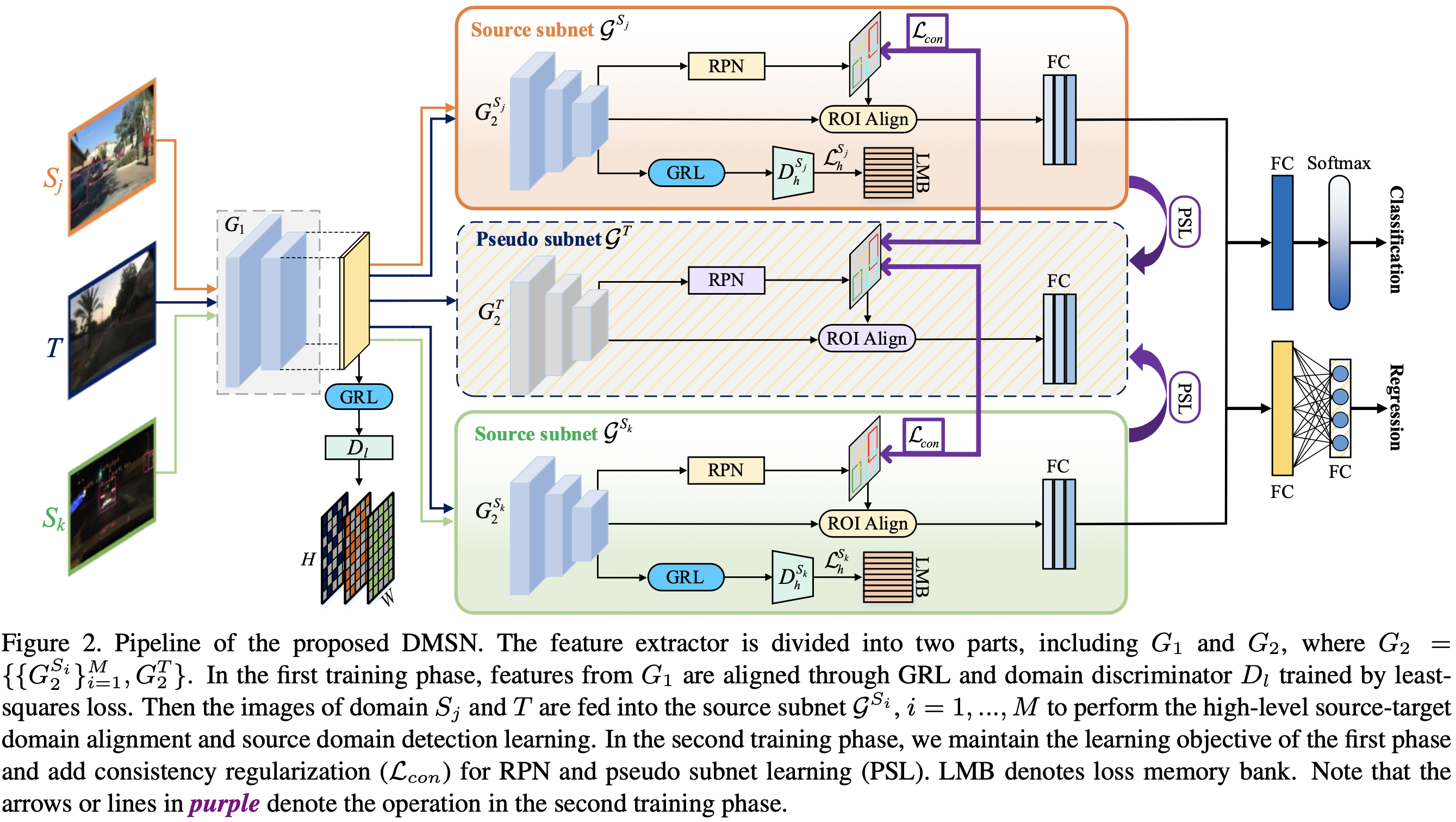
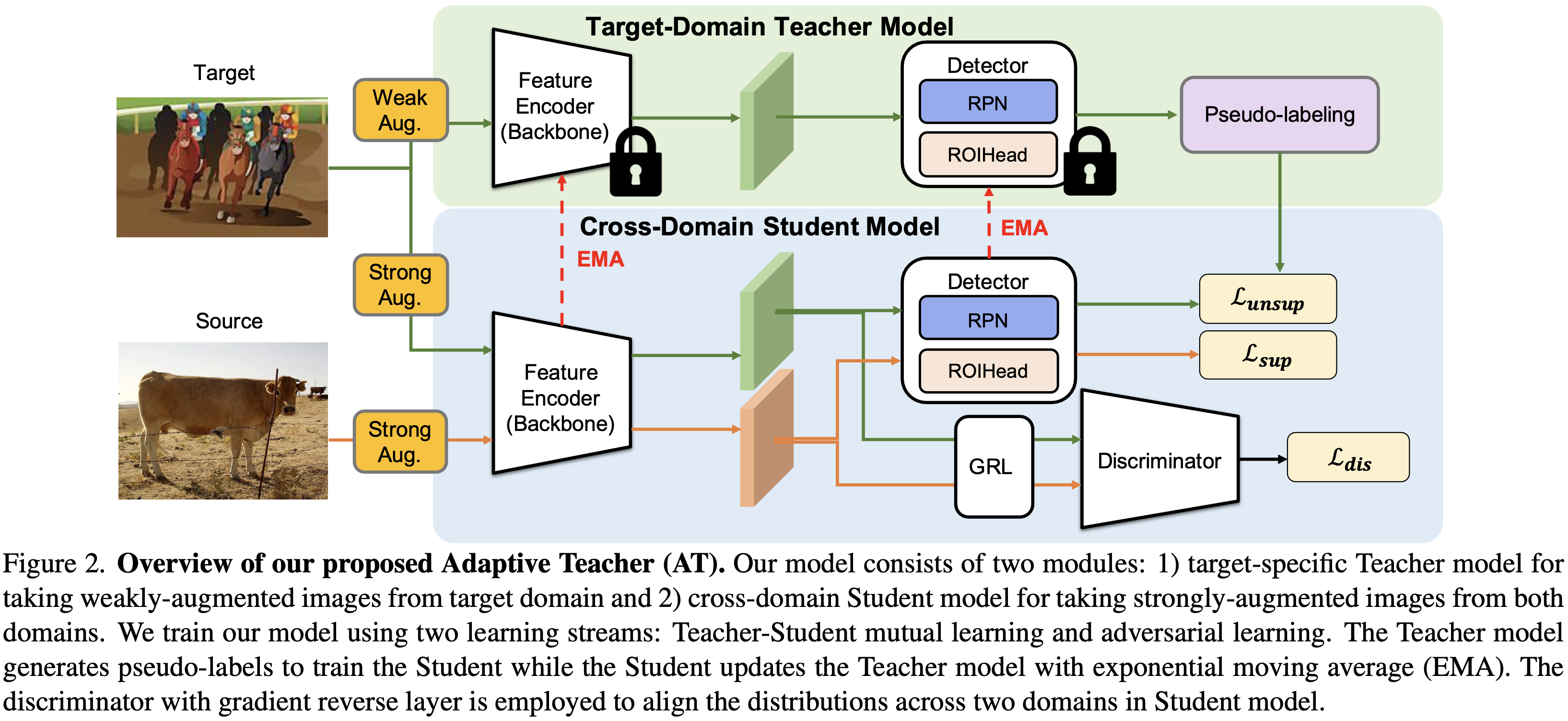
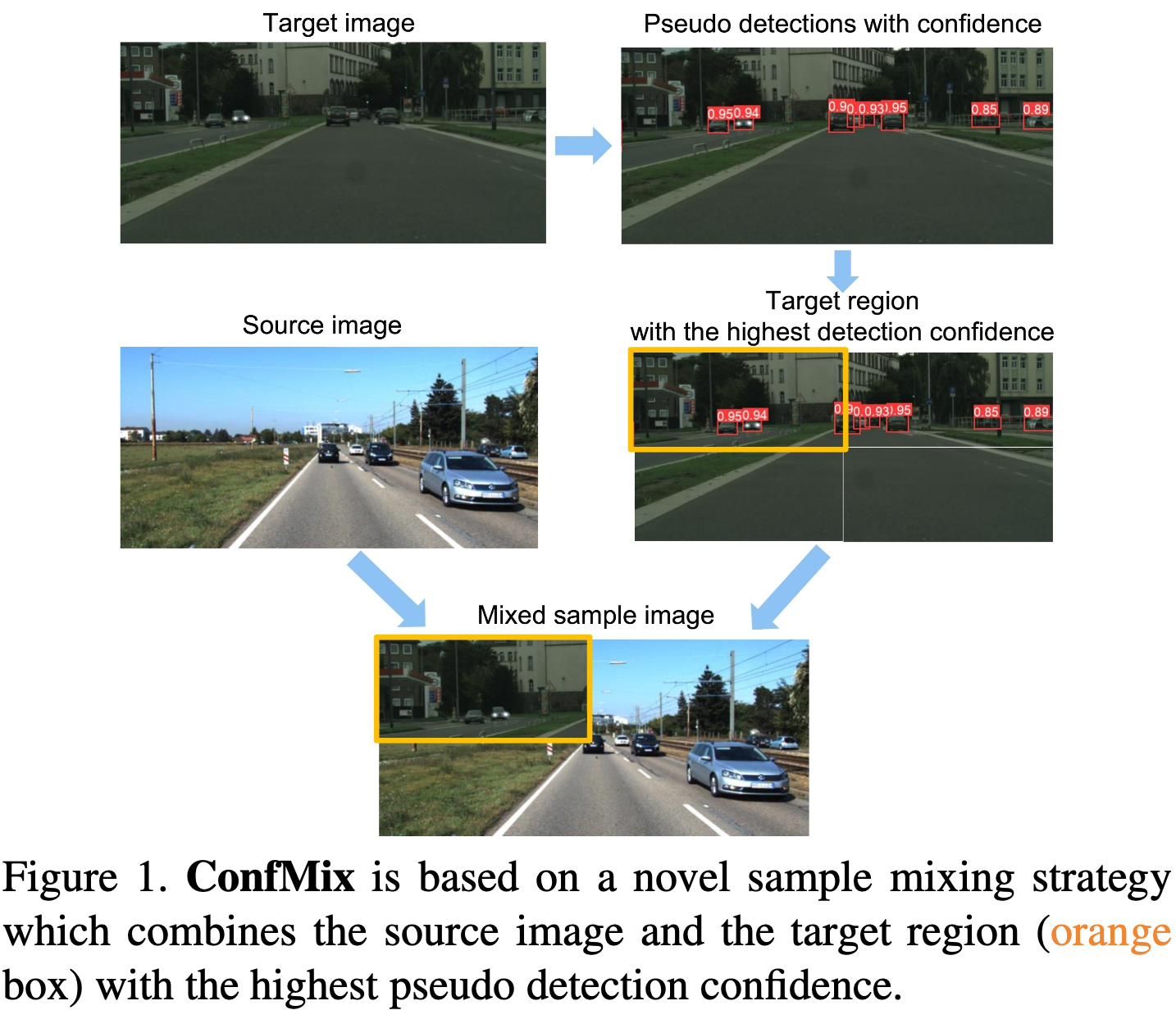
일반적으로 Detection시, trainingset과 testset이 동일한 분포일 것이라 가정. 즉, 분포가 달라지면 성능이 떨어질 수 밖에 없음
🧐 저자의 제안:
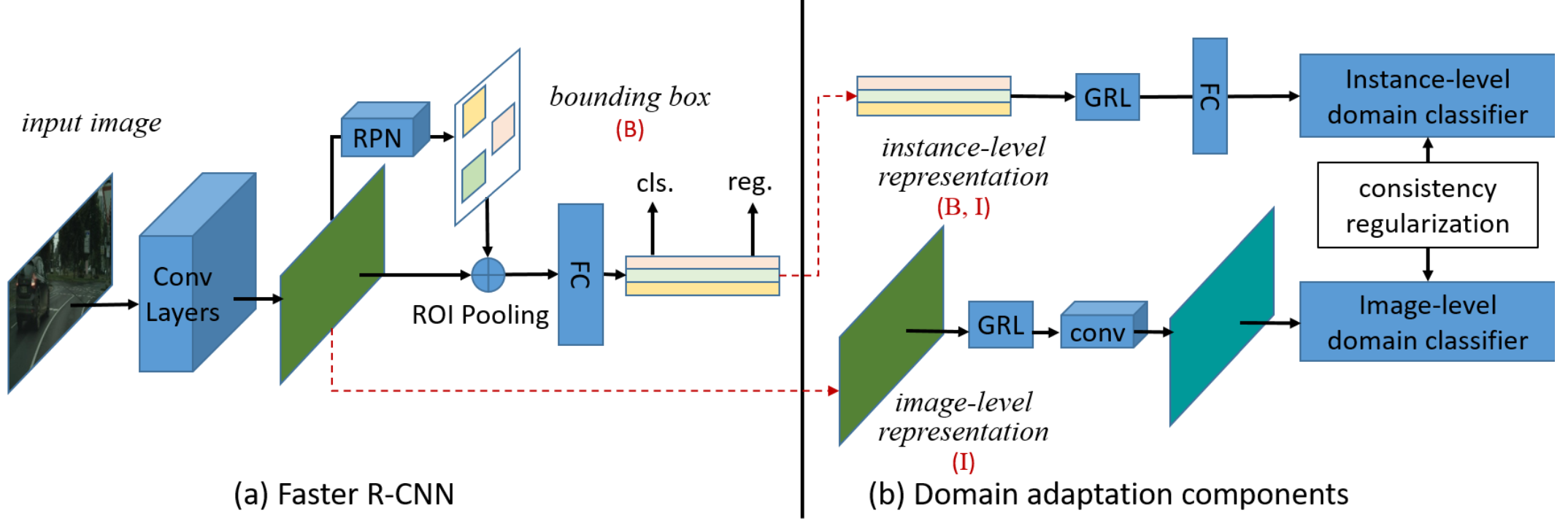
