있든 두 가지 경우 모두에 해당한다.
🧐 백준 11724 (Connected Component)
- connected component 즉, 연결요소는 다음과 같은 조건에서 성립한다.
연결요소에 속한 모든 정점(vertex)을 연결하는 간선(edge)가 있어야 한다.
또 다른 연결요소에 속한 정점(vertex)과 연결하는 간선(edge)이 있으면 안된다.
🤔Algorithm 과정 0. 노드의 최대 개수가 1000이므로 시간복잡도 n^2이하의 알고리즘을 모두 사용할 수 있다. 1. 그래프를 인접리스트로 저장한다. (무방향 그래프이기에 양쪽방향으로 간선을 모두 저장한다.) 2. 방문리스트를 모두 False로 초기화한다. 3. DFS를 수행하는데, 아래와 같이 진행한다.
🤫solution_11724
import sys
sys.setrecursionlimit(10000)
input = sys.stdin.readline
V, E = map(int, input().split())
CC = [[] for _ in range(V+1)] # [[], [], [], [], [], [], []]
visit_list = [False] * (V+1)
for _ in range(E):
u, v = map(int, input().split())
# 양방향 간선이므로 양쪽에 정점 더하기.
CC[u].append(v)
CC[v].append(u)
# print(CC) => [[], [2, 5], [1, 5], [4], [3, 6], [2, 1], [4]]
# 인접리스트 생성 [1] [2] [3] [4] [5] [6]
def DFS(v):
visit_list[v] = True
for i in CC[v]:
if not visit_list[i]: # 연결요소가 방문리스트에 F로 되어있으면 True로 고치기 위한 재귀
DFS(i)
cnt = 0
for i in range(1, V+1):
if not visit_list[i]: # 1 2 3 4 5 6의 방문리스트에 대해 방문한적이 없다면
cnt += 1
DFS(i)
print(cnt)