🤔Algorithm 과정 1. s와 string 리스트에 입력에 해당하는 각각의 문자열을 넣음 2. for문으로 string을 돌면서 string에 있는 문자열과 일치하는 단어가 s에 있다면? 3. cnt값 1 증가 (= 일치하는 문자열이 있다는 것) 4. 최종적으로 cnt값 출력
🤫solution_14425
N, M = map(int, input().split())
s = [input() for _ in range(N)]
string = [input() for _ in range(M)]
cnt = 0
for i in string:
if i in s:
cnt += 1
print(cnt)
🧐 백준 10815, 10816(이진탐색)
🤔Algorithm 과정 1. 중복되어 입력되어도 비교만 하면 되기에 n이라는 set과 m이라는 리스트를 생성 2. 이후 m안의 원소를 돌면서 만약 m의 원소가 n에 있다면 1을 출력, 아니면 0을 출력해주면 된다. 3. 물론 위의 경우 m 리스트의 원소에 순서대로 접근하기 때문에 순서를 상관쓰지 않아도 된다.
🤫solution_10815
# cf. n을 list로 했더니 시간초과가 났음.
# 즉, 중복된 결과가 들어가게 되어 set보다 시간복잡도가 더 걸리게 되는 것.
N, n = input(), set(map(int, input().split()))
M, m = input(), list(map(int, input().split()))
m_set = list(set(m))
for i in m:
print(1, end = " ") if i in n else print(0, end = " ")
# 리스트를 실제로 분할해서 새로 저장하는 것은 O(N)으로 매우 무거운 연산
🤫해결의 실마리(10816): 이진탐색
🤔 count 함수를 무턱대고 쓰면 안된다?? count함수는 시간복잡도가 O(n)시간이 걸려서 for문과 같이 쓰면 시간초과가 발생할 확률이 높다.
🤔Algorithm 과정 1. cnt = {}로 딕셔너리를 생성한다. 2. cnt라는 비어있는 딕셔너리에 i 즉, n의 원소가 없다면 cnt[i] = 1로 원소와 개수를 맵핑 3. 만약 i in cnt라면 원소의 개수를 증가시켜줘야 하므로 cnt[i] += 1을 통해 value(원소의 개수)를 증가 4. 이후 m 안의 어떤 원소 i에 대해 cnt에 i가 있으면 value를 출력, 없으면 0을 출력한다.
🤫solution_10816(시간초과 ∵ count함수의 사용)
N, n = int(input()), list(map(int, input().split()))
M, m = int(input()), list(map(int, input().split()))
for i in m:
print(n.count(i), end = " ") if i in n else print(0, end = " ")
🤫solution_10816
N, n = int(input()), list(map(int, input().split()))
M, m = int(input()), list(map(int, input().split()))
cnt = {}
for i in n:
if i in cnt:
cnt[i] += 1
else:
cnt[i] = 1
# 딕셔너리 생성
# print(cnt) => {6: 1, 3: 2, 2: 1, 10: 3, -10: 2, 7: 1}
for i in m:
if i in cnt:
print(cnt[i], end = " ")
else:
print(0, end = " ")
🧐 백준 11478
🤔사실 문제에서 말하는 바는 등수를 출력하는 것과 동일! 🤔Algorithm 과정 1. s에 바로 문자열을 입력받는다. 이때, s에 "abcde"라는 문자열이 들어왔을때, s[1:3]으로 bc에 접근할 수 있다.]
2. set_s = set()를 통한 set을 생성해주고 3. 이중 for문에서 위의 인덱스 슬라이싱원리를 이용해 부분문자열을 구한다. 4. 이때, set_s에 넣어주는데, 중복된 문자열은 추가되지 않는다.
🤫solution_11478
s = input()
# print(s[1:3]) ba출력
set_s = set()
# 이중 for문을 돌면서 부분 문자열을 구하고 set_s에추가한다.
# 이때, set_s는 집합이기 때문에 중복된 문자열을 추가되지 않는다.
for i in range(len(s)):
for j in range(i, len(s)):
set_s.add(s[i:j+1])
print(len(set_s))
list 고유의 append, insert, pop, remove, sort함수를 사용할 수는 없다.
