<Interrupt Handling>
device가 자신에게 어떤일이 발생했음을 OS(kernel)에 처리해달라 요청하는 것.
<Interrupt_ Kernel entry points (kernel 실행코드에 진입방법 – 3가지)>
Interrupt
Trap (software interrupt)
System call (user process의 요청)
<Interrupt, Interrupt Handling: 누가 interrupt를 걸었는지 조사>
주변장치(peripheral device)가 비동기적 event 발생을 OS에게 알리는 것.
cf. asynchronous event: event 발생시점이 명확히 정해져 있지 않은 것.
clock: 1ms마다 interrupt를 거는데 user와 kernel(모두 실행 후 user로 돌아감)을 반복한다.
if. tty가 신호를 주면 cpu에서 받은 신호의 register값을 kernel stack에 저장, mode change로 kernel에 진입한다.

ISR ⊂ IDT(IVT)
IDT: kernel에서 interrupt entry값 번호를 받는 table
ISR: 특정장치의 interrupt를 처리하는 함수, urgent part(interrupt가 급한일 먼저 실행)와 remaining part(안급한일) 존재.
<interrupt 이후 하는 일> => 구 후 user mode로 돌아감
남은 부분 처리 (remaining parts of interrupt routines)
새 signal, process 조사
<Trap Handling>
synchronous software event(사실은 cpu 하드웨어가 interrupt를 거는 것, 사실 trap과 interrupt는 같은방식)
cf. synchronous event: event의 발생, 도착의 시간이 정해져 있음.
<Trap Handling의 예>
분모가 0인 경우(div_by_zero) , instruction 안의 machine code가 invalid
메모리 주소가 잘못됨 (segmentation fault) , 정보 보호 오류 (protection fault)
메모리에 안들어와 있음 (page fault)
<System calls Handling>_ kernel함수를 불러 user process에게 도움을 요청
sys_call_table을 IDT에 모두 넣을 수 없어 system call로 불러 사용하는 방식.
<I/O Control>: OS가 장치의 상채를 check하면서 제어하는 방법 (3가지)
Polling: Programming I/O
Interrupt-driven(기반) I/O
Direct Memory Access (DMA)
<Polling>: status register bit값을 check하면서 상태를 확인하는 방법 (process switch는 발생하지 않음)
원인: cpu가 device driver instruction을 반복적으로 실행
device driver는 장치의 controller내부 state register에서 장치가 일하는지 알기위해 busy bit를 읽는다.
이때, busy bit=1: busy state, 0: 안바쁜 상태
- OS는 이런 bit가 0일 때, write bit을 1로 만든다.
그 후 data-out register에 bit를 저장
command-ready bit을 1로 설정
busy bit도 1로 설정
I/O가 모두 끝나면 ready-bit와 busy bit을 0으로 설정
device 상태를 계속 check함(Polling)의 효율성
효율적: I/O가 빨리 끝나는 장치
비효율적: I/O가 늦게 끝나는 장치

<Interrupt-driven I/O>: 장점: 주어진 시간내 더 많은 process 실행 가능 / 장점과 단점이 polling과 반대.

cf. Context Switch 4가지 中 7~12과정으로 인해 block->ready가 된 것이다.
<Direct Memory Access (DMA)>
cpu 반복은 cpu 효율이 안좋아지며 DMA controller라는 별도의 processor로 단위시간당 사용가능한 user process 수가 많아진다.

<Disk 구조 및 용어>
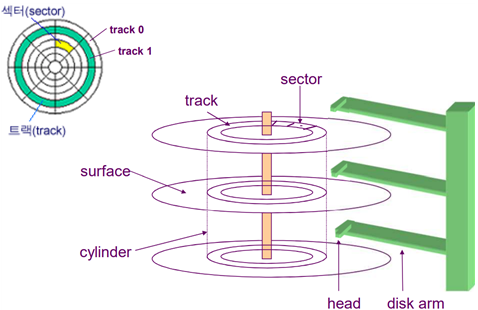
sector: 제조사가 정의한 물리적 저장 최소단위, block(4096B)과 맵핑해줘야 함
surface: disk*2개로 위 아래면이 있다.
track: 디스크의 한줄의 띄로 surface를 나눈 것
cylinder: 같은 track의 집합
disk arm과 head: track을 이동하며 정보를 읽음
sector와 block 크기가 같다면 sector와 block은 일대일 맵핑됨(실린더 단위로 맵핑 후 disk축으로 들어가는 방식)
<Timing of a Disk I/O Transfer>
arm이 읽을 sector가 있는 track으로 이동, arm 끝의 head가 해당 track으로 이동
[Seek time]: arm이 track까지 이동하는데 걸린 시간
[Rotational delay]: head가 회전하는 disk에서 sector와 만나는데 걸리는 시간
[Device Busy]: Seek -> Rotational Delay -> Data transfer까지 걸리는 시간
<Disk Scheduling> , rotational delay: 도는데 걸리는 시간(평균=0.5바퀴)
결과적으로 Seek time이 성능을 좌우해서 Disk scheduling을 사용해야 한다!
<Disk Scheduling Policies> track order: 55, 58, 39, 18, 90, 160, 150, 38, 184

<Disk Cache = buffer cache = page cache>: 저속저장장치로 main memory에 사본을 caching함.
disk에 직접접근할 필요없이 memory 사본접근으로 훨씬 빠름.
<Cache Replacement>: memory의 disk사본저장공간이 꽉 차있을 때, 어떤 block을 없애고 빈자리로 해야하는가
LRU(Least Recently Used): 시간기준, 가장오래된 것 삭제
LFU(Least Frequently Used): 횟수기준, 적은 것 삭제
'Computer System > 운영체제' 카테고리의 다른 글
| this->OS.code(12) (0) | 2022.12.21 |
|---|---|
| this->OS.code(11) (2) | 2022.12.21 |
| this->OS.code(9) (0) | 2022.12.21 |
| this->OS.code(8) (0) | 2022.10.31 |
| this->OS.code(7) (0) | 2022.10.31 |