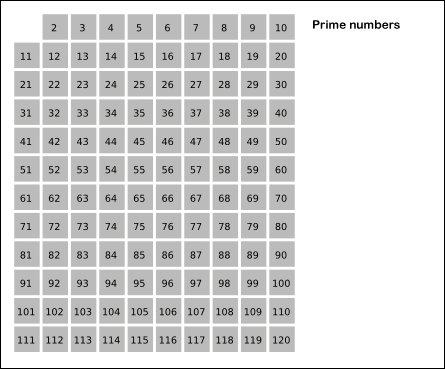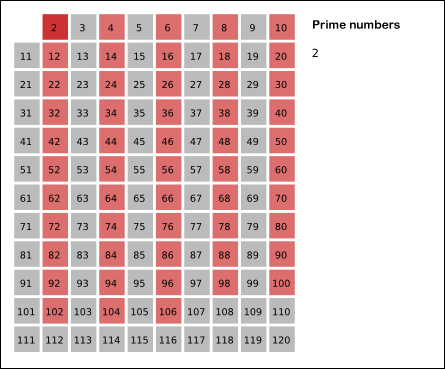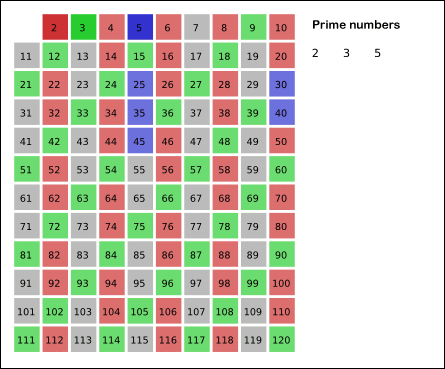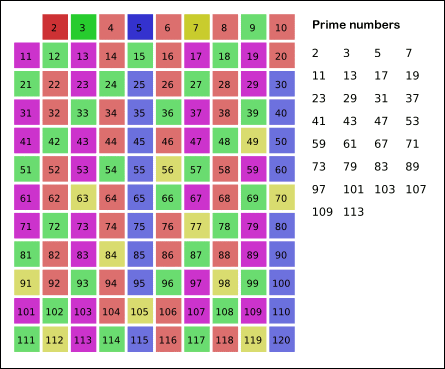
2143 => 1234처럼 만들어야 하므로 먼저 str로 받고 원소 각각을 비교하면 된다.
🧐 백준 2108 (통계학 _ statistics 라이브러리 이용)
🤫해결의 실마리
🤔 수학 통계 내장함수 statistics (https://python.flowdas.com/library/statistics.html) 이 문제의 경우, 최빈값을 구하기 위해 count함수를 사용하게 될 경우, 이로 인해 시간초과가 걸리게 된다. 따라서 아래의 통계학관련 statistics 라이브러리의 multimode()함수를 이용해 최빈값을 구해준다.
import statistics as st
num = [int(input()) for _ in range(int(input()))]
mode =st.multimode(num)
if len(mode) > 1:
mode.remove(min(mode))
print(int(sum(num)/len(num)))
print(round(st.median(num)))
print(min(mode))
print(max(num) - min(num))
🧐 백준 10814,11650, 11651 (C++의 pair와 같은 자료구조가 필요해!) ★★★★★
🤫해결의 실마리 1. python의 sort는 stable 정렬을 한다.
파이썬은 기본적으로 stable_sort이기에 나이 기준 정렬을 해도 가입한 순서는 그대로!
🤫해결의 실마리 2. 2차원 리스트의 경우, 하나의 for문으로 접근할 수 있다!
파이썬은 다음과 같이 2차원 배열의 경우, 한번에 요소에 접근할 수 있다.
arr = list(input().split() for _ in range(int(input())))
for x, y in arr:
print(x, y) => arr[0][0], arr[0][1]
🤔Algorithm 과정 굳이 int로 받지 않아도 어차피 '20' < '21' 이므로 정렬한 person리스트를 for문을 이용해 접근한다. 이때, 정렬할 때, key = lambda식을 이용해 a[0], 즉 나이를 기준으로 정렬하는 방법을 사용한다.
