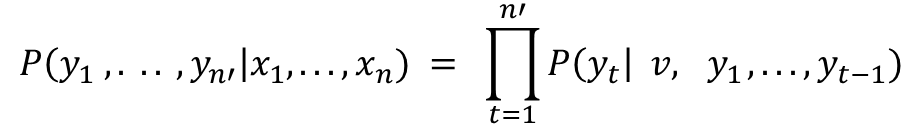🤫 NLP(Natural Language Processing)란? 컴퓨터의 언어가 아닌, 인간이 사용하는 언어를 처리하는 분야이다.
🤫 token? 그게 뭐지?? 글 ⊃ 문장 ⊃ 단어로 글은 이루어져 있는데, 단어는 글의 의미있는 부분 중 가장 작은단위이다. 이때, 문법적으로 가장 작은 단위를 토큰(token)이라 하며, 전체 글을 토큰으로 나누는 것을 토큰화(tokenization)라한다.
이렇게 토큰화를 이용하면 기본적인 분석이 가능한데, 예를들어 어떤 토큰이 자주 사용되는지를 알 수 있는데, 이를 워드 카운트(word_counts)라 한다.
🧐 단어를 벡터로 변환
🤫 token을 벡터로 변환?? token을 벡터로 표현하는 방법의 하나는 one-hot encoding인데, 이에 대해 아래 코드로 살펴보자.
🧐 단어 임베딩 (embedding)
🤫 token을 벡터로 변환?? token을 벡터로 표현하는 one-hot encoding은 장점도 있지만 단점이 명확한 방법이다. 만약 단어 인덱스가 100,000개 존재한다면? → 하나의 단어를 표현하기 위해 100,001길이의 벡터가 필요하게 된다는 점!
따라서 단어 임베딩(Embedding)이라는 방법을 사용한다. 단어 임베딩은 단어 벡터의 길이를 사용자가 직접 지정할 수 있다는 장점이 있다. 즉, 인덱스 길이에 상관없이 사용자가 지정한 벡터의 길이로 모든 단어를 표현한다. 임베딩의 원리: '바꾸고'라는 단어를 임베딩하는 과정임베딩하려는 단어의 벡터를 준비하고 임베딩을 위한 행렬을 준비한다. [행: 임베딩할 단어의 개수 // 열: 임베딩 벡터의 크기]
위에서의 실습에서 벡터의 길이가 6이었지만, 아래는 해당 문장을 벡터의 길이가 3으로 지정해 임베딩하는 것을 보여주는 코드이다.
🧐 seq2seq model
기존의 딥러닝 - 기존의 딥러닝은 input과 output데이터의 차원이 고정된 벡터인 경우에만 사용 - 하지만 실제 문제들은 벡터의 길이가 사전에 알 수 없는 sequence로 표현되는 경우가 많음
🤫 seq2seq란? 입력값으로 sequence를 받고 출력값으로 다른 sequence를 출력하는 모형 입력 sequence와 출력 sequence를 맵핑하는 model으로 다음 2가지 경우가 존재 1. input sequence와 output sequence가 같은 경우 (input sequence의 길이정보가 필수적) 2. input sequence와 output sequence의 길이가 다른 경우 (targe예측을 위한 input sequence 전체가 요구됨)
🤫 seq2seq에 대한 개념적, 구조적 접근 개념적: RNN과 Auto-Encoder를 합친 형태 구조적: 2개의 RNN을 합친 형태 (특히 LSTM과 GRU를 자주 사용) 아래 예시를 통해 이해해 보자. 인코더 내부에서 1개의 step마다 한개의 LSTM모형이 존재하기에 결과적으로 여러 LSTM이 존재하고 큰 차원의 벡터를 입력받을 수 있다. 이때, 인코더는 입력시퀀스를 처리하고 은닉"상태(state)"를 return한다. 즉, encoder의 output은 버리고 오직 "상태"만 전달시키는데, 이때 인코딩 과정에서 입력데이터를 하나의 벡터로 압축하는 context vector를 진행한다. 인코딩 과정을 거친 은닉벡터를 입력받아 출력 시퀀스를 출력한다. 이때, 디코더는target sequence의 한 시점 이전 문자가 주어지면, 바로 다음 문자를 예측하도록 학습되며 중요한 점은 디코더는 인코더의 출력벡터인 context vector를 초기 벡터로 사용한다! 즉,target sequence를 같은 sequence로 변하게 학습하지만 한시점 미래로 offset을 하는, 교사강요(teacher forcing) 학습과정을 진행한다. ex) input sequence가 주어지면 디코더는 target값[..t]가 주어질 때, target값[t+1..]를 예측하도록 학습한다. 이를 통해 디코더는 어떤 문자를 생성할 것인지에 대한 정보를 구할 수 있다.