a = {'name': 'pey', 'phone': '0119993323', 'birth': '1118'}
print(a.keys())
print(list(a.keys()))
for i in a.keys():
print(i)
#-----------------출력----------------#
dict_keys(['name', 'phone', 'birth'])
['name', 'phone', 'birth']
name
phone
birth
§ Value 리스트 만들기 (values)
a = {'name': 'pey', 'phone': '0119993323', 'birth': '1118'}
print(a.values())
print(list(a.values()))
for i in a.values():
print(i)
#-----------------출력----------------#
dict_values(['pey', '0119993323', '1118'])
['pey', '0119993323', '1118']
pey
0119993323
1118
§ Key, Value 쌍 얻기 (items)
a = {'name': 'pey', 'phone': '0119993323', 'birth': '1118'}
print(a.items())
print(list(a.items()))
for i in a.items():
print(i)
#-----------------출력----------------#
dict_items([('name', 'pey'), ('phone', '0119993323'), ('birth', '1118')])
[('name', 'pey'), ('phone', '0119993323'), ('birth', '1118')]
('name', 'pey')
('phone', '0119993323')
('birth', '1118')
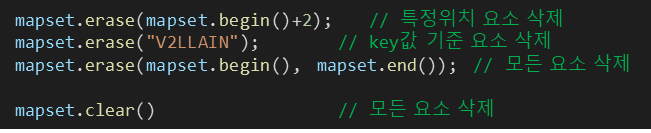
§ Key : Value 쌍 모두 지우기 (clear)
a = {'name': 'pey', 'phone': '0119993323', 'birth': '1118'}
a.clear()
print(a) # {} 출력
§ Key로 Value 얻기 (get)
a = {'name': 'pey', 'phone': '0119993323', 'birth': '1118'}
print(a.get('name')) # pey 출력
§ Key가 딕셔너리에 있는지 조사 (in) - True, False 반환
a = {'name': 'pey', 'phone': '0119993323', 'birth': '1118'}
print('name' in a) # True 출력
print('height' in a) # False 출력
※ 집합 (set)
set 키워드를 사용해 집합에 관련된 것을 쉽게 처리하기 위한 자료형이다.
s1 = set([1,2,3])
s2 = set("Hello")
print(s1) # {1, 2, 3} 출력
print(s2) # {'e', 'l', 'H', 'o'}과 같이 출력 (출력값 바뀔 수도 있음)
위에서 보면 print(s2)의 결과가 예상과 달리 나와 의문이었다.
이와 관련해 집합의 2가지 특징이 작용한다.
1. 중복을 허용하지 않는다.
2. 순서가 없다.
리스트나 튜플은 순서가 있기에 indexing을 통한 자료형값을 얻을 수 있다.
하지만 딕셔너리나 set 자료형은 순서가 없어서 indexing으로 값을 얻을 수 없다.
따라서 저장된 값을 indexing으로 접근하려면 리스트나 튜플로 변환 후 가능하다!
s = set([1,2,3])
a = list(s)
print(a)
# {1, 2, 3}와 같은 set형식이 아닌 [1, 2, 3]같은 list형식으로 출력
※vector(std::vector) _가변배열 / 가장 기본이 되는 컨테이너 (★★★★★)
#include <vector>
using namespace std;
vector<자료형> 변수명(숫자) //숫자만큼 벡터 생성 후 0으로 초기화
vector<자료형> 변수명(숫자, 변수1); //숫자만큼 벡터 생성 후 변수1으로 모든 원소 초기화
vector<자료형> 변수명{숫자, 변수1, 변수2, 변수3, ...}; // 벡터 생성 후 오른쪽 변수 값으로 초기화
vector<자료형> 변수명[]={ {변수1, 변수2}, {변수3, 변수4}, ...} //2차원 벡터생성 (열은 고정, 행 가변)
vector<vector <자료형>> 변수명 //2차원 벡터생성 (열, 행 가변)
ex);
vector<int> vec1; // 크기가 0인 벡터 선언
vector<int> vec2(10); // 크기가 10인 벡터 선언
vector<int> vec3(10, 3); // 크기가 10이고 모든 원소가 3으로 초기화된 벡터
vector<int> vec4 = { 1,2,3,4,5 }; // 크기가 지정한 초기값으로 이루어진 벡터
vector<int> vec5[] = { {1,2},{3,4} }; // 벡터 배열 생성(행은 가변인지만, 열은 고정)
vector<vector<int>> vec6; // 2차원 벡터 생성(행과 열 모두 가변)
- set은 연관 컨테이너로 삽입, 삭제, 검색의 시간복잡도가O(logn) 인 Binary Search Tree로 구현되어 있다.
- key라는 원소들의 "집합"으로 key값은 중복되지 않는다!
- insert()를 통한 자동적으로 오름차순 정렬이 가능하다.
∴중복을 피하면서 정렬까지 사용할 때 매우 유용하다!
insert(k): 원소 k 삽입 begin(): 맨 첫번째 원소를 가리키는 iterator를 반환 end():맨 마지막 원소를 가리키는 iterator를 반환 find(k): 원소 k를 가리키는 iterator를 반환 size(): set의 원소 수 empty():비어있는지 확인
※algorithm
※ STL 알고리즘의 분류
find()는 2개의 입력 반복자로 지정된 범위에서 특정 값을 가지는 첫 번째 요소를 가리키는 입력 반복자를 반환
for_each()는 2개의 입력 반복자로 지정된 범위의 모든 요소를 함수 객체에 대입한 후, 대입한 함수 객체를 반환
copy()는 2개의 입력 반복자로 지정된 범위의 모든 요소를 출력 반복자가 가리키는 위치에 복사
swap()은 2개의 참조가 가리키는 위치의 값을 서로 교환
transform()은 2개의 입력 반복자로 지정된 범위의 모든 요소를 함수 객체에 대입후, 출력 반복자가 가리키는 위치에 복사
sort()는 2개의 임의 접근 반복자로 지정된 범위의 모든 요소를 비교, 오름차순정렬.
stable_sort()는 2개의 임의 접근 반복자로 지정된 범위의 모든 요소를 비교, 값이 같은 요소들의 상대적인 순서는 유지, 오름차순으로 정렬합니다.
binary_sort()는 정렬되어있는 경우(오름차순)에 한해서 탐색효율이 매우 좋고 적은 시간에 소요된다.
accumulate()는 두 개의 입력 반복자로 지정된 범위의 모든 요소의 합을 반환합니다.
