vector / pair / stack , queue, deque , priority queue / map / set / algorithm / iterator / bitsetThe C++ Programming Language 4th.Edition
※ vector (std::vector) _가변배열 / 가장 기본이 되는 컨테이너 (★★ ★ ★ ★ )
#include <vector>
using namespace std;
vector<자료형> 변수명(숫자) //숫자만큼 벡터 생성 후 0으로 초기화
vector<자료형> 변수명(숫자, 변수1); //숫자만큼 벡터 생성 후 변수1으로 모든 원소 초기화
vector<자료형> 변수명{숫자, 변수1, 변수2, 변수3, ...}; // 벡터 생성 후 오른쪽 변수 값으로 초기화
vector<자료형> 변수명[]={ {변수1, 변수2}, {변수3, 변수4}, ...} //2차원 벡터생성 (열은 고정, 행 가변)
vector<vector <자료형>> 변수명 //2차원 벡터생성 (열, 행 가변)
ex);
vector<int> vec1; // 크기가 0인 벡터 선언
vector<int> vec2(10); // 크기가 10인 벡터 선언
vector<int> vec3(10, 3); // 크기가 10이고 모든 원소가 3으로 초기화된 벡터
vector<int> vec4 = { 1,2,3,4,5 }; // 크기가 지정한 초기값으로 이루어진 벡터
vector<int> vec5[] = { {1,2},{3,4} }; // 벡터 배열 생성(행은 가변인지만, 열은 고정)
vector<vector<int>> vec6; // 2차원 벡터 생성(행과 열 모두 가변)
※ vector 요소 삽입, 제거, 변경
#include <vector>
using namespace std;
int main() {
vector<int> vec; // 크기가 0인 벡터 선언
vec.push_back(10);
vec.push_back(20); // vec = {10, 20}
vec.insert(vec.begin() + 1, 100); // vec = {10, 100, 20}
vec.pop_back(); // vec = {10,100}
vec.emplace_back(1); // vec = {10, 100, 1}
vec.emplace_back(2); // vec = {10, 100, 1, 2}
vec.emplace(vec.begin() + 2, -50); // vec = {10, 100, -50, 1, 2}
vec.erase(vec.begin() + 1); // vec = {1, -50, 1, 2}
vec.resize(6); // vec = {1, -50, 1, 2, 0, 0}
vec.clear(); // vec = empty()
}
※ vector의 index 접근
※ vec.at(i)와 vec.[i]의 차이점 - at 예외처리 를 발생시킨다. (std::out_of_range )
- [ ]
vector는 효율에 중점을 두기에 보통 [ ]를 권장 한다.
※ vector의 크기 size, capacity - size: vector의 크기, 즉 벡터에 실제로 저장된 원소의 개수를 뜻한다.
- capacity : vector의 용량, 즉 벡터의 최대 할당 크기를 뜻한다.
만약 벡터의 크기가 용량을 초과한다면 재할당이 발생한다. (기존 값 새 메모리에 복사 후 파괴)
if (size > capacity) {
reallocate <- 모든 값 새 메모리에 복사 후 기존 벡터 파괴
}
Problem 1. 새 메모리의 복사과정에서 복사생성자가 발생 해 성능이 저하될 수 있다.
Solution 1. reserve() 라는 함수를 사용해서 벡터의 용량을 충분히 크게 생성할 수 있다.
Problem 2. reserve() 를 너무 크게 잡으면 벡터가 불필요하게 늘어나 메모리를 많이 차지할 수 있다.
Solution 2. clear() 로 벡터의 값을 지울 때, 벡터의 요소를 삭제할 수 있다.
Problem 3. clear() 로 벡터의 요소는 없어지지만 capacity는 그대로 남아있다 .
Solution 3. 이를 해결하기 위해 swap()
#include <vector>
using namespace std;
int main() {
vector<int> vec = { 1,2,3,4,5 };
vec.clear();
cout << vec.capacity() << endl; // 5 출력
vector<int>().swap(vec);
cout << vec.capacity() << endl; // 0 출력
}
https://chan4im.tistory.com/19?category=1076581
this.code(1).DS_ Array, array container & Vector (STL)
※ Array (배열) ※ 1차원 배열 배열은 주로 여러 개의 동일한 자료형의 데이터를 한꺼번에 만들 때 사용된다. 예를 들어 a0, a1, a2, a3, a4, a5라는 6개의 정수형 변수를 A[6]으로 간단하게 선언할 수 있
chan4im.tistory.com
★★ ★ ★ ★ ★ ★ ★ ★ ★ #include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> v;
int main() {
int num;
for (int i = 0; i < 5; i++){
//cin >> v[i]; // Err!
cin >> num;
v.push_back(num);
}
vector<int>::iterator it;
sort(v.begin(), v.end(), greater<int>());
for (it = v.begin(); it != v.end(); it++){
cout << *it << ' ';
}
}
※ pair ★★★개인적으로 굉장히 유용하다고 생각되는 라이브러리★★★
feat. vector, sort
두 자료형을 하나의 쌍(pair)으로 묶는다.
