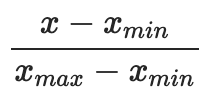🤫 Neural Network perceptron에서 단지 층이 여러개 늘어난 것 뿐이지만, XOR 문제처럼 하나의 perceptron으로 해결하기 어려웠던 문제를 해결할 수 있다. 다수의 뉴런을 사용해 만든 것을 인공신경망(artificial neural network)라 하며, 줄여서 신경망(neural network)라 한다. 이런 신경망은 아래와 같은 모양으로 되어있는데, 이때 은닉층(hidden layer)의 깊이가 깊은 것을 이용한 학습방법을 Deep Learning이라 한다.
신경망: 입력층에서 은닉층으로 값을 전달하는 함수는 vector-to-vector함수 딥러닝: 함수는 vector-to-scalar함수( ∵ 벡터를구성하는데이터값들이개별적으로자유롭게활동) input layer(입력층): input은 data의 feature로 node의 개수 = feature의 개수이다. output layter(출력층): node개수 = 분류하려는 class의 개수이며 이때, 각 클래스의 score 중 가장 높은값을 갖는 class를 최종적으로 선정한다.
🧐 back propagation (오차 역전파)
🤫 오차 역전파 (back propagation)
다층 퍼셉트론(multi-perceptron)에서 최적값을 찾아가는 과정은 오차역전파(back propagation)방법을 사용한다.
역전파라는 말처럼 역전파는 출력층-은닉층-입력층 순서대로 반대로 거슬러 올라가는 방법이다.
오차역전파를 통해 오차를 기반으로 가중치(weight)를 수정한 후 더 좋은 성능을 내도록 모델을 개선한다.
🤫 back propagation 과정
1) weight 초기화
2) forward propagation을 통한 output 계산
3) Cost function 정의, 1차 미분식 구하기. => 실제값 t에 대해, ([t-z]^2) / 2
4) back propagation을 통한 1차 미분값 구하기
5) 학습률(learning rate)설정 후 parameter(weight, bias) update
6) 2 ~ 6의 과정 반복
🧐 activation function (활성화 함수)
🤫활성화 함수 (activation function) 활성화 함수는 input, weight, bias로 계산되어 나온 값에 대해 해당 노드를 활성화 할 것인지를 결정하는 함수이다.
🤫 활성화 함수의 종류 계단 함수(step function): 0을 기점으로 출력값은 0과 1, 두가지 값만 갖는특징이 있다.
(다만 0에서 미분불가능이라는 단점이 존재)
부호 함수(sign function): 계단함수와 비슷하지만 0을 기점으로 -1, 0, 1 세 값을 갖는 특징이 있다.
Sigmoid function: 1/(1 + exp(-x)) 로 0과 1사이 값을 출력한다.
다만 단점이 존재하는데, 바로 vanishing gradient problem이다.
Vanishing gradient problem: 학습하는 과정에서 미분을 반복하면 gradient값이 점점 작아져 소실될 가능성이 있다.
0~1사이인 sigmoid함수를 변형한 함수로 tanh함수는 -1 ~ 1사이의 범위를 갖는다.
ReLU 함수 (Rectified Linear function):max(x, 0)로 앞선 함수들과 다르게 상한선이 없다는 특징이 있다.
Leaky ReLU 함수: a <= 1일 때, max(x, ax)로 보통 a는 0.01값을 갖는다.
항등함수(identity function, linear function): x로 입력값과 출력값이 동일하다.
주로 regression문제에서 최종 출력층에 사용되는 활성화 함수.
softmax function: exp(x) / Σ(exp(x))
주로 classification최종 출력층에 사용되는 활성화 함수.
다만 위의 식을 그대로 사용할 경우, overflow발생의 가능성 때문에 아래와 같이 사용한다.
exp(x + C) / Σ(exp(x + C))
이때, 상수 C는 일반적으로 입력값의 최댓값을 이용한다.
또한 softmax는 결과가 0~1사이이기에 이를 확률에 대응하여 해석할 수 있다.(입력이 크면 확률도 크다는 비례관계.)
즉, 어떤 값이 가장 크게 출력될 지 예측가능하다.
🧐 batch normalization
🤫 batch size란?
batch 크기는 모델 학습 중 parameter를 업데이트할 때 사용할 데이터 개수를 의미한다. 사람이 문제 풀이를 통해 학습해 나가는 과정을 예로 들면, batch 크기는 몇 문제를 한 번에 쭉 풀고 채점할지를 결정하는 것이다. 예를 들어, 총 100개의 문제가 있을 때, 20개씩 풀고 채점한다면 batch 크기는 20이다.
이를 이용해 딥러닝 모델은 batch 크기만큼 데이터를 활용해 모델이 예측한 값과 실제 정답 간의 오차(conf. 손실함수)를 계산하여 optimizer가 parameter를 업데이트합니다.
🤫batch normalization layer의 값의 분포를 변경하는 방법으로 평균과 분산을 고정시키는 방법이다. 이를 이용하면 gradient 소실문제를 줄여 학습 속도를 향상시킬 수 있다는 장점이 존재한다.
Mini-batch mean, variance를 이용해 정규화(normalize)시킨 후 평균 0, 분산 1의 분포를 따르게 만든다. N(0, 1^2)
이때, scale parameter γ와 shift parameter β를 이용해 정규화시킨 값을 Affine transformation을 하면 scale and shift가 가능하다.
🤫 normalization? standardization? Regularization?
Normalization
값의 범위(scale)를 0~1 사이의 값으로 바꾸는 것
학습 전에 scaling하는 것
머신러닝에서 scale이 큰 feature의 영향이 비대해지는 것을 방지
딥러닝에서 Local Minima에 빠질 위험 감소(학습 속도 향상)
scikit-learn에서 MinMaxScaler
Standardization
값의 범위(scale)를 평균 0, 분산 1이 되도록 변환
학습 전에 scaling하는 것
머신러닝에서 scale이 큰 feature의 영향이 비대해지는 것을 방지
딥러닝에서 Local Minima에 빠질 위험 감소(학습 속도 향상)
정규분포를 표준정규분포로 변환하는 것과 같음
Z-score(표준 점수)
-1 ~ 1 사이에 68%가 있고, -2 ~ 2 사이에 95%가 있고, -3 ~ 3 사이에 99%가 있음
-3 ~ 3의 범위를 벗어나면 outlier일 확률이 높음
표준화로 번역하기도 함
scikit-learn에서 StandardScaler
Regularization
weight를 조정하는데 규제(제약)를 거는 기법
Overfitting을 막기위해 사용함
L1 regularization, L2 regularizaion 등의 종류가 있음
L1: LASSO(라쏘), 마름모
L2: Lidge(릿지), 원
🧐 Drop Out
🤫 드롭 아웃 (Drop out)
신경망의 모든 노드를 사용하지 않는 방법으로 신경망에서 일부 노드를 일시적으로 제거하는 방법이다.
이때, 어떤 노드를 일시적으로 제거할 것인지는 무작위로 선택하는데, 이 방법은 연산량을 줄여 overfitting(과적합)을 방지할 수 있다.