🤫solution_10814
# 파이썬의 sort함수는 기본적으로 stable정렬을 한다.
person = list(input().split() for _ in range(int(input())))
# str로 받아도 원소값을 int로 받아 비교가 가능하다.
for x, y in sorted(person, key = lambda a: int(a[0])):
print(x, y)
10814와 마찬가지로 해결
🤫solution_11650
num = [list(map(int, input().split())) for _ in range(int(input()))]
# num에는 다음과 같은 형태로 저장됨
# [[3, 4], [1, 1], [1, -1], [2, 2], [3, 3]]
# for문으로 2차원 리스트 요소 출력
# [1, -1] [1, 1] [2, 2] [3, 3] [3, 4]
for x, y in sorted(num):
print(x, y)
🤫solution_11651
num = [list(map(int, input().split())) for _ in range(int(input()))]
# 맨 뒤의 원소 a[1]을 기준으로 정렬 후 a[0]을 기준으로 정렬
for x, y in sorted(num, key = lambda a: (a[1], a[0])):
print(x, y)
단, 이 문제에서 유의할 점은 python은 정렬에서 기준 여러 개 세울 수 있다는 점이다. 위에서 처럼 말이다.
# 맨 뒤의 원소 a[1]을 기준으로 정렬 후 a[0]을 기준으로 정렬
sorted(num, key = lambda a: (a[1], a[0])):
🧐 백준 18870 (메모리에 대한 접근)
🤫해결의 실마리 1. 메모리 제한이 여유롭다??
🤔 이 문제는 메모리 제한이 512MB로 여유로운데, 이에 대해 살펴볼 필요가 있다. - 메모리 제한이 많음 = 순서를 따로 저장(hash)하지 않으면 시간초과가 발생할 것이라 유추 - 순서만 간단히 비교하면 되기에 set으로 중복을 없애고 sort를 진행하면 더 간단히 해결 가능. 🤔사실 문제에서 말하는 바는 등수를 출력하는 것과 동일!
🤫해결의 실마리 2. 딕셔너리 자료구조
🤔 Dictionary. -key-value 형태로 이루어진 자료구조로 값과 데이터의 대응관계를 표현할 때, powerful하다. -이때, 핵심은 key값은 중복될 수 없다는 점이며 아래의 코드를 예시로 들어 보겠다.
# x_set에는 [-10, -9, 2, 4] 원소가 들어가있는 set리스트이다.
x_dict = {x_set[i] : i for i in range(len(x_set))}
#x_dict = { -10: 0, -9: 1, 2: 2, 4: 3 }
# print(x_dict[-9]) # key값을 이용한 value, 1 출력
🤔Algorithm 과정 1. 입력값을 저장하는 x리스트와 2. x리스트의 원소들이 겹치지 않도록 set을 만들어 정렬시켜준다. 3. 오름차순 정렬이 된 set에 index를 맵핑해주면 그것이 비로소 순위가 되므로 4. set_element : index의 맵핑을 위해 딕셔너리를 사용해준다. 5. 그 후 x리스트를 돌면서 해당 원소와 일치하는 값과 맵핑한 딕셔너리의 value값(인덱스, 순위 값)을 출력
🤫solution_18870 (시간초과)
N = int(input())
x = list(map(int, input().split()))
x_prime = []
for i in x:
cnt = 0
for j in set(sorted(x)):
if i > j:
cnt += 1
x_prime.append(cnt)
print(*x_prime)
처음 짠 코드로 문제점은 이중 for문을 이용하여 if문을 2번 돌리면 시간복잡도가 O(n^2)이다. 이 문항의 경우 시간복잡도가 O(nlog n)의 정렬 알고리즘이 필요하다.