첫번째 데이터는 first, 두번째 데이터는 second로 접근, make_pair(val1, val2)로 pair를 생성해준다.
vector, algorithm 의 헤더파일에 include 하고 있기에 별도의 헤더를 include할 필요가 없다.
#include <iostream>
using namespace std;
#include <vector>
int main(){
pair<int, int> p1;
cout << p1.first << ' ' << p1.second << endl; // 0 0 출력
p1 = make_pair(1, 2);
cout << p1.first << ' ' << p1.second << endl; // 1 2 출력
pair<pair<int, int>, pair<int, int>> p2 = make_pair(make_pair(1, 2), make_pair(3, 4));
cout << p2.first.first << ' ' << p2.first.second << endl; // 1 2 출력
cout << p2.second.first << ' ' << p2.second.second << endl; // 3 4 출력
}
pair로 vector, typedef, sort 다루기 #include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main(){
pair<int, int> p1;
cout << p1.first << ' ' << p1.second << endl; // 0 0 출력
p1 = make_pair(1, 2);
cout << p1.first << ' ' << p1.second << endl; // 1 2 출력
pair<pair<int, int>, pair<int, int>> p2 = make_pair(make_pair(1, 2), make_pair(3, 4));
cout << p2.first.first << ' ' << p2.first.second << endl; // 1 2 출력
cout << p2.second.first << ' ' << p2.second.second << endl; // 3 4 출력
//vector와 pair
vector<pair<int, int>> v;
v.push_back(make_pair(10, 20));
v.push_back(make_pair(30, 40));
v.push_back(make_pair(50, 60));
cout << v[0].first << ' ' << v[2].second << endl;
// typedef를 이용한 방식
typedef pair<int, int> P;
vector<P> v1;
v1.push_back(make_pair(300, 500));
v1.push_back(make_pair(600, 400));
v1.push_back(make_pair(100, 200));
// first 따로, second 따로 정렬
sort(v1.begin(), v1.end());
vector<P>::iterator it;
for (int i = 0; i < 3; i++)
cout << v1[i].first << " " << v1[i].second << endl;
}
※ stack #include <stack>
stack<데이터타입> 이름;
https://chan4im.tistory.com/22?category=1076581
this.code(2).DS_ Stack & Stack Container(STL)
※ Stack 스택은 LIFO(Last-In-First-Out) 입출력 형태, 즉 후입선출 방식을 가진 자료구조이다. 위의 그림에서 4, 5번째 그림을 보자. Last In: 3 / First Out: 3 즉, 가장 마지막에 들어온 data가 가장 먼저 나..
chan4im.tistory.com
※ stack, queue, deque priority queue, priority queue
※ queue 선언방식 #include <queue>
queue<데이터타입> 이름;
※ deque 선언방식 #include <deque>
deque<데이터타입> 이름;
https://chan4im.tistory.com/29?category=1076581
★this.code(3).DS_ Queue & (STL): queue, deque
※ Queue 큐는 FIFO(First-In-First-Out) 입출력 형태, 즉 선입선출 방식을 가진 자료구조이다. enqueue와 dequeue의 시간복잡도는 둘 다 O(1)의 시간을 갖는다. 단, 탐색의 시간복잡도는 특정 data를 찾을 때까.
