Sweep은 필히 2개의 단계(Initialize the Sweep, Run the Sweep Agent)가 필요하다.
1. Initialize the Sweep
∙ Sweep Configuration를 정의
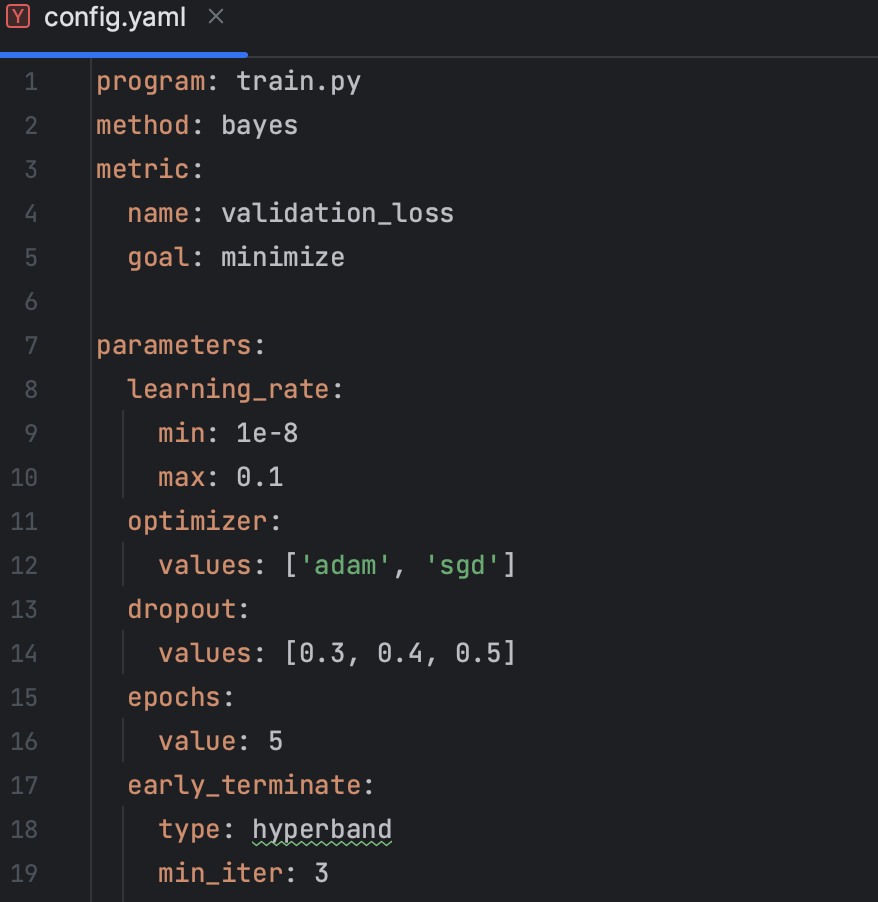
Sweep Initialize를 위해 먼저 구성요소(configuration)를 정의해야한다.
