PLMs를 specific task에 적용할 때, 대부분의 Parameter를 freeze❄️, 소수의 parameter만 FT하는 기법. PEFT는 모델 성능을 유지 + #parameter↓가 가능함. 또한, catastrophic forgetting문제 위험도 또한 낮음. 🤗Huggingface에서 소개한 혁신적 방법으로 downstream task에서 FT를 위해 사용됨.
Catastrophic Forgetting이란?
새로운 정보를 학습하게 될때, 기존에 학습한 일부의 지식에 대해서는 망각을 하게 되는 현상
Main Concept
Reduced Parameter Fine-tuning(축소된 파라미터 파인튜닝) 사전 학습된 LLM 모델에서 대다수의 파라미터를 고정해 소수의 추가적인 파라미터만 파인튜닝하는 것이 중점 선택적 파인튜닝으로 계산적 요구가 급격하게 감소하는 효과
Overcoming Catastrophic Forgetting(치명적 망각 문제 극복) Catastrophic Forgetting 문제는 LLM 모델 전체를 파인 튜닝하는 과정에서 발생하는 현상인데, PEFT를 활용하여 치명적 망각 문제를 완화할 수 있음 PEFT를 활용하면 사전 훈련된 상태의 지식을 보존하며 새로운 downstream task에 대해 학습할 수 있음
Application Across Modalities(여러 모달리티 적용 가능) PEFT는 기존 자연어처리(Natural Language Process: NLP) 영역을 넘어서 다양한 영역으로 확장 가능함 스테이블 디퓨전(stable diffusion) 혹은 Layout LM 등의 포함된 컴퓨터 비전(Computer Vision: CV) 영역, Whisper나 XLS-R이 포함된 오디오 등의 다양한 마달리티에 성공적으로 적용됨
Supported PEFT Methods(사용 가능한 PEFT) 라이브러리에서 다양한 PEFT 방법을 지원함 LoRA(Low-Rank Adaption), Prefix Tuning, 프롬프트 튜닝 등 각각의 방법은 특정한 미세 조정 요구 사항과 시나리오에 맞게 사용할 수 있도록 설계됨
The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrics A and B (right).
사전학습가중치(❄️)의 output activation은 weight matrix인 A, B로 구성된 LoRA에 의해 증가된다.
[Q-LoRA]: Quantized-LoRA
Q-LoRA란?
2023년 5월 NeurIPS에서 양자화와 LoRA를 합쳐 "A6000 단일 GPU로 65B모델 튜닝이 가능"한 방법론을 발표함. QLoRA는 결국 기존의 LoRA에 새로운 quantization을 더한 형태이다. 베이스 모델인 PLM의 가중치를 얼리고(frozen), LoRA 어댑터의 가중치만 학습 가능하게(trainable)하는 것은 LoRA와 동일하며, frozen PLM의 가중치가 '4비트로 양자화'되었다는 정도가 다른 점이다. 때문에, QLoRA에서 주요히 새로 소개되는 기술(Main Contribution)은 양자화 방법론이 주가 된다는 사실이다.
양자화란?
weight와 activation output을 더 작은 bit단위로 표현하도록 변환하는 것. 즉, data정보를 약간줄이고, 정밀도는 낮추지만 "저장 및 연산에 필요한 연산을 감소시켜 효율성을 확보"하는 경량화 방법론이다.
How to Use in MLLMs...?
그렇다면 어떻게 MLLMs에 적용할 수 있을까? MLLMs는 매우 종류가 많지만, 가장 쉬운 예제로 VLMs를 들어보자면, Q-LoRA 및 LoRA는 PEFT방법론이기에 이는 LLMs, MLLMs모두 통용되는 방법이다. 그렇기에 VLMs(Vision Encoder + LLM Decoder)를 기준으로 설명해보자면:
언어적 능력을 강화시키고 싶다면, LLM만 PEFT를 진행.
시각적 능력을 강화시키고 싶다면, Vision Encoder만 PEFT를 진행.
두 능력 모두 강화시키고 싶다면, Encoder, Decoder 모두 PEFT를 진행하면 된다.
