📌 WandB가 왜 필요할까?
1. Model Experiment Pipeline
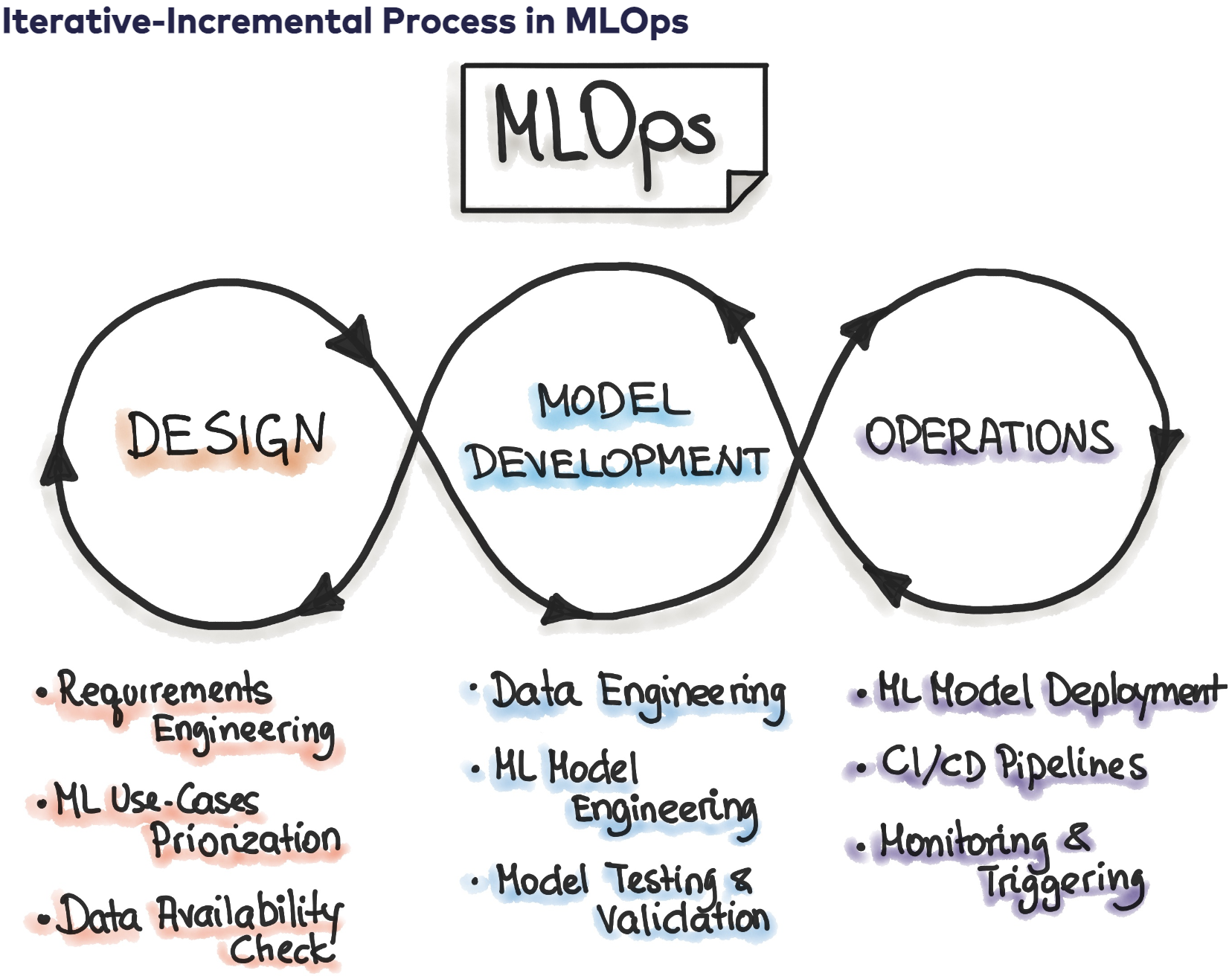
위 그림을 보면 알 수 있듯, MLOps과정은 크게 3단계로 나뉜다.
∙ Project Design
∙ Experiment & Development
∙ 배포 및 운영
이중, 2단계인 "실험에 도움을 주는 Tool"중 하나가 바로 WandB이다.