이를 위해 required와 option으로 나뉜다.
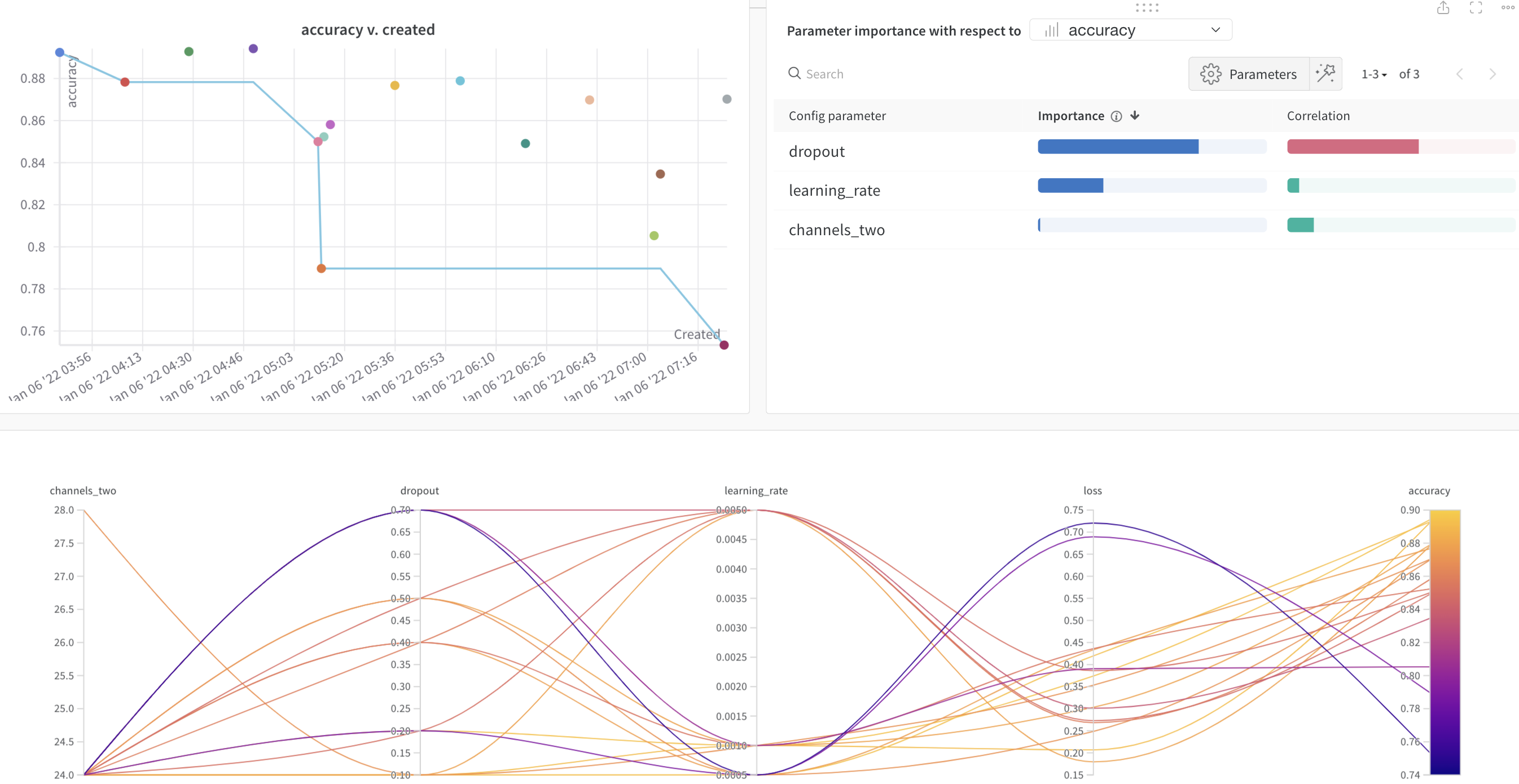
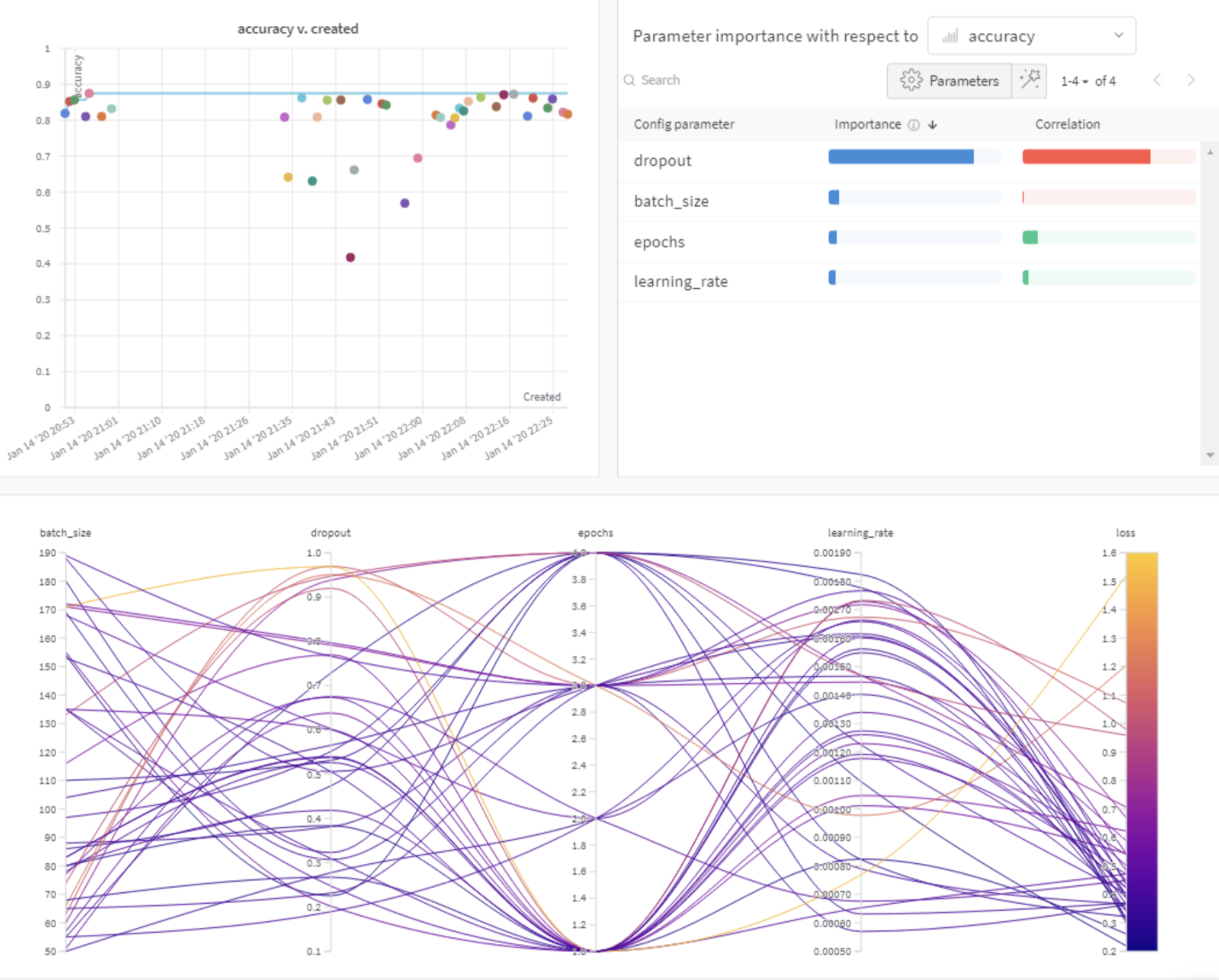