🤫solution_18870
N = int(input())
x = list(map(int, input().split()))
x_set = sorted(list(set(x)))
x_prime = []
# x_set의 [-10, -9, 2, 4]에 index를 맵핑하여 딕셔너리로(순위)
# cf. 딕셔너리는 해시를 이용해 데이터 저장
x_dict = {x_set[i] : i for i in range(len(x_set))}
#x_dict = {-10: 0, -9: 1, 2: 2, 4: 3}
# print(x_dict[-9]) # 1 출력
for i in x:
print(x_dict[i], end = " ")
🤔 Algorithm 과정 1. num이라는 빈 리스트에 입력된 M ~ N까지의 숫자를 넣는다. 2. 약수의 개수를 세는 cnt라는 변수를 선언, 0으로 초기화한다. 3. 소수를 담을 리스트 dec을 선언한다. 4. num리스트의 원소를 차례로 돌면서 i % j == 0 즉, 약수일 때, cnt값을 증가시킨다. 5. 이렇게 약수의 개수가 담긴 cnt변수에 대해 만약 약수의 개수가 2개라면(cnt == 2) 소수인것! 따라서 소수라면 dec 리스트에 원소를 추가해주고 cnt==0이라면 소수가 없는 것이므로 0을 출력!
🤫solution_2581
M, N = int(input()), int(input())
num = []
for i in range(N-M+1):
num.append(i+M)
dec = []
for i in num:
cnt = 0
for j in range(1, i+1):
if i % j == 0:
cnt += 1
if cnt == 2:
dec.append(i)
if len(dec) == 0:
print(-1)
else:
print(sum(dec))
print(min(dec))
🧐 백준 1929 (에라토스테네스의 체) _ 앞으로 계속 이 문제에서 파생하여 문항을 해결함
🤫해결의 실마리
🤔 에라토스테네스의 체 (Sieve of Eratosthenes)
에라토스테네스의 체 원리는 다음과 같다. 1. 소수가 아닌 1을 지운다. 2. 2의 배수를 지운다. 3. 앞서 지운 2의 배수가 아닌 것들 중 최소값인 3의 배수를 지운다. 4. 앞서 지운 2, 3의 배수가 아닌 값들 중 최소값인 5의 배수를 지운다. 5. 이 과정을 반복하여 걸러지는 것들이 비로소 소수가 된다. https://en.wikipedia.org/wiki/Sieve_of_Eratosthenes 이러한 에라토스테네스의 체는 "특정 구간이 주어졌을 때" 매우 빠르게 소수를 도출할 수 있다. 위의 2581번처럼 풀면 시간복잡도는 O(n)으로 비교적 시간이 오래 걸린다. 하지만 에라토스테네스의 체의 시간복잡도는 O(nlog(log n))으로 매우 빠르게 도출이 가능하다. 또한 약수의 경우, 2*4, 4*2 처럼 반복이 되기 때문에 가장 중요한 것은 범위의 마지막 수의 루트 값까지만 반복함으로 시간을 더욱 줄일 수 있다!
🤔Algorithm 과정 알고리즘과정은 위에서 설명하는 에라토스테네스의 방식을 차용하였다. 또한 코드에 대한 설명은 아래 그림으로 대체하겠다.
🤫solution_1929
m, n = map(int, input().split())
num = [i for i in range(max(2, m), n+1)] # m ~ n사이 숫자를 넣은 리스트 (단, 1은 제외)
dec_sqr_n = [] # n의 제곱근까지의 범위안에서 소수를 집어 넣을 리스트
for i in range(2, int(n**0.5) + 1): # 2에서 n의 제곱근까지만 반복
if i in num:
dec_sqr_n.append(i)
num = [j for j in num if j % i != 0]
print(*(dec_sqr_n + num), sep = "\n")
🧐 백준 4948 (에라토스테네스의 체)
🤫해결의 실마리
🤔에라토스테네스의 체(Sieve of Eratosthenes) 🤔Algorithm 과정 위 1929와 거의 동일한 방식으로 풀었지만 방법은 다음과 같다. 1. n의 범위 사이의 자연수를 저장하는 num 리스트를 생성한다. (1 ≤ n ≤ 123456) 2. 리스트 num을 1929번 풀이처럼 소수만 존재하도록 만들어준다. 3. 1929와 같은 방식으로 n의 범위사이에 존재하는 모든 소수가 담긴 decimal이라는 리스트를 생성해준다. 4. 0이 들어오기 전까지 while문을 이용해 입력을 받아주고 5. decimal 리스트에서 입력의 범위에 해당하는 값들의 개수를 세어 출력해준다.
