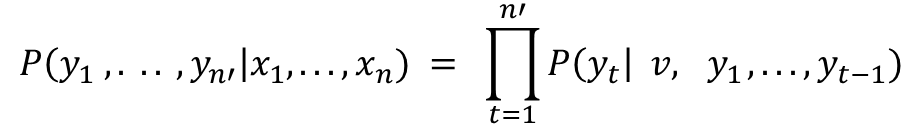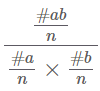🤫 NLP(Natural Language Processing)란? 컴퓨터의 언어가 아닌, 인간이 사용하는 언어를 처리하는 분야이다.
🤫 token? 그게 뭐지?? 글 ⊃ 문장 ⊃ 단어로 글은 이루어져 있는데, 단어는 글의 의미있는 부분 중 가장 작은단위이다. 이때, 문법적으로 가장 작은 단위를 토큰(token)이라 하며, 전체 글을 토큰으로 나누는 것을 토큰화(tokenization)라한다.
이렇게 토큰화를 이용하면 기본적인 분석이 가능한데, 예를들어 어떤 토큰이 자주 사용되는지를 알 수 있는데, 이를 워드 카운트(word_counts)라 한다.
🧐 단어를 벡터로 변환
🤫 token을 벡터로 변환?? token을 벡터로 표현하는 방법의 하나는 one-hot encoding인데, 이에 대해 아래 코드로 살펴보자.
🧐 단어 임베딩 (embedding)
🤫 token을 벡터로 변환?? token을 벡터로 표현하는 one-hot encoding은 장점도 있지만 단점이 명확한 방법이다. 만약 단어 인덱스가 100,000개 존재한다면? → 하나의 단어를 표현하기 위해 100,001길이의 벡터가 필요하게 된다는 점!
따라서 단어 임베딩(Embedding)이라는 방법을 사용한다. 단어 임베딩은 단어 벡터의 길이를 사용자가 직접 지정할 수 있다는 장점이 있다. 즉, 인덱스 길이에 상관없이 사용자가 지정한 벡터의 길이로 모든 단어를 표현한다. 임베딩의 원리: '바꾸고'라는 단어를 임베딩하는 과정임베딩하려는 단어의 벡터를 준비하고 임베딩을 위한 행렬을 준비한다. [행: 임베딩할 단어의 개수 // 열: 임베딩 벡터의 크기]
위에서의 실습에서 벡터의 길이가 6이었지만, 아래는 해당 문장을 벡터의 길이가 3으로 지정해 임베딩하는 것을 보여주는 코드이다.
🧐 seq2seq model
기존의 딥러닝 - 기존의 딥러닝은 input과 output데이터의 차원이 고정된 벡터인 경우에만 사용 - 하지만 실제 문제들은 벡터의 길이가 사전에 알 수 없는 sequence로 표현되는 경우가 많음
🤫 seq2seq란? 입력값으로 sequence를 받고 출력값으로 다른 sequence를 출력하는 모형 입력 sequence와 출력 sequence를 맵핑하는 model으로 다음 2가지 경우가 존재 1. input sequence와 output sequence가 같은 경우 (input sequence의 길이정보가 필수적) 2. input sequence와 output sequence의 길이가 다른 경우 (targe예측을 위한 input sequence 전체가 요구됨)
🤫 seq2seq에 대한 개념적, 구조적 접근 개념적: RNN과 Auto-Encoder를 합친 형태 구조적: 2개의 RNN을 합친 형태 (특히 LSTM과 GRU를 자주 사용) 아래 예시를 통해 이해해 보자. 인코더 내부에서 1개의 step마다 한개의 LSTM모형이 존재하기에 결과적으로 여러 LSTM이 존재하고 큰 차원의 벡터를 입력받을 수 있다. 이때, 인코더는 입력시퀀스를 처리하고 은닉"상태(state)"를 return한다. 즉, encoder의 output은 버리고 오직 "상태"만 전달시키는데, 이때 인코딩 과정에서 입력데이터를 하나의 벡터로 압축하는 context vector를 진행한다. 인코딩 과정을 거친 은닉벡터를 입력받아 출력 시퀀스를 출력한다. 이때, 디코더는target sequence의 한 시점 이전 문자가 주어지면, 바로 다음 문자를 예측하도록 학습되며 중요한 점은 디코더는 인코더의 출력벡터인 context vector를 초기 벡터로 사용한다! 즉,target sequence를 같은 sequence로 변하게 학습하지만 한시점 미래로 offset을 하는, 교사강요(teacher forcing) 학습과정을 진행한다. ex) input sequence가 주어지면 디코더는 target값[..t]가 주어질 때, target값[t+1..]를 예측하도록 학습한다. 이를 통해 디코더는 어떤 문자를 생성할 것인지에 대한 정보를 구할 수 있다.