Detection에서 cross-domain 강화에 초점. → 2개의 Domain Shift를 다룬다. i) Img수준의 변화 --ex) style, 조명 등 ii) Instance수준의 변화 --ex) 객체외관, 크기 등
SOTA인 Faster R-CNN을 사용,
위에서 말한 2개의 DAC(Domain Adaptation Component)를 삽입해 Domain불일치를 감소시킴
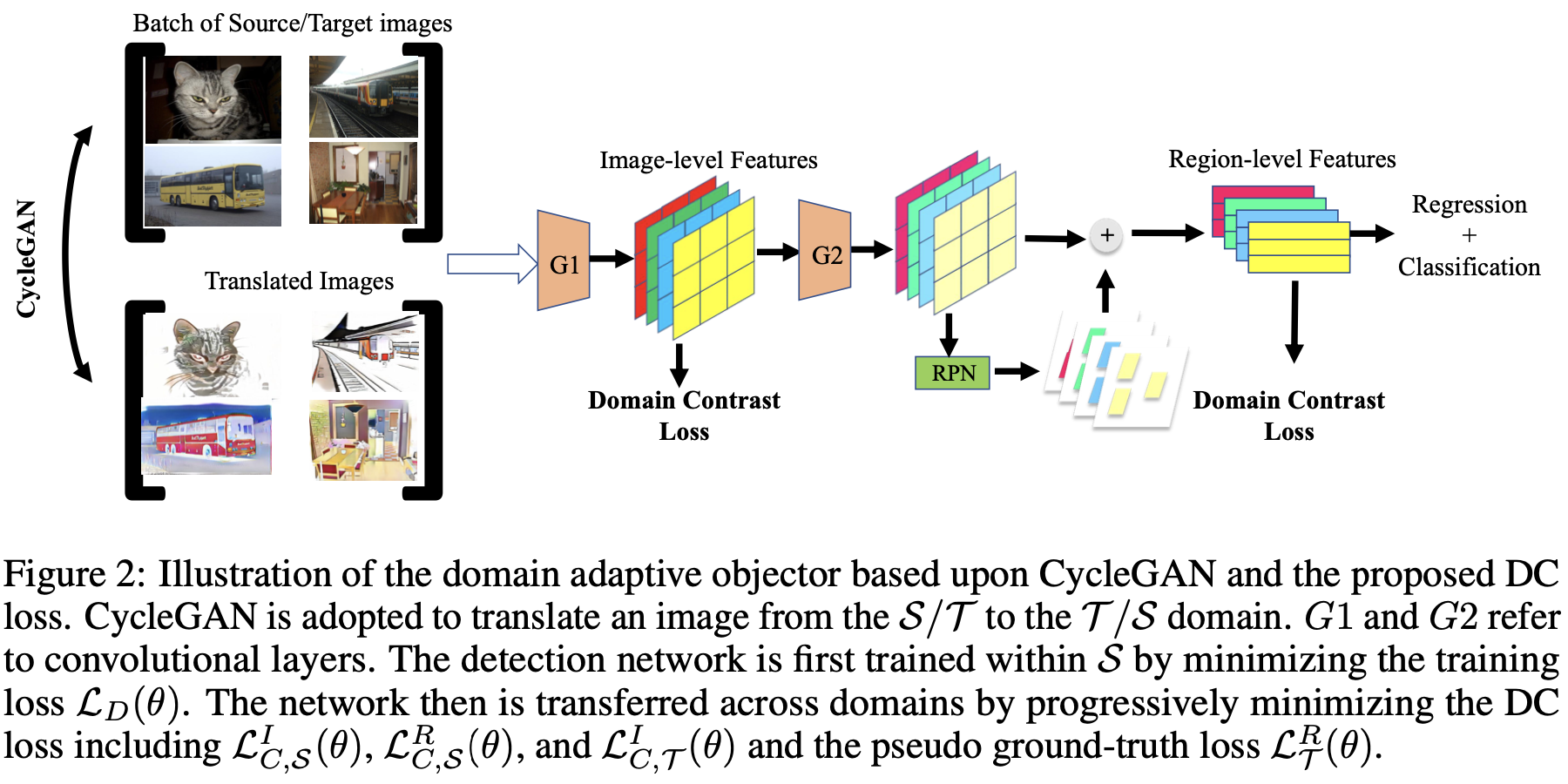
2개의 DAC의 경우, H-Divergence이론에 기반, 적대적 훈련방식으로 Domain Classifier를 학습해 구현. (To address the domain shift, we incorporate two do- main adaptation components on image level and instance level into the Faster R-CNN model to minimize the H- divergence between two domains.)