chan4im.tistory.com
※ priority queue 선언방식 #include <queue>
priority_queue<int> pq;
priority_queue<int, vector<int>, greater<int> > pq;
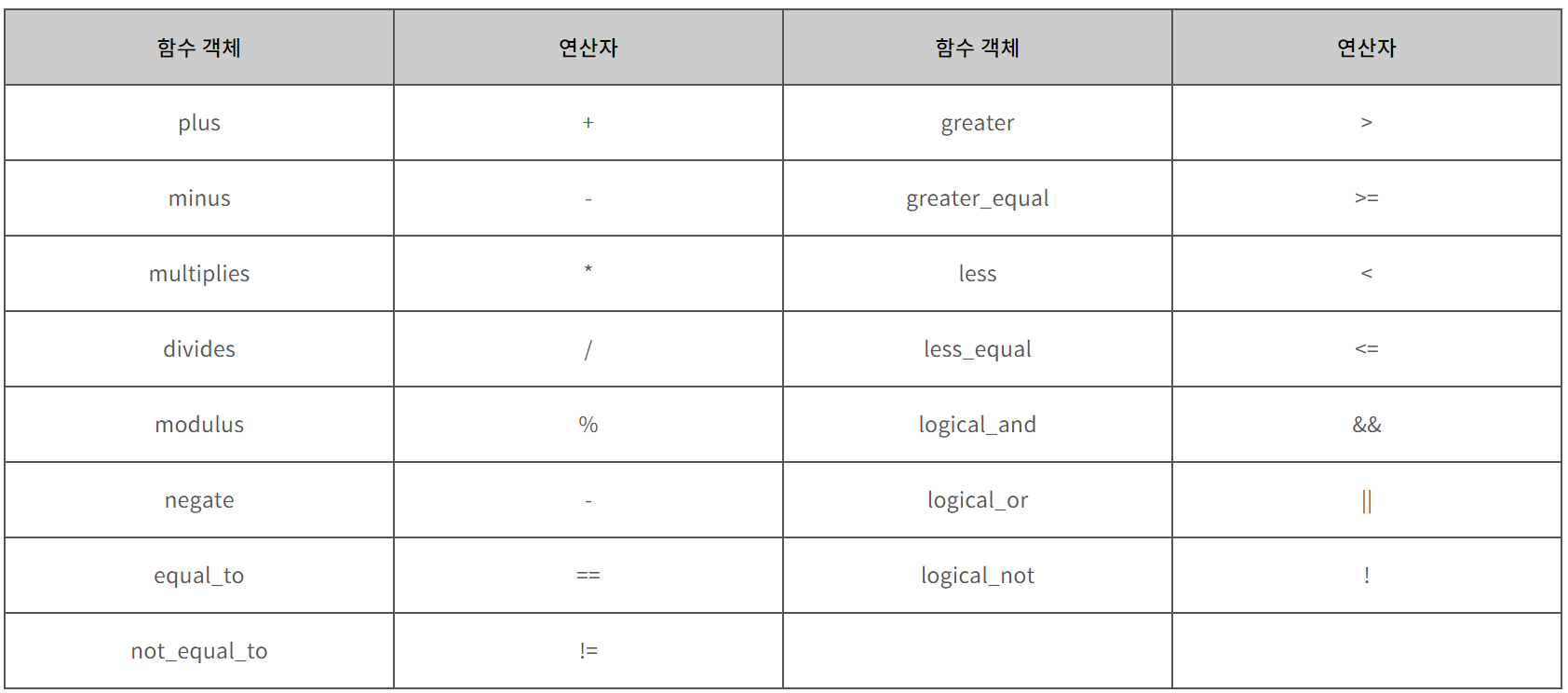
priority_queue<int, vector<int>, less<int> > pq;가장 기본적인 것 부터 시작해 여러 방식으로 변형하며 사용할 수 있다.
우측 사진 출처: http://www.tcpschool.com/cpp/cpp_algorithm_functor
※ map map은 각 node가 [key - value] 의 쌍(pair)으로 이루어진 트리이다.
특히나 map의 가장 큰 특징은 중복을 허용하지 않는다는 것이다! => key가 중복되면 insert가 수행되지 않음
C++의 map 내부구현은 삽입, 삭제, 검색의 시간복잡도가 O(logn) 인 레드블랙트리 로 구성되어 있다.
unordered_map은 해시 테이블
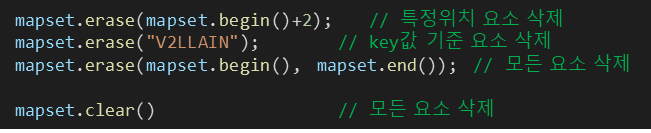
※ map 선언방식 (삭제) #include <map>
map<key_type, value_type> 이름;※ map 삭제
※ map에서 찾고자 하는 데이터 확인 (search, find) map에서 원하는 값을 찾고자 할 때, iterator를 사용한다.
만약 끝까지 원하는 값을 찾지 못하면, iterator는 map.end()를 반환한다.
find(k) 로 사용하며 key값 k에 해당하는 iterator를 반환한다.
map<string, int> mapset;
if (mapset.find("V2LLAIN") != mapset.end()){
cout << "find!" << endl;
}
else
cout << "not find!" << endl;
※ 반복문 데이터 접근 (first, second) ※ index 기반 iterator 활용 예제map<string, int> mapset;
for (auto it = mapset.begin(); it != mapset.end(); it++) {
cout << it->first << " " << it->second << endl;
}
cout << endl;※ 범위기반 반복문 활용 예제map<string, int> mapset;
for (auto it : mapset){
cout << it.first << " " << it.second << endl;
}
※ map 사용 예제 (insert, search, iterator 구현) #include <iostream>
#include <map>
using namespace std;
map<string, int> mapset;
int main() {
mapset.insert({ "Alice", 100 });
mapset.insert({ "Bob", 200 });
if (mapset.find("Alice") != mapset.end())
{
cout << "find" << endl;
}
else {
cout << "not find" << endl;
}
//인덱스기반
for (auto iter = mapset.begin() ; iter != mapset.end(); iter++)
{
cout << iter->first << " " << iter->second << endl;
}
cout << endl;
//범위기반
for (auto iter : mapset) {
cout << iter.first << " " << iter.second << endl;
}
}참고) https://life-with-coding.tistory.com/305?category=808106
※ set - set은 연관 컨테이너로 삽입, 삭제, 검색의 시간복잡도가 O(logn) 인 Binary Search Tree
- key라는 원소들의 "집합"으로 key값은 중복되지 않는다!