이때, <sos>는 start-of-string을, <eos>는 end-of-string을 의미한다.
🤫 seq2seq. Algorithm 1. input sequence를 context 벡터로 encoding, 출력 2. size가 1의 target sequence로 시작.(target sequence는 단지 start-of-string문자) 3. 다음 문자를 예측하기 위해 decoder에 상태벡터와 1-char target sequence를 넣는다. 4. 이러한 예측법으로 다음 문자를 sampling 5. 뽑힌 문자를 target sequence에 추가 6. 이러한 과정을 <eos>가 나오거나 문자 한계치에 도달할 때까지 반복
🤫 입력시퀀스 (x1, . . . , xn)을 입력받았을 때, 출력시퀀스(y1, . . ., yn')를 출력하는 모델에 대해 살펴보자. 입력시퀀스에 대한 출력시퀀스의 조건부확률 P(y1, . . ., yn' | x1, . . . , xn)를 추정해야 하는 것이 목적이므로 아래와 같은 식을 사용해 구할 수 있다. 위 식에서 v는 입력데이터 시퀀스 데이터 x가 인코더를 거친 후 출력되는 context vector를 의미하며 P(yt |v, y1, . . . ,yt-1)는 모든 가능한 출력 후보에 softmax함수를 적용한 값이다.
🧐 Attention
🤫 seq2seq보다 좀 더 발전시켜볼까? 이름처럼 주위에 신경을 기울인다는 뜻으로 출력단어를 예측하는 매 시점 encoder에서 전체 입력문장을 참고하는 방식. 앞서 배운 seq2seq(일명 바닐라 seq2seq)는 직전 벡터에 가장 큰 영향을 받아 시간이 지나면서 정보를 잃는 한계점이 존재 반면, attention은 모든 decoding과정마다 encoder내부의 모든 hidden layer를 참고한다. 이때, encoder의 은닉상태를 동등하게 참고하지 않고 출력단어와 연관이 있는 부분을 좀 더 집중(attention)해서 참고한다.
attention의 세부단계는 총 5단계를 거치는데, 다음과 같다. 1. 내적 - decoder의 은닉상태 벡터 · encodeer의 은닉상태 벡터 = 각각의 은닉상태 벡터에 대한 attention score 2. attention의 분포 구하기 - softmax함수를 이용해 분포를 구하며 확률분포이기에 모두 합하면 1이 된다. - 이때, 막대의 크기가 가장 큰 것이 How에 해당하는 attention score이기에 How와 연관이 크다는 것을 알 수 있다. 3. attention의 output구하기 - attention 분포 ⊙ encoder 은닉상태 = attention output. (원소곱 진행) 4. output layer의 input 구하기 - 출력층 입력 = attention output과 해당단계의 decoder 은닉상태를 이어붙인 후 w를 곱하고 b를 더해 activation 함수에 넣음 5. predict한 값 구하기 - 최종 예측값 = 4에서 구한 출력층 입력벡터에 w행렬을 곱하고 b를 더한 후 softmax를 사용
자연어(natural language)란 우리가 일상 생활에서 사용하는 언어로 자연어 처리(natural language processing)란 이러한 자연어의 의미를 분석하여 컴퓨터가 처리하는 것이다. 좀 더 구체화 시키면 입력(자연어)을 받아서 해당 입력이 특정 범주일 확률을 반환하는 확률함수이다. 이런 확률을 기반으로 후처리(post processing)을 해서 자연어형태로 바꿔줄 수 도 있다.
자연어 처리는 음성 인식, 내용 요약, 번역, 사용자의 감성 분석, 영화 평론의 긍정 및 부정, 텍스트 분류 작업(스팸 메일 분류, 뉴스 기사 카테고리 분류), 질의 응답 시스템, 챗봇과 같은 곳에서 사용되는 분야 등 다양하다.
이런 자연어 처리에 다양한 모델이 사용되고 요즘 가장 인기있는 모델은 단연, 딥러닝이다. 딥러닝 가운데서도 딥러닝 기반 자연어 처리 모델에는 BERT, GPT 등이 있다.