(cf. TensorBoard도 존재.)
2. Configuration
ML구축을 위한 필수구성요소로 대표적인 예시는 다음과 같다.
∙ Dataset
∙ Metric
∙ Model
∙ Hyper-parameter
Training과정에서, 이 Configuration값을 적절하게 선택해줘야한다.
🧐 Batch size에 대하여
Data나 Model의 종류에 따라 적절한 Batch_size가 존재하기에
batch_size를 너무 작은값이나 큰값을 쓰면 오히려 학습이 잘 안되는 경향이 존재한다.
cf) 특정한 가설하에 연역적으로 증명가능할 때,
batch size를 2배 증가시키면 step size는 √2배 증가시켜야한다.
cf) batch size를 증가시켰는데도 총 epoch수를 그대로 두면
한 epoch당 iteration수가 줄어들기에
그만큼 gradient로 parameter update를 덜 시키는 것이므로
Loss감소속도가 느려져 학습이 잘 안될 수도 있다.
그렇기에 적절한 Configuration설정은 준필수적이다.
특히, Dataset은 Data Augmentation
Metric은 추가하거나 교체하고, Model도 구조를 변경시키는 시간은 상대적으로 적은 시간이 들지만
Hyper-parameter Tuning의 경우 적절한 값을 찾기 위해서는 상당히 많은 시간을 할애해야한다.
Model의 parameter 최적화를 위해 Hyper-parameter를 적절히 조절해야하고, 이는 Hyper-parameter를 변경시키며 다양한 실험을 해야하기 때문이다.
이를 사람이 일일히 한다면?
즉, Hyper-parameter를 사람이 직접 일일히 tuning하는 작업은
매우 비효율적이고, 기록이 누락될수도 있고 이를 수기로 정리까지 해야하는,
종합고민3종세트라 할 수 있겠다.
📌 WandB?
WandB(Weights & Biases)는 더 최적화된 모델을 빠른시간내에 만들 수 있게 도와주는, ML Experiment Tracking Tool이다.
주요기능

W&B Platform
- Experiments: 머신러닝 모델 실험을 추적하기 위한 Dashboard 제공.
- Artifacts: Dataset version 관리와 Model version 관리.
- Tables: Data를 loging하여 W&B로 시각화하고 query하는 데 사용.
- Sweeps: Hyper-parameter를 자동으로 tuning하여 최적화 함.
- Reports: 실험을 document로 정리하여 collaborators와 공유.
📌 W&B Experiments. 함수 및 예제
모델학습 시, 모델 학습 log를 추적하여 Dashboard를 통해 시각화
이를 통해 학습이 잘 되고 있는지 빠르게 파악할 수 있다.
1. config setting
W&B실행을 위해 config파일이 필요하기에
Hyper-parameter, Data명 등 학습에 필요한 구성들을 그룹화한다.
또한, 이 config파일은 sweep에 중요하게 사용된다.
config = {
'dataset': 'MNIST',
'batch_size': 128,
'epochs': 5,
'architecture': 'CNN',
'classes':10,
'kernels': [16, 32],
'weight_decay': 0.0005,
'learning_rate': 1e-3,
'seed': 42
}
2. Dataset with DataLoader
def make_loader(batch_size, train=True):
full_dataset = datasets.MNIST(root='./data/MNIST', train=train, download=True, transform=transforms.ToTensor())
loader = DataLoader(dataset=full_dataset,
batch_size=batch_size,
shuffle=True, pin_memory=True, num_workers=2)
return loader
3. CNN Model
class ConvNet(nn.Module):
def __init__(self, kernels, classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, kernels[0], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, kernels[1], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * kernels[-1], classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out추가적으로 W&B는 모델의 weights와 bias같은 parameter를 추적할 수 있다.
이를 통해 학습 도중 weights의 histogram이나 distribution을 통해 원활한 학습방향수정이 가능하다.
4. Train 함수
def train(model, loader, criterion, optimizer, config):
wandb.watch(model, criterion, log="all", log_freq=10)
example_ct = 0
for epoch in tqdm(range(config.epochs)):
cumu_loss = 0
for images, labels in loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
cumu_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
example_ct += len(images)
avg_loss = cumu_loss / len(loader)
wandb.log({"loss": avg_loss}, step=epoch)
print(f"TRAIN: EPOCH {epoch + 1:04d} / {config.epochs:04d} | Epoch LOSS {avg_loss:.4f}")wandb.log()함수를 통해 loss함수를 시각화 할 수 있음.