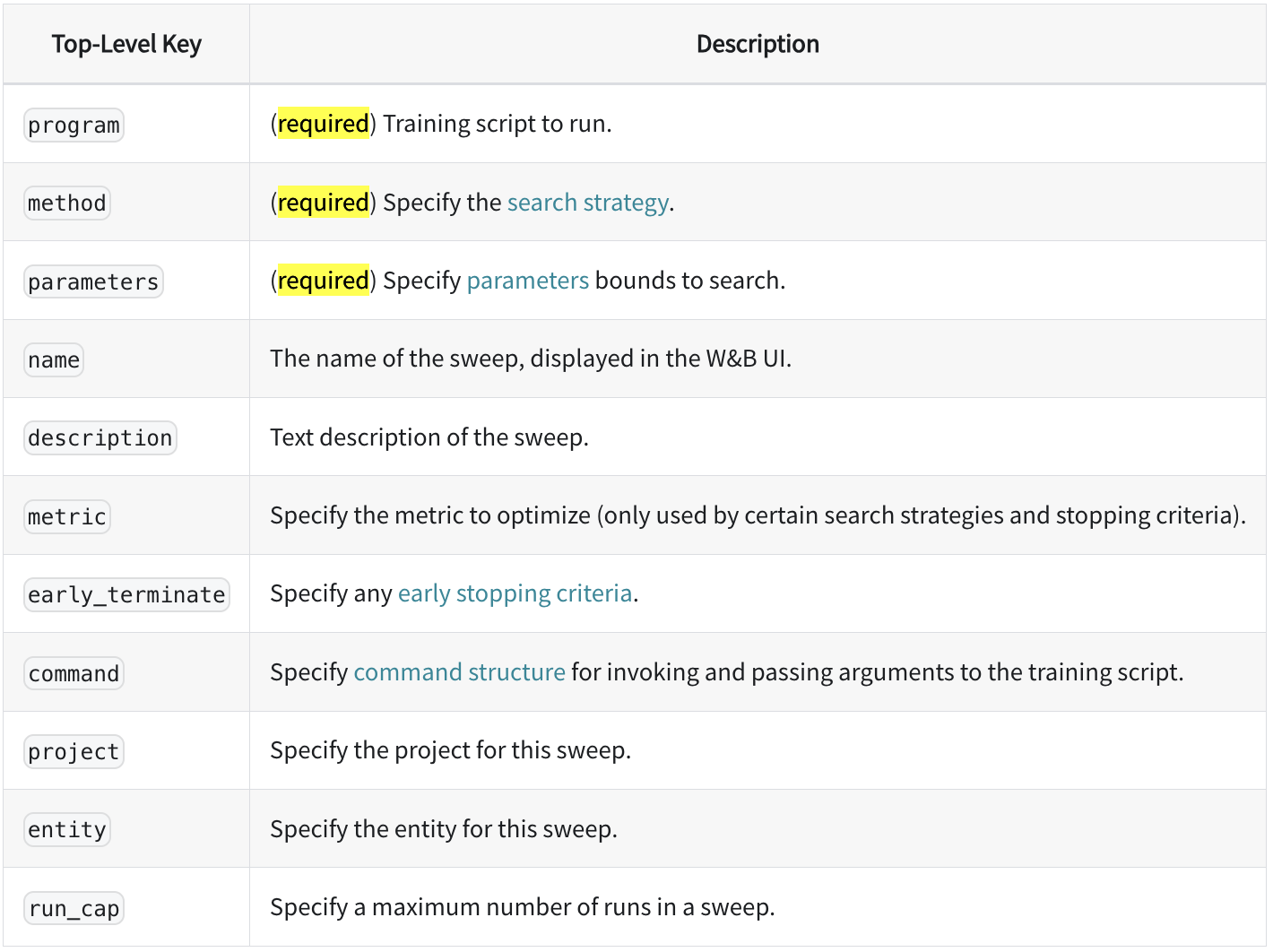
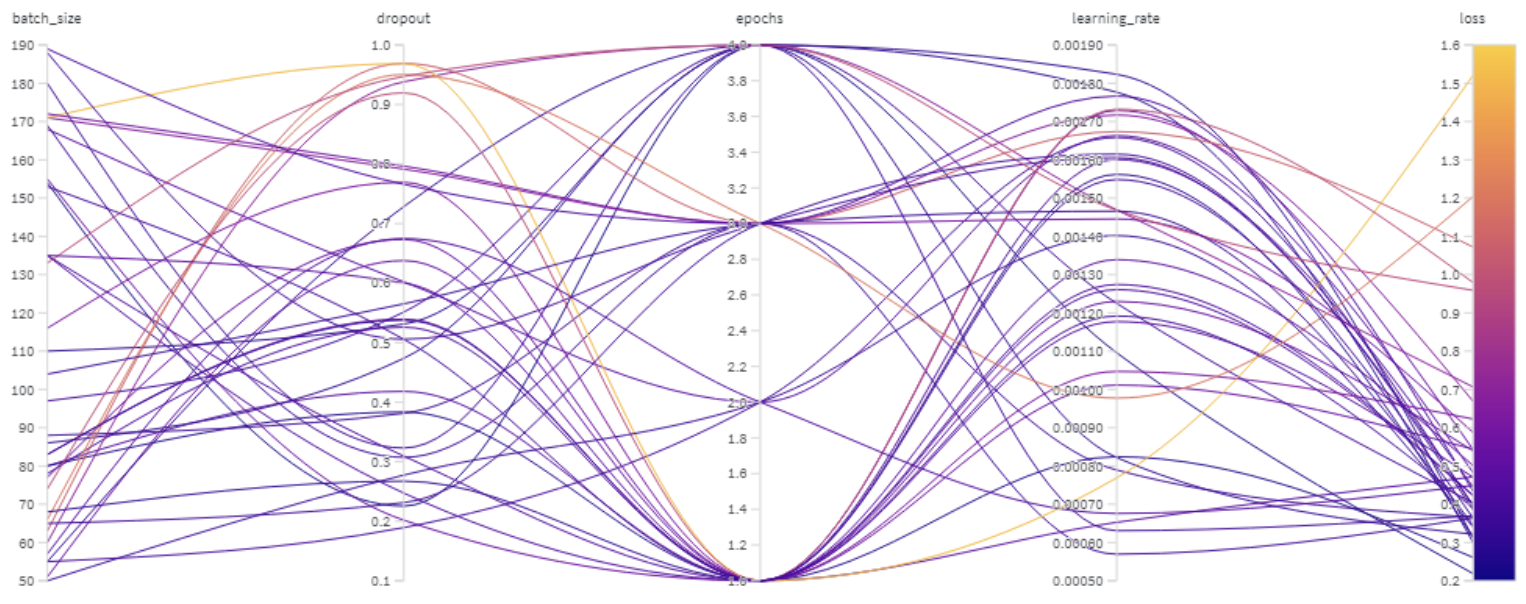