🤫solution_4948 (시간초과)
def decimal(N):
n = N+1
num = [i for i in range(n, 2*N + 1)]
dec_half = []
for i in range(2, int((2*N)**0.5) + 1):
if i in num:
dec_half.append(i)
num = [j for j in num if j % i != 0]
return len(dec_half+num)
num = -1
while True:
num = int(input())
if num == 0:
break
else:
print(decimal(num))
처음 짠 코드로 1929와 비슷하게 함수를 생성하여 풀었으나 시간초과가 발생하였다. 시간복잡도를 염두하지 않고머리를 장식으로 두고 문제에 접근한 결과라 생각할 수 밖에 없다. 함수에서 2중 for문을 사용한 것을 while문에서 계속 받으니 그럴 수 밖에...
🤫solution_4948
from math import sqrt
# 1 <= n <= 123456 사이 자연수를 담은 리스트 생성
num = [i for i in range(2, 123456 * 2)]
# 리스트 num을 이전처럼 소수만 있게 만들어주기.
dec_half = []
for i in range(2, int(sqrt(123456*2)) + 1):
if i in num:
dec_half.append(i)
num = [j for j in num if j%i != 0]
decimal = dec_half + num
n = -1
while True:
n = int(input())
if n == 0:
break
# decimal 리스트에서 입력의 범위에 해당하는 값들의 개수를 세어 출력
print(len([i for i in decimal if n < i <= 2*n]))
🧐 백준 9020 (에라토스테네스의 체)
🤫해결의 실마리
🤔에라토스테네스의 체(Sieve of Eratosthenes) 🤔Algorithm 과정 두 소수의 차이가 가장 작은 것의 의미를 생각해보면 다음과 같다. 소수간의 차이가 작을수록 최대값의 절반과 가까워진다! 16으 예로 들자면 다음과 같다. [3, 13], [5, 11] => 3 5 (8) 11 13
따라서 핵심은 시간초과가 걸리지 않으려면 소수의 절반만 훑어야 한다.
🤫solution_9020 (시간초과)
T = int(input())
n = [int(input()) for _ in range(T)]
num = [i for i in range(2, 10001)]
dec_half = []
for i in range(2, 100 + 1):
if i in num:
dec_half.append(i)
num = [j for j in num if j % i != 0]
decimal = dec_half + num
for i in n:
dec = []
for j in range(len(decimal)):
for k in range(j, len(decimal)):
if i == decimal[j] + decimal[k]:
dec.append([decimal[j], decimal[k]])
print(*dec[-1])
처음 짠 코드로 문제점은 소수의 전체를 계속 훑으면서 비교를 진행하기 때문에 위의 알고리즘보다 2배 이상의 시간이 걸릴 가능성이 높다. 먼저 위의 코드를 짠 과정은 다음과 같다. 1. 먼저 범위에 해당하는 모든 소수를 담는 리스트를 생성하고 2. 그 리스트 안에서 두 소수간의 덧셈이 입력값과 동일한 것을 찾아서 dec이라는 리스트에 넣는다. 3. dec에는 [[3, 5]], [[3, 7], [5, 5]], [[3, 13], [5, 11]] 처럼 들어간 것이므로 4. 각 리스트의 마지막 인덱스에 해당하는 리스트가 차이가 가장 작은 소수 리스트인것. 이를 for문을 이용해 출력하였다.