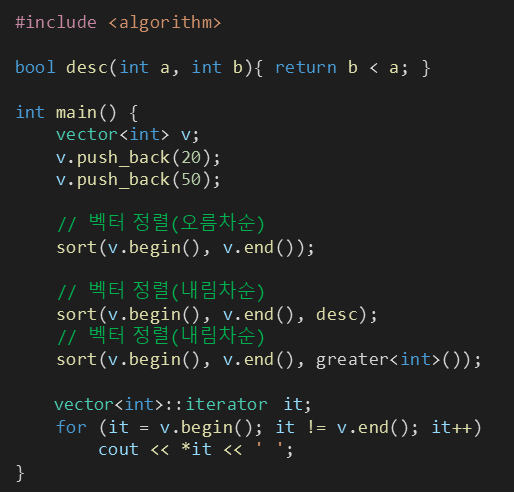
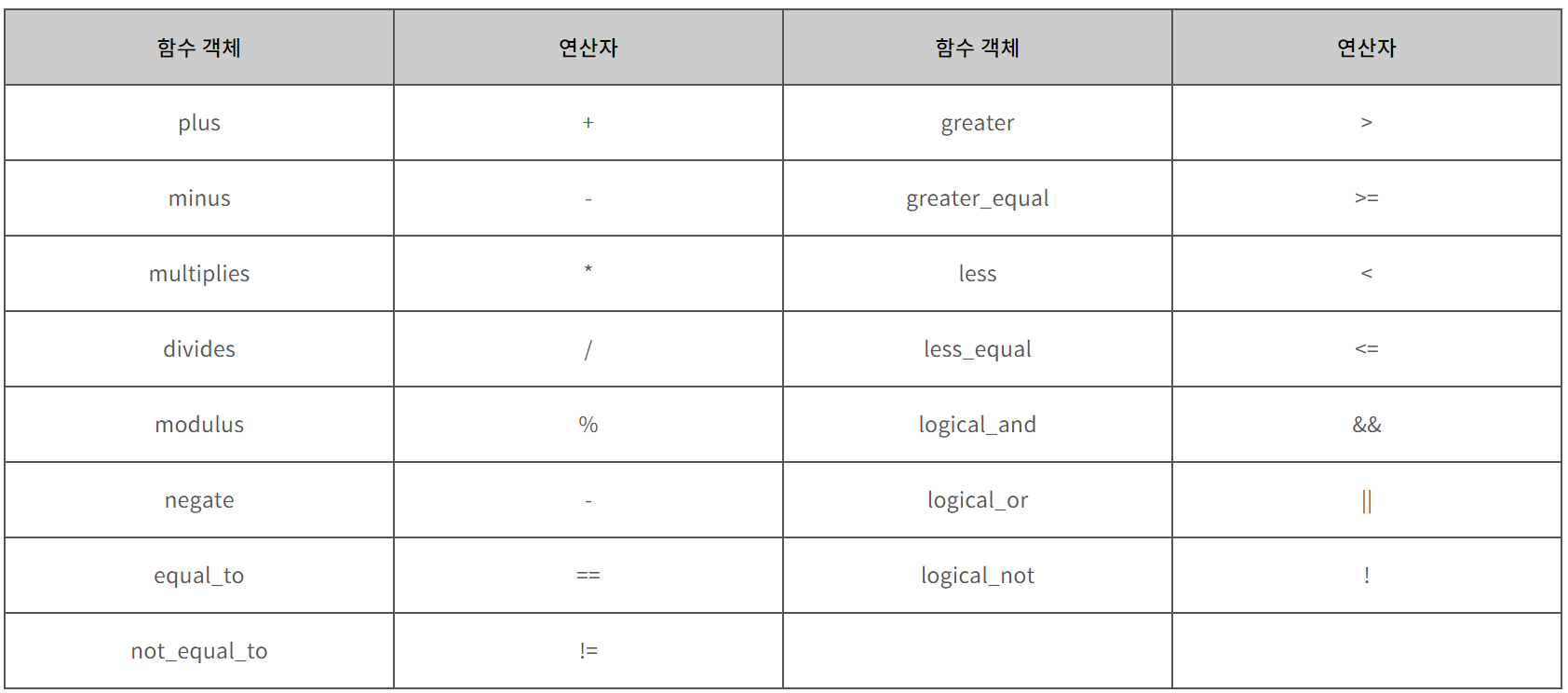
※ 벡터의 오름차순과 내림차순 정렬 (feat. greater<int> 키워드)
§ sort() 함수 형식
단, custom_func()은 0 또는 1이 나오도록 해야해서 보통 bool형 함수를 많이 넣는다.