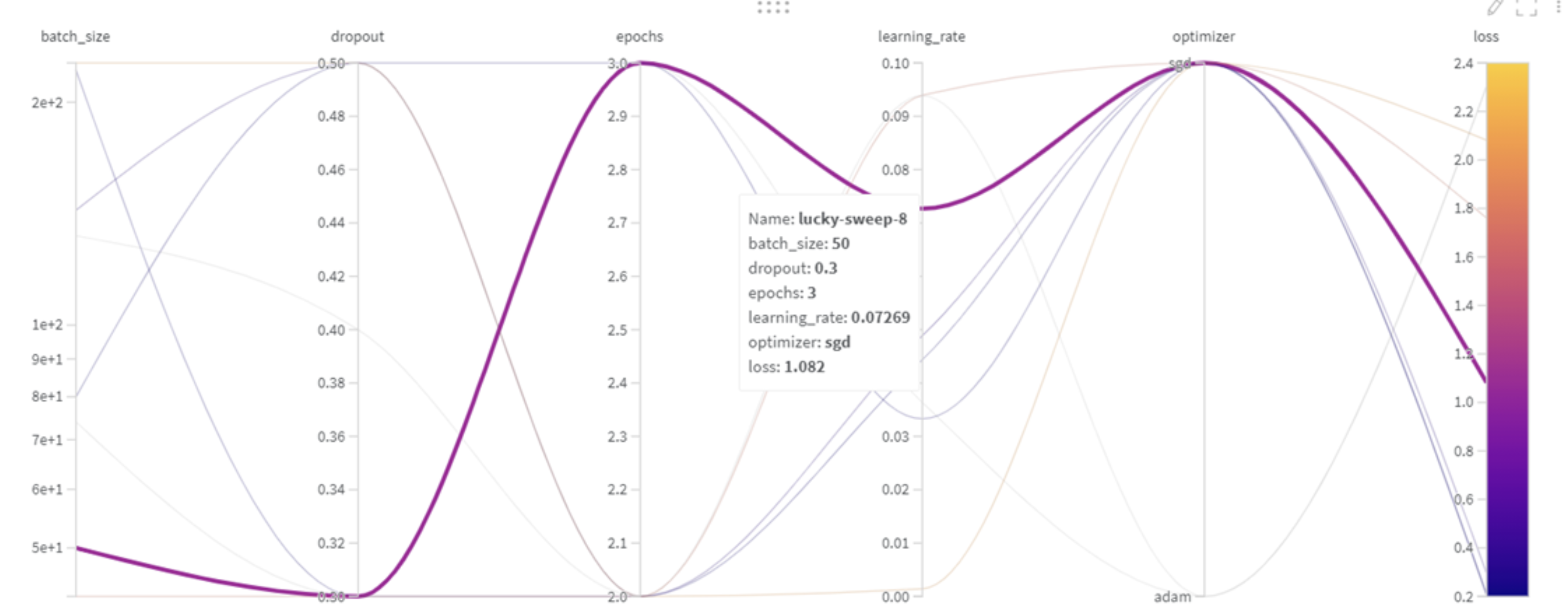
program(어디에서) method(무엇을) parameters(어떻게) 최적화를 할 것인지 정의해야한다.
이때, 최적화 방법으로 3가지가 존재한다.