서로다른 Domain Classifier는 일관성규제를 통해 강화되어 RPN학습에 사용
Dataset: Cityscapes, KITTI, SIM10K 등
∙Image-level. vs. Instance-level Alignment
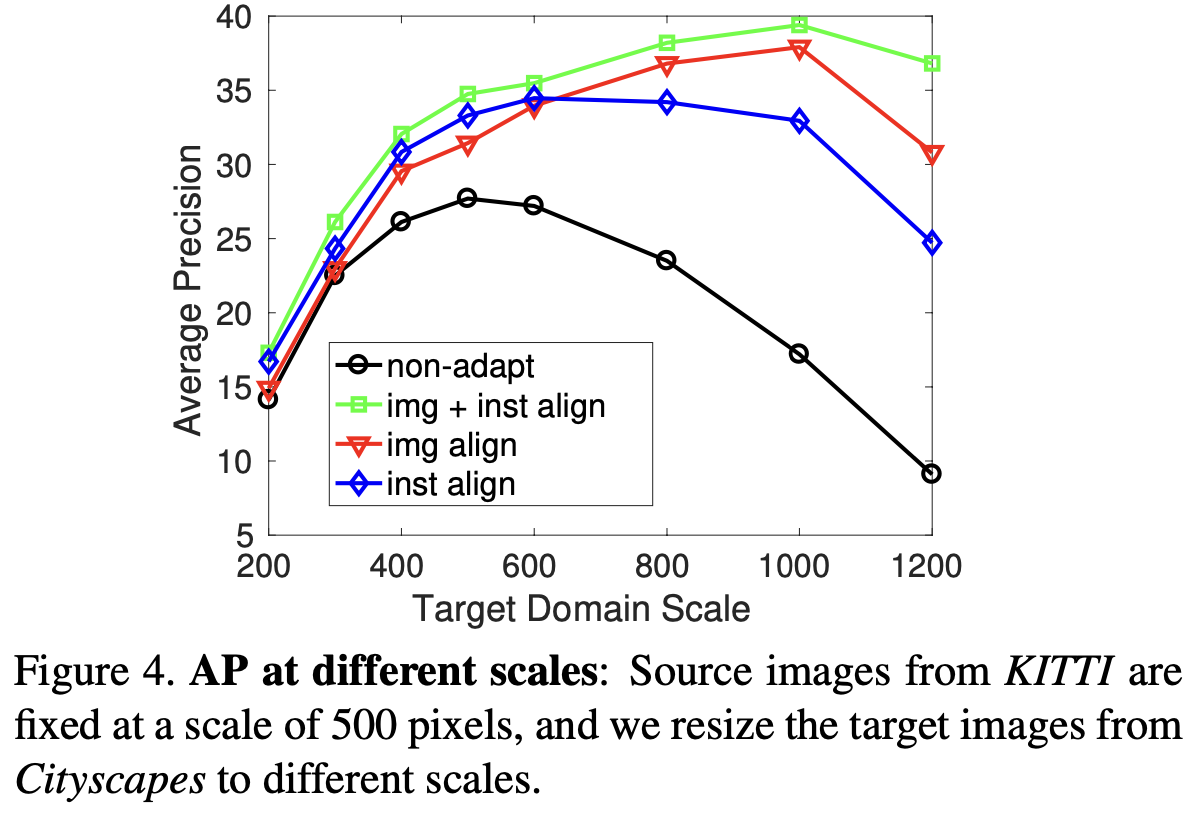
이미지 수준과 인스턴스 수준 Adaptation의 영향을 더 자세히 분석하기 위해 KITTI → Cityscapes에서 scale변화실험 수행. Scale 변화 = 모든 인스턴스와 배경에 영향을 미치는 전역적인 변환
tgt img scale변화 → scale불일치 시 vanilla-Faster R-CNN(ex. non-adapt비적응)의 성능이 크게감소.
두 adaptation에 대해 scale변화에 대한 견고성: Imgae > Instance
저자의 설계: 전역 도메인 변화가 주로 Image-level의 조정으로 해결. Instance-level은 불일치를 최소화하기 위해 사용되며, 심각한 전역 도메인 변화가 발생할 때 Instance 제안의 위치 결정 오류가 증가하기 때문.
그럼에도 불구하고 두 방법을 모두 사용하는 것이 모든 스케일에서 최상의 결과를 얻습니다. cf) Scale이 증가할수록 성능↑
∙Conclusion
새로운 Domain에도 추가적인 Labeling한 Data없이 잘 탐지할 수 있음.