물론 나만의 방법을 고수하는것도 좋지만, 대부분의 user들이 이 방법을 사용하는걸 봐서는 일단 알아놓는게 좋을 것 같기에 알아보고자한다.
deepspeed...?
모델의 training, inference속도를 빠르고 효율적으로 처리하게 도와주는 Microsoft사의 딥러닝 최적화 라이브러리이다. 학습 device 종류:
CPU Single GPU 1 Node, Multi GPU Multi Node, Multi GPU --> 매우 큰 GPT4 등의 학습을 위해 사용됨.
분산학습 방식:
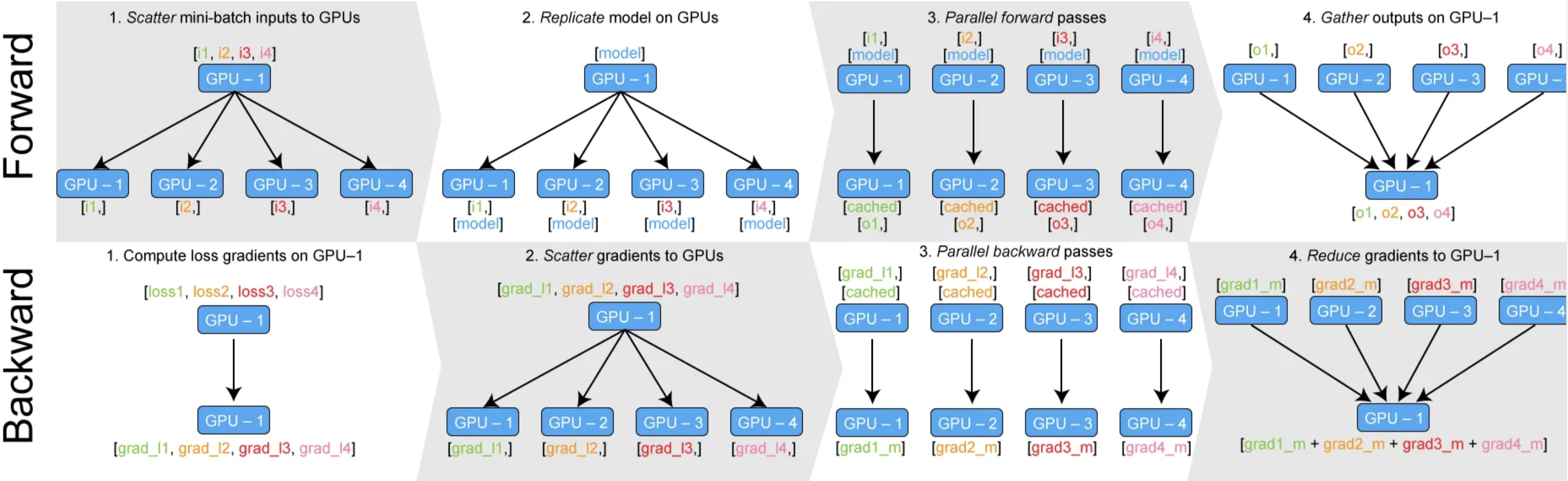
Data Parallel: 하나의 device가 data를 나누고, 각 device에서 처리결과를 모아 계산 --> 하나의 device가 다른 device에 비해 메모리 사용량이 많아지는, 메모리 불균형 문제가 발생한다!
Distributed Data Parallel: 각각의 device를 하나의 Process로 보고, 각 process에서 모델을 띄워서 사용. 이때, 역전파에서만 내부적으로 gradient를 동기화 --> 메모리 불균형문제❌
cf) Requirements:
- PyTorch must be installed before installing DeepSpeed.
- For full feature support we recommend a version of PyTorch that is >= 1.9 and ideally the latest PyTorch stable release.
- A CUDA or ROCm compiler such as nvcc or hipcc used to compile C++/CUDA/HIP extensions.
- Specific GPUs we develop and test against are listed below, this doesn't mean your GPU will not work if it doesn't fall into this category it's just DeepSpeed is most well tested on the following:
NVIDIA: Pascal, Volta, Ampere, and Hopper architectures
AMD: MI100 and MI200