이때, step을 epoch으로 받아 avg_loss값을 기록하는 것을 알 수 있다.
wandb.watch()는 Dashboard에서 실험 log를 시각화하는 역할을 수행.
5. Run 함수
def run(config=None):
wandb.init(project='MNIST', entity='계정명', config=config)
config = wandb.config
train_loader = make_loader(batch_size=config.batch_size, train=True)
test_loader = make_loader(batch_size=config.batch_size, train=False)
model = ConvNet(config.kernels, config.classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
train(model, train_loader, criterion, optimizer, config)
test(model, test_loader)
return modelwandb.int()으로 wandb web서버와 연결.
cf) project와 entity를 기입 가능한 곳
- config 설정 하는 파일 (config.py 혹은 config.yaml)
- wandb.sweep()
- wandb.init()
- wandb.agent()
6. 결과
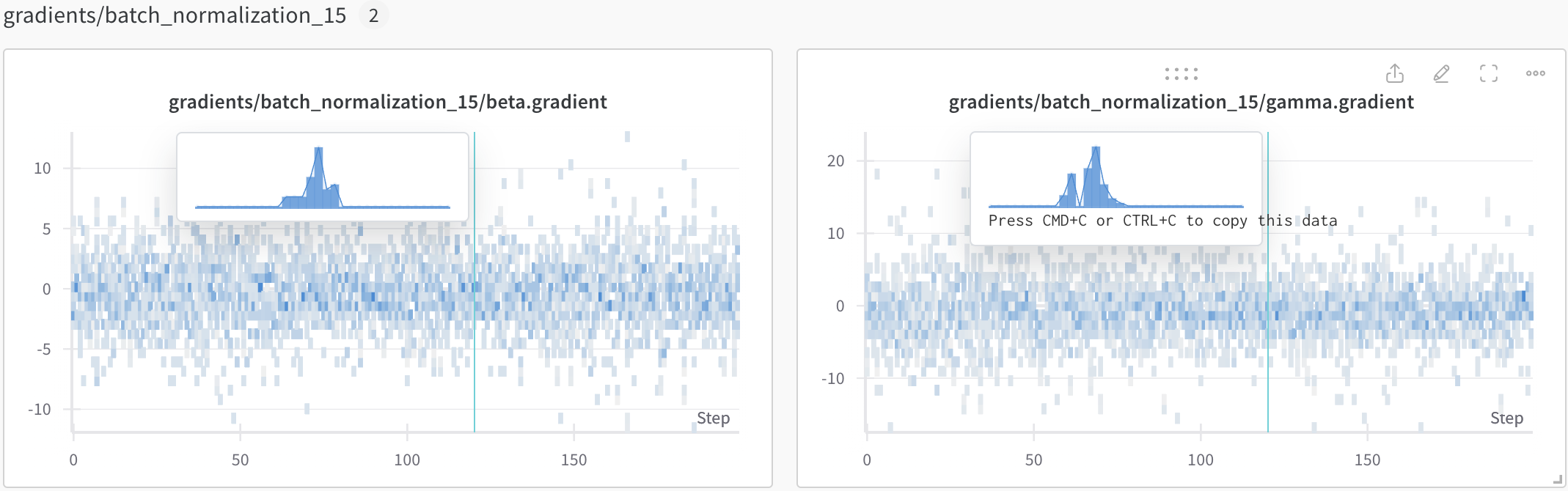
실험결과, 각 에폭마다 해당 Layer에 전파되는 Gradient값들을 확인할 수 있다.
추가적으로 해당 epoch에 대한 gradient distribution의 경우 마우스를 가져다 놓으면 위의 그림처럼 확인가능하다.
'Deep Learning : Vision System > Pytorch & MLOps' 카테고리의 다른 글
| [🔥PyTorch 2.2]: transformv2 , torch.compile (0) | 2024.01.31 |
|---|---|
| [WandB] Step 3. WandB 시각화 방법. (0) | 2024.01.09 |
| [WandB] Step 2. WandB Sweeps (2) | 2024.01.09 |