2가지 방식을 제안. i) Img수준의 Adaptation Component ii) Instance수준의 Adaptation Component
위의 Adaptation Component는 H-Divergence의 적대적훈련에 기반.
Consistency Regularizer는 추가적으로 Domain에 불변한 RPN을 학습하기 위해 적용됨.
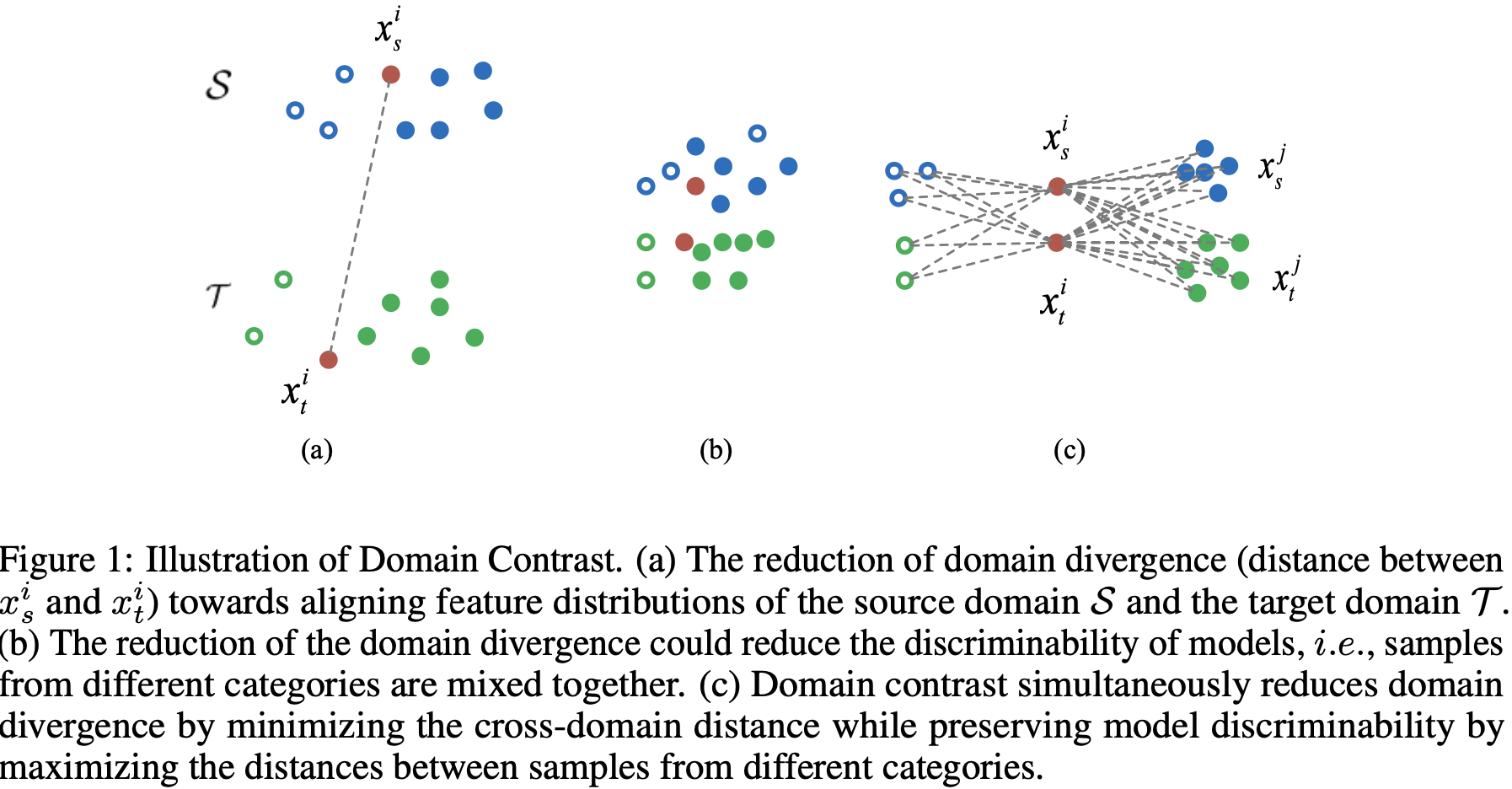
But❗️주변특성분포 조정만은 class조건부분포를 조정하는것까지 보장❌ → Domain Discrepancy를 더 크게만듬.
따라서 저자가 Instance-level Adapt를 위해 category-level semantic에 대한 Domain불변성을 학습하는 것을 목표로 한다. →기울기가 유사한 두 Domain이라면, 한 Domain만을 학습시킴으로써 다른 Domain의 학습을 향상시킬 수 있음을 의미.