이때, <sos>는 start-of-string을, <eos>는 end-of-string을 의미한다.
🤫 seq2seq. Algorithm 1. input sequence를 context 벡터로 encoding, 출력 2. size가 1의 target sequence로 시작.(target sequence는 단지 start-of-string문자) 3. 다음 문자를 예측하기 위해 decoder에 상태벡터와 1-char target sequence를 넣는다. 4. 이러한 예측법으로 다음 문자를 sampling 5. 뽑힌 문자를 target sequence에 추가 6. 이러한 과정을 <eos>가 나오거나 문자 한계치에 도달할 때까지 반복
🤫 입력시퀀스 (x1, . . . , xn)을 입력받았을 때, 출력시퀀스(y1, . . ., yn')를 출력하는 모델에 대해 살펴보자. 입력시퀀스에 대한 출력시퀀스의 조건부확률 P(y1, . . ., yn' | x1, . . . , xn)를 추정해야 하는 것이 목적이므로 아래와 같은 식을 사용해 구할 수 있다. 위 식에서 v는 입력데이터 시퀀스 데이터 x가 인코더를 거친 후 출력되는 context vector를 의미하며 P(yt |v, y1, . . . ,yt-1)는 모든 가능한 출력 후보에 softmax함수를 적용한 값이다.
🧐 Attention
🤫 seq2seq보다 좀 더 발전시켜볼까? 이름처럼 주위에 신경을 기울인다는 뜻으로 출력단어를 예측하는 매 시점 encoder에서 전체 입력문장을 참고하는 방식. 앞서 배운 seq2seq(일명 바닐라 seq2seq)는 직전 벡터에 가장 큰 영향을 받아 시간이 지나면서 정보를 잃는 한계점이 존재 반면, attention은 모든 decoding과정마다 encoder내부의 모든 hidden layer를 참고한다. 이때, encoder의 은닉상태를 동등하게 참고하지 않고 출력단어와 연관이 있는 부분을 좀 더 집중(attention)해서 참고한다.
attention의 세부단계는 총 5단계를 거치는데, 다음과 같다. 1. 내적 - decoder의 은닉상태 벡터 · encodeer의 은닉상태 벡터 = 각각의 은닉상태 벡터에 대한 attention score 2. attention의 분포 구하기 - softmax함수를 이용해 분포를 구하며 확률분포이기에 모두 합하면 1이 된다. - 이때, 막대의 크기가 가장 큰 것이 How에 해당하는 attention score이기에 How와 연관이 크다는 것을 알 수 있다. 3. attention의 output구하기 - attention 분포 ⊙ encoder 은닉상태 = attention output. (원소곱 진행) 4. output layer의 input 구하기 - 출력층 입력 = attention output과 해당단계의 decoder 은닉상태를 이어붙인 후 w를 곱하고 b를 더해 activation 함수에 넣음 5. predict한 값 구하기 - 최종 예측값 = 4에서 구한 출력층 입력벡터에 w행렬을 곱하고 b를 더한 후 softmax를 사용
토큰화(tokenization)란 문장을 토큰으로 나누는 과정으로 수행대상에 따라 다음 세 방법이 있다. - 문자 - 단어 - 서브워드
§ 문자 단위 토큰화 - 한글 위주로 표현된 데이터로 언어 모델을 만든다 하자. 한글 음절 수는 1만1172개이므로 알파벳, 숫자 등을 고려 해도 어휘 집합 크기는 최대 1만5000개를 넘기 어렵다. 게다가 해당 언어의 모든 문자를 어휘 집합에 포함하므로 미등록 토큰(unknown token) 문제로부터 자유롭다. 미등록 토큰이란 어휘 집합에 없는 토큰이다. (주로 신조어 등에서 발생)
하지만 문자 단위로 토큰화를 수행할 경우 단점도 있는데, 각 문자 토큰은 의미 있는 단위가 되기 어려운데, 예를 들어 어제와 어미간의 어의 구분이 모호해지는 것처럼 단점이 존재한다. 어제 카페 갔었어 > 어 / 제 / 카 / 페 / 갔 / 었 / 어 어제 카페 갔었는데요 > 어 / 제 / 카 / 페 / 갔 / 었 / 는 / 데 / 요
뿐만 아니라 문자 단위 토큰화는 앞의 단어 단위와 비교할 때 분석 결과인 토큰 시퀀스의 길이가 상대적으로 길어졌음을 확인할 수 있다. 언어 모델에 입력할 토큰 시퀀스가 길면 모델이 해당 문장을 학습하기가 어려워지고 결과적으로 성능이 떨어지게 된다.