🤫solution_9020
num = [i for i in range(2, 10000 + 1)]
dec_half = []
for i in range(2, 100 + 1):
if i in num:
dec_half.append(i)
num = [j for j in num if j%i != 0]
decimal = dec_half + num
T = int(input())
for i in range(T):
n = int(input())
n_half = n // 2
for j in range(n_half, 1, -1):
if j in decimal and n - j in decimal:
print(j, n - j)
break
🧐 Algorithm_왜 틀리는거지... 1. 소문자와 대문자의 구별을 없애기 위해 소문자를 대문자로 바꿔준다. 2. 알파벳을 총 25개이므로 각각의 알파벳의 개수를 세주기 위한 count배열 생성 3. count한 값이 2개 이상이라면(max와 동일한 count값이 있다면) ? 출력 4. 그게 아니라면 max값에 해당하는 index에 해당하는 알파벳 출력
1번.
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
string str;
getline(cin, str);
// 1. 소문자와 대문자의 구별을 없애야 함
for (int i = 0; i < str.length(); i++){
if (str[i] >= 'a' && str[i] <= 'z')
str[i] = str[i] - 'a' + 'A';
}
// 2. 알파벳은 총 25개(Z-A = 25)이므로 count를 위한 배열을 생성 및 초기화해줘야함
int count[26]; for (int i = 0; i < 26; i++) count[i] = 0;
for (int i = 0; i < str.length(); i++){
int idx_number = str[i] - 65;
count[idx_number]++;
}
char c;
int max = -1;
for (int i = 0; i < 26; i++){
if (count[i] == 0)
continue;
else if (count[i] > max){
max = count[i];
c = (char)(i + 65);
}
else if (count[i] == max){
c = '?';
}
}
cout << c;
}
2번.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
string str;
getline(cin, str);
// 1. 소문자와 대문자의 구별을 없애야 함
for (int i = 0; i < str.length(); i++){
if (str[i] >= 'a' && str[i] <= 'z')
str[i] = str[i] - 'a' + 'A';
}
// 2. 알파벳은 총 25개(Z-A = 25)이므로 count를 위한 배열을 생성 및 초기화해줘야함
vector<int> alpha_count(26); for (int i = 0; i < 26; i++) alpha_count[i] = 0;
for (int i = 0; i < 26; i++){
int idx_number = str[i] - 65;
alpha_count[idx_number]++;
}
int max = *max_element(alpha_count.begin(), alpha_count.end());
int cnt = count(alpha_count.begin(), alpha_count.end(), max);
int index = max_element(alpha_count.begin(), alpha_count.end()) - alpha_count.begin();
if (cnt >= 2)
cout << "?";
else if (cnt < 2)
cout << (char)(index + 65);
}
🧐 Algorithm_한줄에 입력을 모두 공백없이 받기 1. 먼저 공백없이 입력을 받아 저장하는 string 변수 str과 2. string을 char배열에 넣기 위한 작업을 진행한다. char c[str.length()+1] 이라는 배열을 생성해주고 이 배열에 str에 저장된 문자열을 집어넣어 주기 위해 copy함수를 사용해준다.
3. 그 후 char 형의 5를 int 형의 5로 바꿔줘야 하므로 다음과 같은 방법을 이용해 준다. 9 = '9'-'0' (= 57 - 48) 위와 같은 방법을 이용하면 c[i] - '0'은 해당 숫자와 동일한 값을 갖게 된다.
4. 이후 최종적으로 sum이라는 변수에 최종적인 값들의 합을 저장해주면 된다.
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int num; cin >> num;
string str; cin >> str;
int sum = 0;
char c[str.length() + 1];
str.copy(c, str.length() + 1);
int arr[str.length() + 1];
for (int i = 0; i < str.length(); i++) {
arr[i] = c[i] - '0';
}
for (int i = 0; i < str.length(); i++) {
sum += arr[i];
}
cout << sum;
}
🧐 Algorithm 1. 먼저 등차수열이어야 하므로 자리수간의 공차가 같아야 하기에 a-b와 b-c의 값이 동일해야함. 2. 이를 위해 함수 hansu를 만들었고 이를 100의자리수에서 사용. 3. 100~999까지 기준일 때 등차수열조건을 만족시켜야 하므로 다음과 같이 함수를 사용한다.