🧐 저자의 제안:
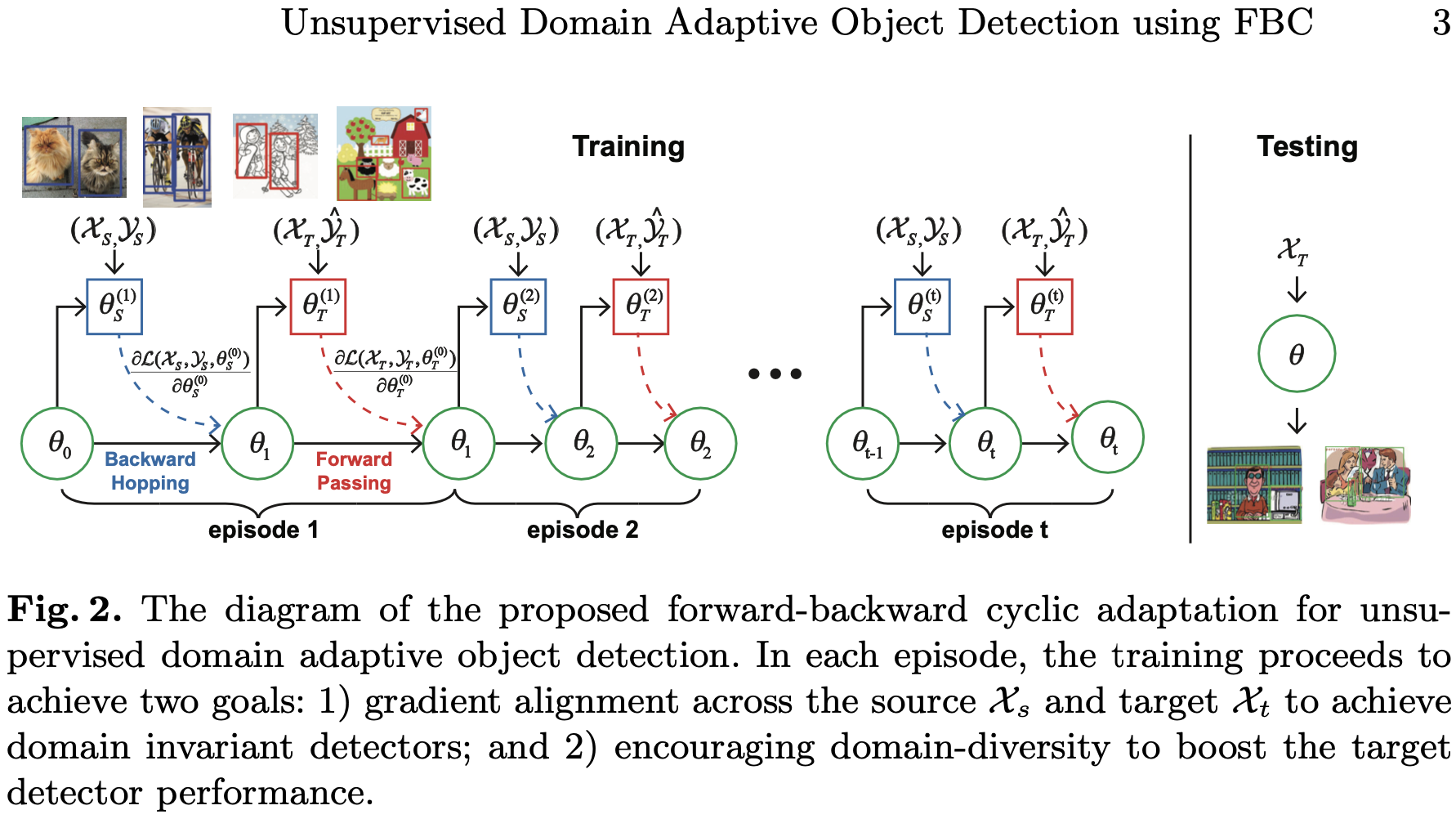
즉, Gradient조정을 위해 FBC Adaptation을 제안. ∙ Forward: Tgt→Src으로의 적응을 계산 ∙ Backward: Src→Tgt으로의 적응을 계산
이 과정을 반복적으로 수행.
Adversarial Training으로 Image-level 조정을 위해 Low-level feature를 강조.
다만, 두 도메인에서 잘 되더라도 Tgt에서 안될 수 있다. 이를 위해 2가지 Regularization방법을 도입, Domain다양성을 강조. i) Src에서 최대 Entropy규제로 확실한 Src-specific학습에 penalty ii) Tgt에서 최소 Entropy규제로 Tgt-specific학습을 유도.
∙Conclusion
Label이 없는 Tgt Domain문제(= Unsupervised Learning)에 대해 FBC라는 방법을 제시:
FBC: Gradient방향이 비슷한 Src와 Tgt에 대해 category수준 semantic의 Domain불변성을 학습할 수 있을 것이라는 직관에 기반. Adversarial Training을 통한 Local feature조정은 전체적인 Image-level의 Domain불변성학습을 위해 수행.
Entropy규제: 확실한 Source-specific학습에 penalty, Tgt-specific유도를 위해 Domain다양성을 제약.
UDA(Unsupervised Domain Adaptation)의 문제점: label이 있는 Src Data 필요. Unlabeled인 Tgt Data가 "많이"필요 또한, Classification에서만 UDA방법론들이 발전해왔었음.