§ 단어(어절) 단위 토큰화 - 가장 쉽게 생각해보면 공백으로 분리할 수 있다. 어제 카페 갔었어 > 어제 / 카페 / 갔었어 어제 카페 갔었는데요 > 어제 / 카페 / 갔었는데요
공백으로 분리하면 별도의 토크나이저를 쓰지 않아도 된다는 장점이 있다. 다만, 어휘 집합의 크기가 매우 커질 수 있는데, 갔었어, 갔었는데요 처럼 표현이 살짝만 바뀌어도 모든 경우의 수가 어휘 집합에 포함돼야 하기 때문이다.
만약 학습된 토크나이저를 사용하면 어휘 집합의 크기가 커지는 것을 조금 완화할 수는 있다. 예를 들어 같은 문장을 은전한닢으로 토큰화하면 다음과 같다. 예시가 적어서 효과가 도드라져 보이지는 않지만, 의미 있는 단위로, (예를 들면 갔었) 토큰화해 어휘 집합이 급격하게 커지는 것을 다소 막을 수 있다. 어제 카페 갔었어 > 어제 / 카페 / 갔었 / 어 어제 카페 갔었는데요 > 어제 / 카페 / 갔었 / 는데요
그렇지만 위 같은 토크나이저를 사용하더라도 어휘 집합 크기가 지나치게 커지는 것은 막기 어려운데, 보통 언어 하나로 모델을 구축할 때 어휘 집합 크기는 10만 개를 훌쩍 넘는 경우가 다반사이기에 어휘 집합 크기가 커지면 그만큼 모델 학습이 어려워질 수 있다.
§ 서브워드 단위 토큰화 - 단위 토큰화는 단어와 문자 단위 토큰화의 중간에 있는 형태로. 둘의 장점만을 취한 형태이다. 어휘 집합 크기가 지나치게 커지지 않으면서도 미등록 토큰 문제를 피하고, 분석된 토큰 시퀀스가 너무 길어지지 않게 한다. - 대표적인 서브워드 단위 토큰화 기법이라면 바이트 페어 인코딩을 들 수 있는데 아래에서 소개하겠다.
※ Byte Pair Encoding Algorithm
- BPE는 정보를 압축하는 알고리즘으로 원래 제안된 것으로 데이터에서 최빈문자열을 병합해 압축하는 기법이다.
최근에는 자연어 처리모델에서 쓰이는 토큰화 기법이다.
GPT 모델은 BPE기법으로 토큰화를 수행
BERT모델은 BPE와 유사한 워드피스(wordpiece)를 토크나이저로 사용
예를 들어 다음과 같은 데이터가 있다고 가정하자.
aaabdaaabac
BPE는 데이터에 등장한 글자(a,b,c,d)를 초기 사전으로 구성하며, 연속된 두 글자를 한 글자로 병합한다.
이 문자열에선aa가 가장 많이 나타났으므로 이를Z로 병합(치환)하면 다음과 같이 압축할 수 있다.
ZabdZabac
이 문자열은 한번 더 압축 가능한데, ab가 가장 많이 나타났으므로 이를Y로 병합(치환)한다.
ZYdZYac
물론ab대신Za를 병합할 수도 있지만 둘의 빈도수가 2로 같으므로 알파벳 순으로 앞선ab를 먼저 병합한다.