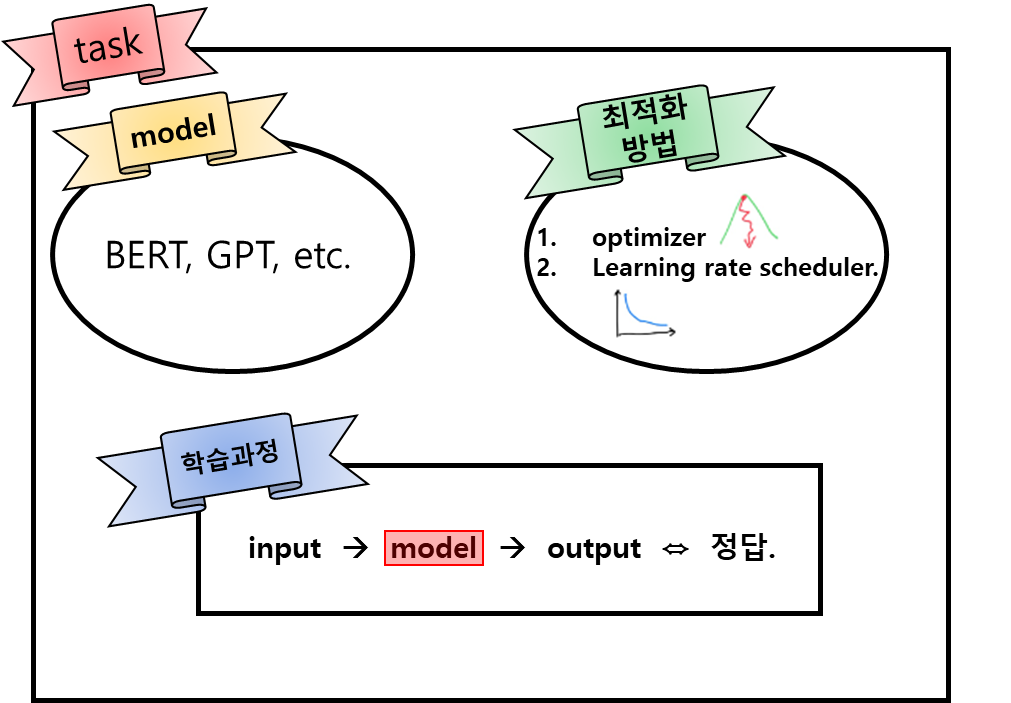
※ Task란?
- 준비한 모델, 최적화 방법 및 학습과정 등이 정의되어 있는 것. - 우리는 특정 조건에서 모델의 output과 정답의 차이를 작게하는게 중요, optimizer, learning rate scheduler를 정의.
모델 학습은 batch단위로 이뤄지는데, batch를 모델에 입력한 후 모델 출력을 정답과 비교해 차이를 계산한다. 그 후 차이를 최소화하는 방향으로 모델을 update하는데, 이런 일련의 과정을 step이라 하며 task의 학습과정은 1step을 기준으로 정의한다.
※ Transfer Learning
특정 data를 학습한 모델을 다른 data train을 할 때 재사용하는 방법
- 장점: 학습속도가 기존보다 빠르고 새로운 data를 더 잘 수행할 수 있어 BERT, GPT 등도 transfer learning이 적용된다.
§ Upstream Task - Transfer Learning이 주목된 것은 upstream task와 pretrain덕분으로 자연어의 다양한 context를 모델에 내재화하고 다양한 down stream task에 적용해 성능을 끌어올렸기 때문이다. 이는 기존의 지도학습과 달리 다량의 학습데이터를 웹문서, 뉴스 등의 쉽게 구할 수 있는 데이터와 이를 upstream task를 통해 수행하여 성능이 월등히 좋아졌다. 즉, 데이터 내에서 정답을 만들고 이를 통해 모델을 학습하는 자기지도학습(self-supervised learning)을 진행.
▶ Masked Language Model - 아래와 같이 빈칸에 들어가야할 단어에 대해 주변 문맥을 보고 해당 빈칸의 단어에 해당하는 확률은 높이고 나머지 단어들의 확률을 낮추는 방향으로 모델 전체를 update한다.
§ Downstream Task - 위에서 진행한 upstream으로 pretrain을 한 이유는 downstream task을 잘하기 위해서이다. 이런 downstream task는 자연어처리의 구체적인 과제들이다. 예를 들자면 분류(classification)처럼 입력이 어떤 범주에 해당하는지 확률형태로 반환한다. - 문장생성을 제외한 대부분은 pretrain을 마친 Masked Language Model (BERT, etc.)을 사용한다.
ex. 문서분류, 자연어 추론, 개체명 인식, 질의응답, 문장생성 등에 대해 처리한다.
▶ Fine-tuning - downstream task의 학습방식 중 하나로 pretrain을 마친 모델을 downstream task에 맞게 update하는 기법이다.