🧐 저자의 제안:
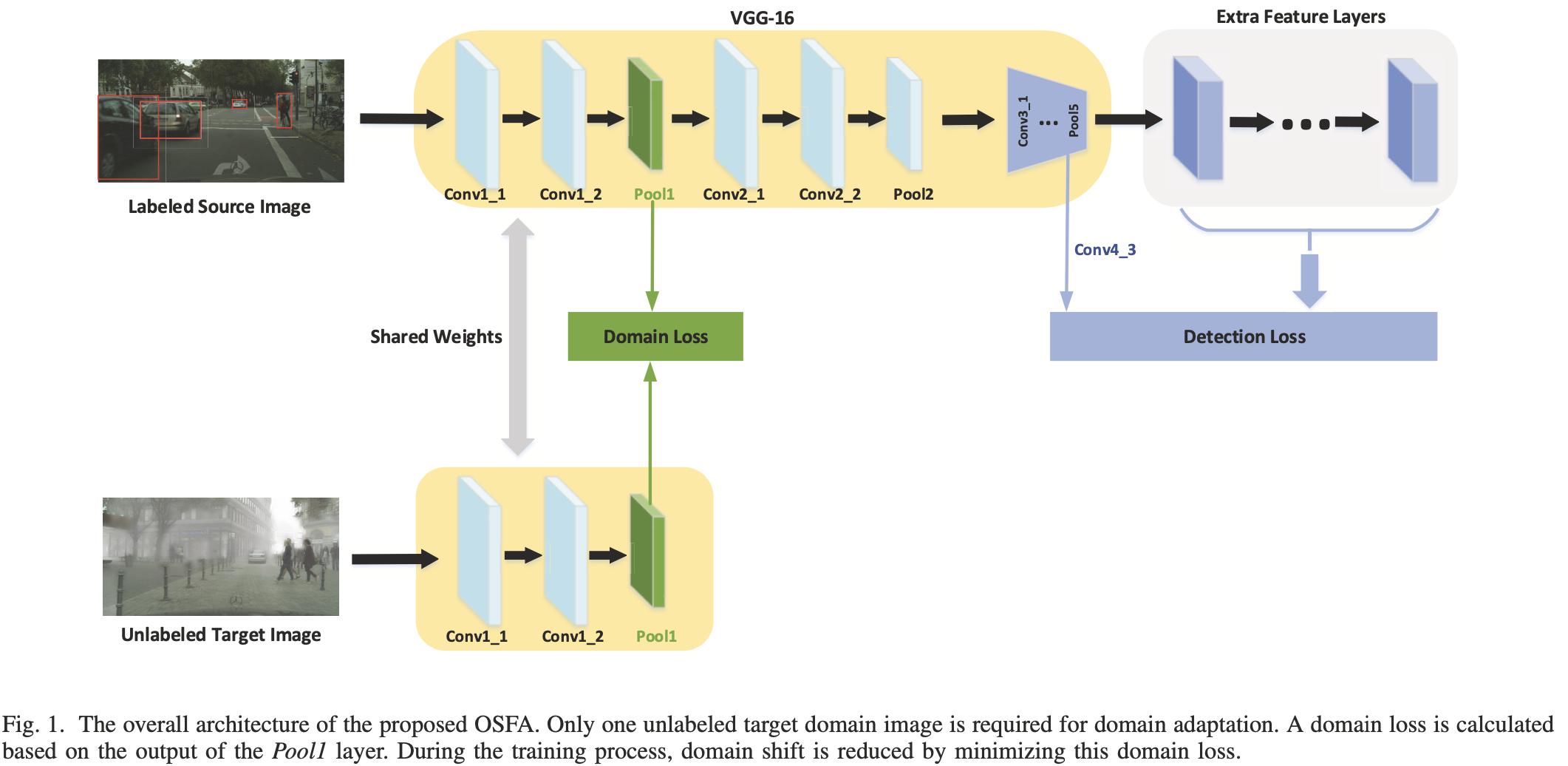
단지 1개의 Unlabeled Tgt sample만 있으면 됨. 이 OSFA(One-Shot Feature Alignment)알고리즘은 저수준의 Src, Tgt feature을 맞추기 위해 제안됨: 낮은 층의 CNN의 feature map의 평균활성화를 맞춰 Domain Shift를 줄인다.
위쪽)SSD // 아래쪽) Conv1_1, Conv1_2, Pool1 3개로 구성.
∙Conclusion
단지 하나의 Unlabeled Tgt sample만 필요. → 이를 위해 OSFA가 제안됨.
OSFA는 저차원의 Src,Tgt feature Domain을 맞추기 위해 제안된 알고리즘.
이 방법론은 Tgt sample선택에 상관없이 좋은 DA결과를 보이며, Domain Shift를 성공적으로 줄일 수 있었음.
annotation이 달린 Src와 annotation이 없는 Tgt간의 Domain Gap을 줄이기위해 DA를 다루며 유명한 Semi-Supervised학습법인 Teacher-Student프레임워크(teacher model이 만든 유사라벨로 지도학습)는 cross-domain에서 좋은 성능. 다만 아래 2가지 취약점이 존재. i) Domain Shift ii) 많은 저품질유사라벨 생성 (ex. FP)
🧐 저자의 제안:
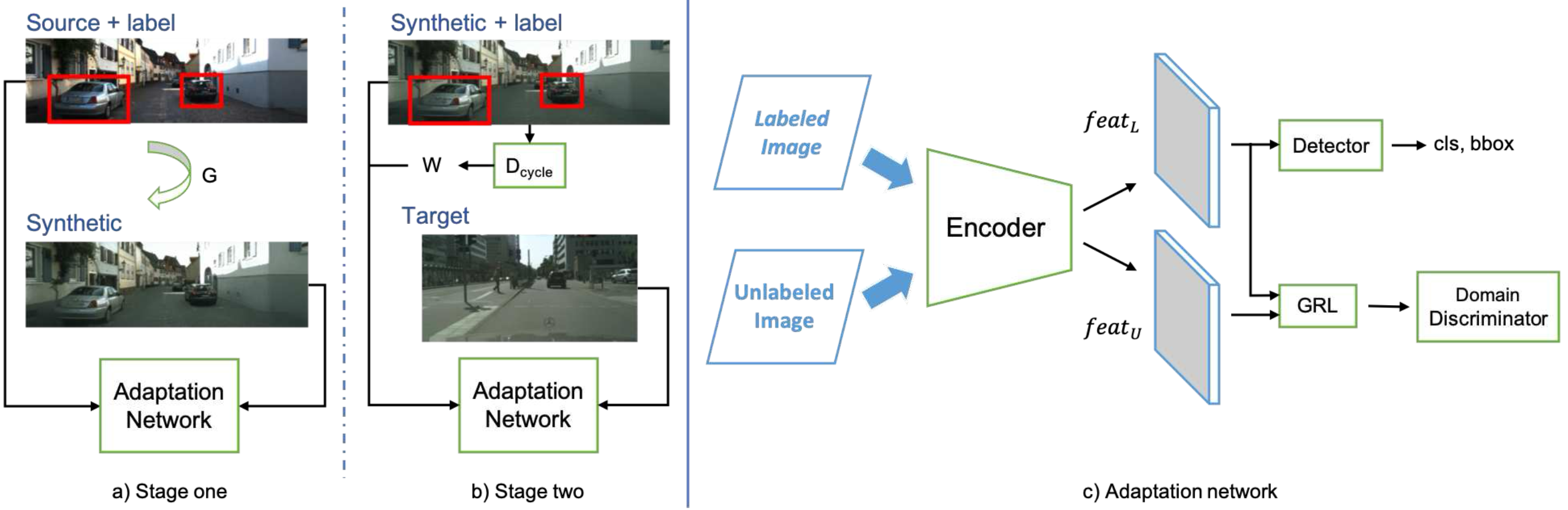
이 취약점완화를 위해 Adaptive Teacher; AT를 사용: ∙ Domain Adversarial Learning ∙ weak-strong Data Augmentation 를 사용하는 teacher-student framework