#include <iostream>
#include <algorithm>
using namespace std;
bool hansu (int num){
int a = num / 100;
int b = (num - a*100) / 10;
int c = num % 10;
return a-b == b-c;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int cnt = 0;
int num; cin >> num;
if (num <= 99){
cout << num;
}
else if (num >= 100 && num <= 999) {
for (int i = 100; i <= num; i++) {
cnt += hansu(i);
}
cout << cnt + 99;
}
else
cout << 144;
}
🧐 Algorithm _ 소수를 찾는 법 1. a % b == 2라는 식은 약수를 구하는 식이며 2. 이 약수의 개수를 세는 cnt라는 변수를 이용해 x의 약수개수를 구하고 3. 소수의 특징 (약수의 개수가 1과 자기자신)을 이용해 약수 개수가 2인 자연수 값들을 세준다.
#include <iostream>
using namespace std;
int main() {
ios_base::sync_with_stdio(0);
int num; cin >> num;
int count = 0;
for (int i = 0; i < num; i++) {
int cnt = 0;
int x; cin >> x;
for (int j = 1; j <= x; j++)
if (x % j == 0)
cnt++;
if (cnt == 2)
count++;
}
cout << count << endl;
return 0;
}
🧐 Algorithm _소수를 찾는 법 1. a % b == 2라는 식은 약수를 구하는 식이며 2. 이 약수의 개수를 세는 cnt라는 변수를 이용해 x의 약수개수를 구하고 3. 소수의 특징 (약수의 개수가 1과 자기자신)을 이용해 약수 개수가 2인 자연수 값들을 세준다.
이를 이용해 값들의 전체 합을 구해주고 가장 최소값은 작은 순서대로 vector에 넣어줬으므로 당연히 vector의 첫번째 원소에 들어있는 값이 최소값이 된다.
#include <iostream>
#include <vector>
using namespace std;
int main() {
ios_base::sync_with_stdio(0);
int M, N; cin >> M >> N;
int sum = 0;
vector<int> v;
for (int i = M; i <= N; i++) {
int cnt = 0;
for (int j = 1; j <= i; j++)
if (i % j == 0)
cnt++;
if (cnt == 2){
v.push_back(i);
sum += i;
}
}
if (v.size() == 0)
cout << -1 << endl;
else {
cout << sum << endl;
cout << v[0] << endl;
}
}
// 최대공약수
auto gcd(long long A, long long B){
if (B == 0)
return A;
else
return gcd(B, A%B);
}
// 최소공배수
auto lcm (long long A, long long B){
return A*B/gcd(A,B);
}
§my solution
#include <iostream>
#include <algorithm>
using namespace std;
// 최대공약수
auto gcd(long long A, long long B){
if (B == 0)
return A;
else
return gcd(B, A%B);
}
// 최소공배수
auto lcm (long long A, long long B){
return A*B/gcd(A,B);
}
int main(){
ios_base::sync_with_stdio(0);
cin.tie(0); cout.tie(0);
long long A, B; cin >> A >> B;
cout << lcm(A,B);
}
백만자리라는 문제를 안읽고 풀어서 틀렸다. lon long을 써줘야 함.
§my solution
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
auto gcd(long long a, long long b){
if (b == 0)
return a;
else
return gcd(b, a%b);
}
auto lcm(long long a, long long b){
return a*b / gcd(a, b);
}
int main(){
ios_base::sync_with_stdio(0);
cin.tie(0); cout.tie(0);
int num; cin >> num;
vector<long long> v1;
vector<long long> v2;
for (int i = 0; i < num; i++) {
int a, b; cin >> a >> b;
v1.push_back((a));
v2.push_back((b));
}
for (int i = 0; i < num; i++) {
cout << lcm(v1.at(i), v2.at(i)) << '\n';
}
}
1. 먼저 vector에 include 되어 있는 pair를 선언해 입력을 받으면 다음과 같다.
vector< pair<int, int> > p;
for (int i = 0; i < num; i++) {
int n1, n2; cin >> n1 >> n2;
p.push_back(make_pair(n1, n2));
}
2. 그 후 sort를 해줘야 하는데, 이때 문제는 sort를 해주면 p.first를 기준으로 정렬 된다는 것.