ZY역시X로 병합할 수 있습니다. 이미 병합된 문자열 역시 한 번 더 병합할 수 있다는 얘기로 다음과 같다.
XdXac
※ BPE 어휘집합 구축하기.
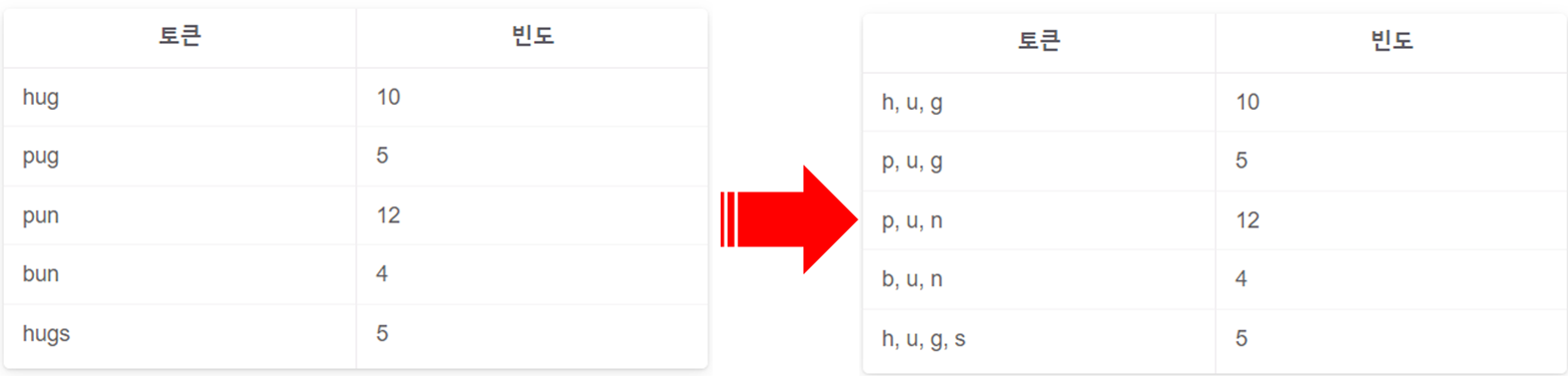
1. pre-tokenize 진행 (말뭉치를 준비 후 모든 문장을 공백으로 나눠줌. 물론 다른 기준으로 나눌 수도 있음)
2. pre-tokenize 진행 후 그 빈도를 모두 세어 초기 어휘 집합을 구한다.
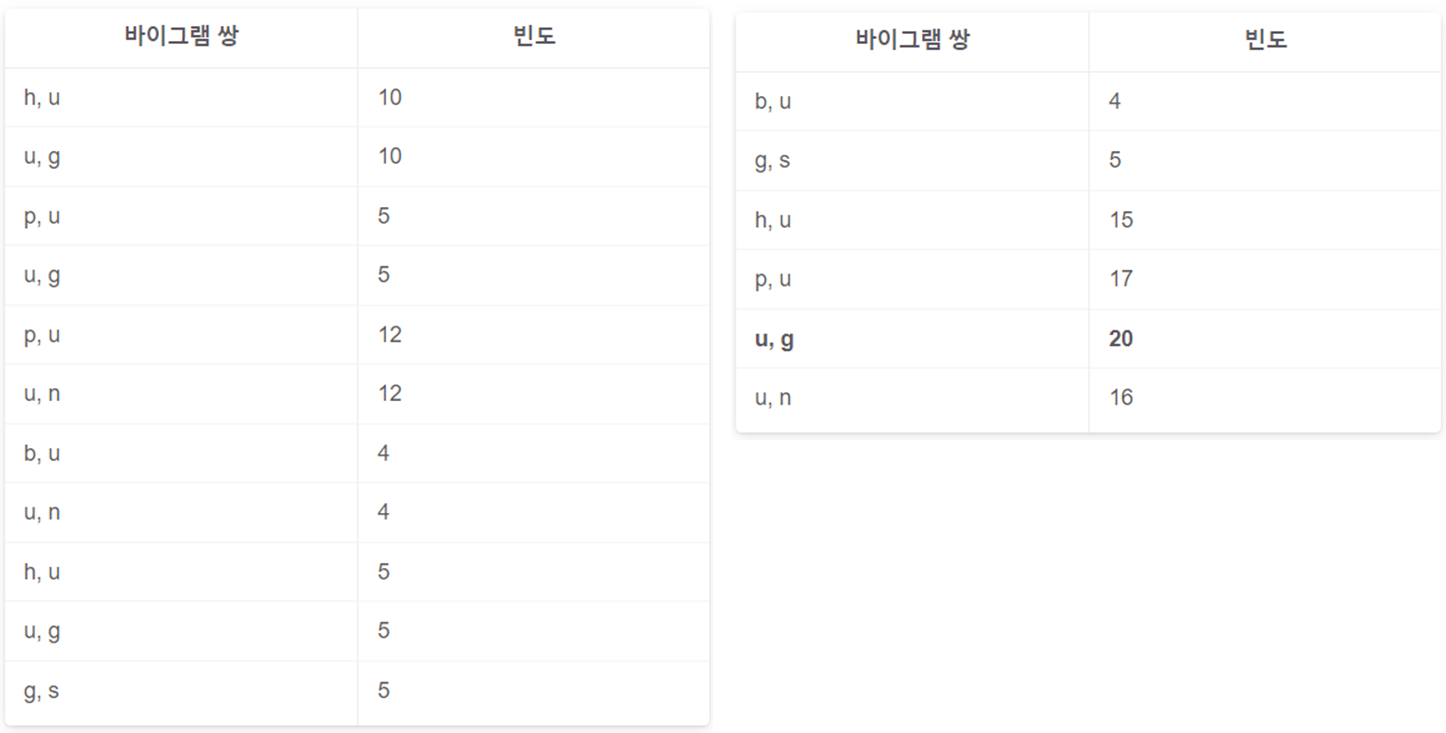
3. 위의 어휘집합을 바이그램 쌍(토큰을 2개씩 묶어 나열)으로 만들고 바이그램 쌍을 합친다.
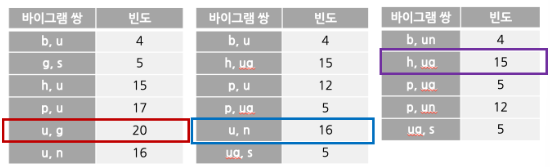
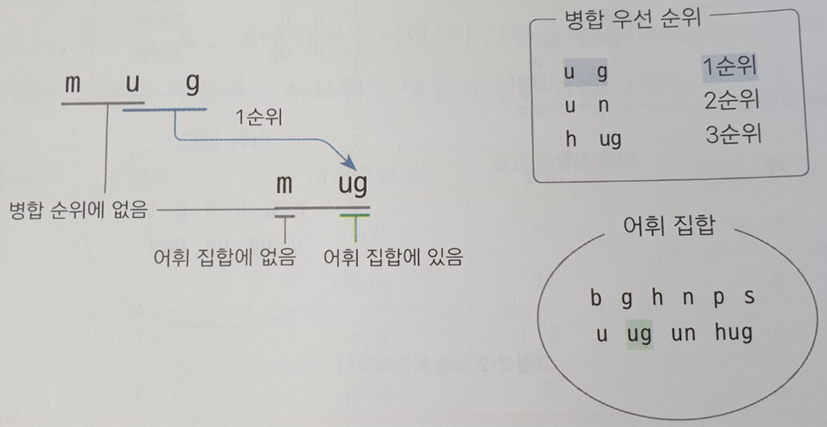
4. 가장 많이 등장한 바이그램쌍을 합쳐 집합에 추가 (위를 예로 들면 u, g를 합친 ug를 바이그램에 추가)
>> b / g / h / n / p / s / u / ug
이후 계속 사용자가 정한 크기 전까지 반복해서 진행.
5. 입력이 들어오면 입력을 문자단위로 분리 후 병합의 우선순위(by 빈도)에 따라 merge 진행.
만약 input으로 mug가 들어온다면?
따라서 출력은 다음과 같이 <unk>, ug로 나오며 <unk>는 unkown token(미등록 토큰)을 의미.
※ WordPiece.
BPE와 비슷하지만 빈도를 기준으로 merge를 진행하는 BPE와는 달리
Wordpiece는 likelihood를 기준으로 likelihood가 높은 쌍을 merge한다.