∙ Domain Adversarial Learning: student모델에서 feature-level 적대적훈련 → Src와 Tgt간의 유사한 분포를 공유하게함 → Student모델이 Domain불변성을 생성하게함
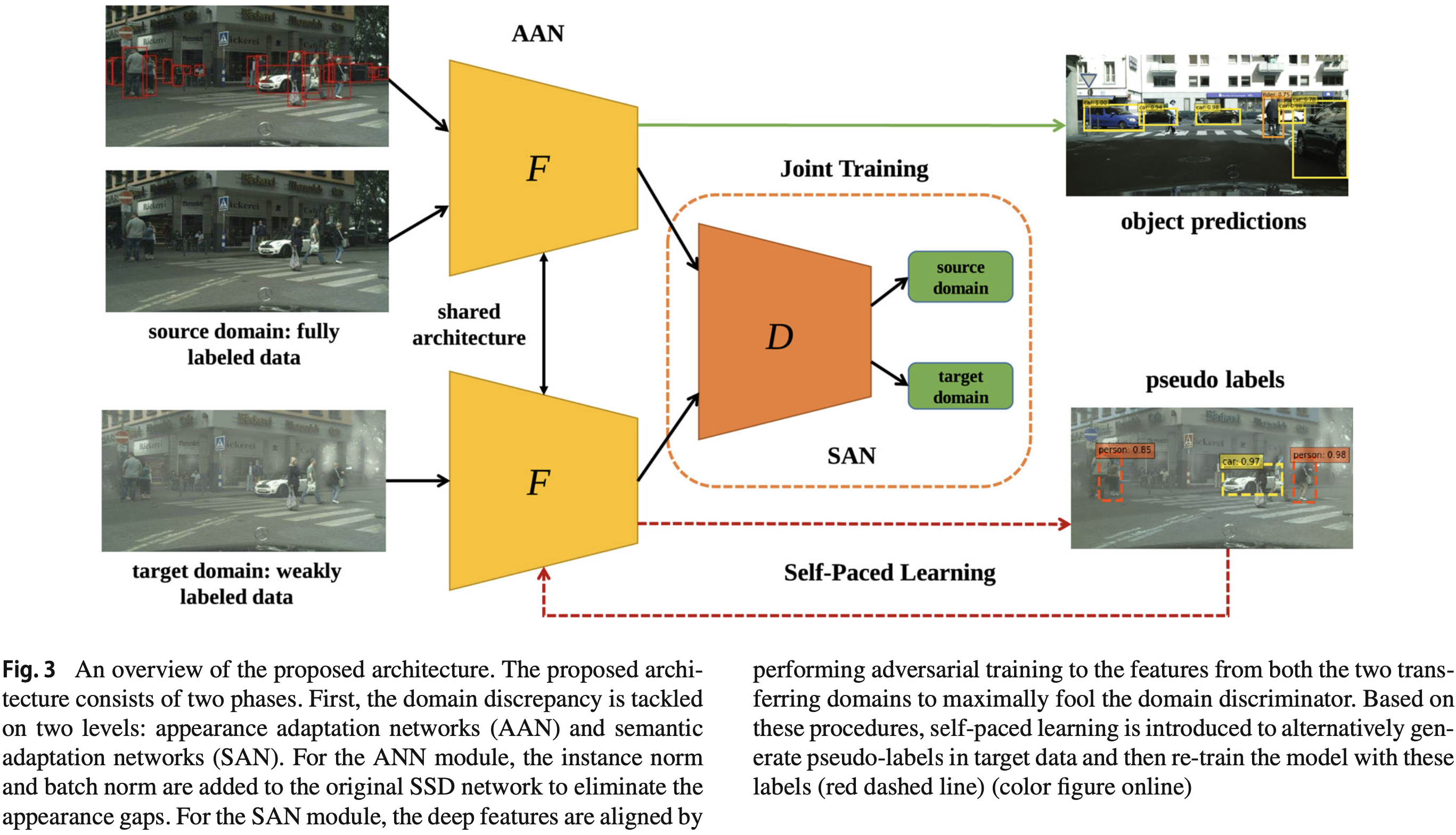
appearance & semantic level의 Domain Shift Adaptation을 위한 "Semi-supervised Detector"를 제안한다. 이를 위해 2가지 구성요소가 제안: ∙ instance와 batch normalization이 있는 Appearance 적응신경망 ∙ 판별기 손실 re-weighting하는 semantic 적응 신경망 (불균형한 scale의 두 Domain간의 feature alignment(정렬)향상)
Self-paced training: 쉬운 것부터 어려운 것까지 점진적으로 Tgt도메인에서 유사라벨을 생성
∙Conclusion
완전히 라벨링된 Domain → Image수준 라벨링만 있는 Domain으로 강건한 Detector를 설계.
특히, Src와 Tgt이미지 간의 Domain Shift문제를 Appearance & Semantic수준의 alignment로 해결했다.
또한 semantic level adapt과정 중 아래 2가지 문제가 발생. ∙ Scale불균형 ∙ Vanishing Problem. 이를 위해 standard adversarial 신경망이 개발, 어려운 클래스 샘플에 초점. 더불어, Self-paced학습법을 도입, 성능개선.