그래서 사용자가 만든 함수로 sort(v.begin(), v.end(), custom_func) 의 custom_func에 넣어서
p.second 기준으로 정렬되도록 해야한다. 이때, custom_func의 결과값은 0, 1이 나와야 하며 보통 bool type이다.
bool compare(pair<int, int> a, pair<int, int> b) {
if (a.second == b.second)
return a.first < b.first; // a.first가 작으면 true. 즉 작은게 앞에 배치가 된다.
return a.second < b.second; // a.second가 더 작으면 true. 즉 작은게 앞에 배치가 된다.
}
sort(p.begin(), p.end(), compare);
\
§my solution
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
bool compare(pair<int, int> a, pair<int, int> b) {
if (a.second == b.second)
return a.first < b.first; // a.first가 작으면 true. 즉 작은게 앞에 배치가 된다.
return a.second < b.second; // a.second가 더 작으면 true. 즉 작은게 앞에 배치가 된다.
}
int main() {
ios_base::sync_with_stdio(0);
int num; cin >> num;
vector< pair<int, int> > p;
for (int i = 0; i < num; i++) {
int n1, n2; cin >> n1 >> n2;
p.push_back(make_pair(n1, n2));
}
sort(p.begin(), p.end(), compare);
for (auto x:p) {
cout << x.first << " " << x.second << '\n';
}
}
size가 capacity를 넘으면 2배정도의 크기를 늘려 이동하는 방식으로 구현되어 있다.
§ reserve(N)
- vector의capacity를 N으로 설정하는 것.
- N이현재 capacity보다 클 때만 작동, 작으면 아무 일도 발생X
- N이 현재 capacity보다 크다면 모든 원소 reference와 iterator가 전부 무효화(invalidate)된다.
§ resize(N) / resize(N, value)
-size > N인 경우,원소의 개수를 줄인다.
-size < N인 경우, 입력된value가 없으면 default값인 0으로 할당한다.있다면 value로 할당.
그 후,size가 N이 되도록 늘린다.
§my solution
총 3가지 방식으로 해결하였다.
1. 배열과 배열의 포인터(주소값)로 sort 후 해결 (메모리 9708KB / 시간 636ms)
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int N, M; cin >> N >> M;
int arr[N+M];
for (int i = 0; i < N+M; i++) {
cin >> arr[i];
}
sort(arr, arr+N+M);
for (const auto& x:arr) {
cout << x << " ";
}
}
2. 배열을 벡터로만 바꿈 (메모리 9836KB / 시간 688ms)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int N, M; cin >> N >> M;
vector<int> v(N+M);
for (int i = 0; i < N+M; i++)
cin >> v[i];
sort(v.begin(), v.end());
for (int i = 0; i < N+M; i++) {
cout << v[i] << " ";
}
}
3. 정말 벡터 2개를 생성, 합친 후 정렬! (메모리 17656KB / 시간 644ms)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int N, M; cin >> N >> M;
vector<int> v1(N);
vector<int> v2(M);
for (int i = 0; i < v1.size(); i++){
cin >> v1[i];
}
for (int i = 0; i < v2.size(); i++){
cin >> v2[i];
}
vector<int> v3;
v3.reserve(v1.size() + v2.size());
v3.insert(v3.end(), v1.begin(), v1.end());
v3.insert(v3.end(), v2.begin(), v2.end());
sort(v3.begin(), v3.end());
for (const auto& x:v3) {
cout << x << " ";
}
}
4. 2개의 vector를 merge와 sort를 이용해 정렬(메모리 24684KB / 시간 544ms)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
vector<int> v1;
vector<int> v2;
int N, M; cin >> N >> M;
for (int i = 0; i < N; i++) {
int num; cin >> num;
v1.push_back(num);
}
for (int i = 0; i < M; i++) {
int num; cin >> num;
v2.push_back(num);
}
vector<int> v3;
merge(v1.begin(), v1.end(), v2.begin(), v2.end(), back_inserter(v3));
sort(v3.begin(), v3.end());
for (const auto& x:v3) {
cout << x << " ";
}
}