Grid 방식 : 가능한 모든 조합 탐색 (= Cost↑)
Random 방식 : random하게 선택 (= Cost↓, opt찾을확률↓)
Bayes 방식 : 이전에 시도한 hyper-parameter조합의 결과를 사용, 다음시도조합 추론시 사용 → 모델성능을 최대로 향상시킬 수 있는 hyper-parameter조합을 찾는다. (= 초기탐색이 느림)
이때, 특히나 parameters 파트가 중요하기에 좀 더 살펴보자.
valuesvalue Hyper-parameter에 대해 특정 값을 설정해서 우리가 원하는 값만 선택하게 해줌. (value는 1가지 값을 설정해줄 때 사용) distribution values와 대조되는 방식. 특정 값을 설정하는 대신 원하는 분포 안에서 값을 선택. Sweep에서는 uniform, normal, q_log_uniform과 같이 다양한 분포를 제공. 또한 선택된 분포를 min, max와 mu, sigma, q를 통해 자유롭게 변형가능.
min, max 분포의 최소∙최대값을 설정. musigma 평균과 표준편차를 나타내는 값, 정규분포(normal)의 모양을 결정. q Quantization의 약자로 distribution에서 나온 값 X를 양자화. ex) q를 2로 설정한다면 X는 2의 배수로 바뀜. (ex. 식 round(X / q) *q를 적용하면, -2.96은 -2로 13.27은 14로 8.43은 8로 바뀜.)=
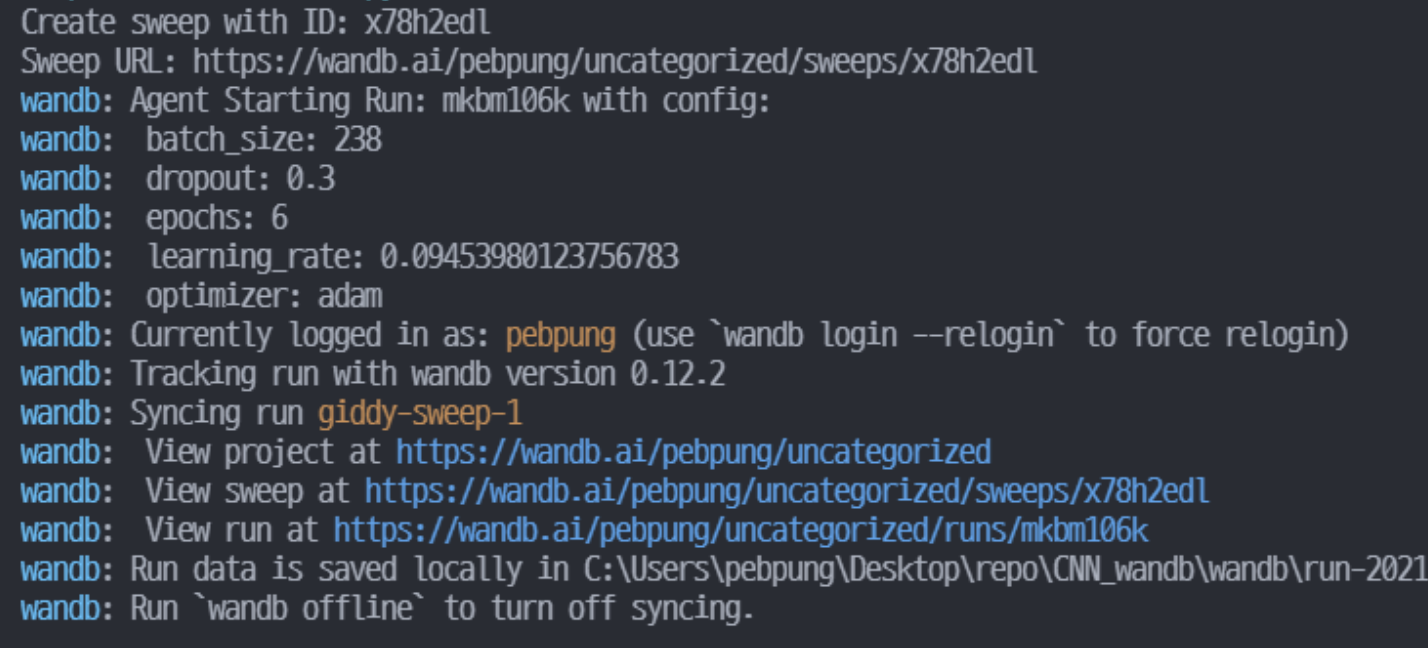
∙ project에 사용하기위해 Sweep API로 초기화
Sweep의 config가 제대로 정의가 됐다면 이제 프로젝트에 적용을 해줘야한다.
sweep 초기화 코드:
sweep_id = wandb.sweep(config.sweep_config)
위에서 정의된 config 변수를 입력으로 받고 sweep id를 출력해준다.
이 id는 다음 step에서 sweep을 실행시킬 때 고유한 identifier로 사용된다.