- insert() 자동적으로 오름차순 정렬
∴ 중복을 피하면서 정렬까지 사용할 때 매우 유용하다!
insert(k) : 원소 k 삽입begin() : 맨 첫번째 원소를 가리키는 iterator를 반환end() : find(k) : 원소 k를 가리키는 iterator를 반환size() : setempty() :
※ algorithm ※ STL 알고리즘의 분류
find() 는 2개의 입력 반복자로 지정된 범위에서 특정 값을 가지는 첫 번째 요소를 가리키는 입력 반복자를 반환
for_each() 는 2개의 입력 반복자로 지정된 범위의 모든 요소를 함수 객체에 대입한 후, 대입한 함수 객체를 반환
copy() 는 2개의 입력 반복자로 지정된 범위의 모든 요소를 출력 반복자가 가리키는 위치에 복사
swap() 은 2개의 참조가 가리키는 위치의 값을 서로 교환
transform() 은 2개의 입력 반복자로 지정된 범위의 모든 요소를 함수 객체에 대입후, 출력 반복자가 가리키는 위치에 복사
sort() 모든 요소를 비교 , 오름차순정렬
stable_sort() 값이 같은 요소들의 상대적인 순서는 유지, 오름차순으로 정렬
binary_sort() 는 정렬되어있는 경우(오름차순)에 한해서 탐색효율이 매우 좋고 적은 시간에 소요된다.
accumulate() 는 두 개의 입력 반복자로 지정된 범위의 모든 요소의 합을 반환합니다.
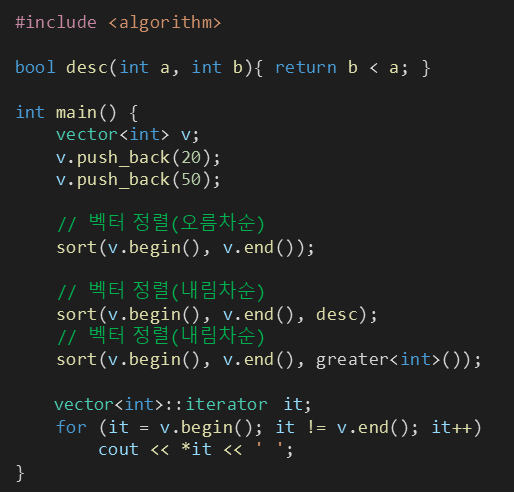
※ 벡터의 오름차순과 내림차순 정렬 (feat. greater<int> 키워드) § sort() 함수 형식 단, custom_func()은 0 또는 1이 나오도록 해야해서 보통 bool형 함수를 많이 넣는다.
sort(v.begin(), v.end()); //형식이나
sort(v.begin(), v.end(), custom_func); //형식으로 사용가능하다.#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> v;
for (int i = 0; i < 5; i++) {
int num; cin >> num;
v.push_back(num);
}
sort(v.begin(), v.end()); // 오름차순
sort(v.rbegin(), v.rend()); // 내림차순
for (auto x: v) {
cout << x;
}
}
※ 벡터의 이진탐색
http://www.tcpschool.com/cpp/cpp_algorithm_functor
※ iterator STL에 저장된 요소를 반복적으로 순회해여 각각의 요소에 대한 접근을 제공하는 객체.
즉, 컨테이너의 구조,요소의 타입과 상관없이 컨테이너에 "저장된 요소"를 순회하는 과정을 일반화한 표현
[iterator를 쓰기 위한 요건]
1. 가리키는 요소의 값에 접근할 수 있어야 한다. => 참조 연산자(*)가 정의되어야 합니다.
2. 반복자 사이의 대입 연산, 비교 연산이 가능해야 합니다. => 대입, 관계 연산자가 정의되어야 합니다.
3. 가리키는 요소의 주변 요소로 이동할 수 있어야 합니다. => 증가 연산자(++)가 정의되어야 합니다.
int main() {
vector<int> v(5);
v.push_back(20);
v.push_back(50);
v.push_back(10);
for (int i = 0; i < 5; i++)
cin >> v[i];
vector<int>::iterator it;
for (it = v.begin(); it != v.end(); it++) {
cout << *it << ' ';
}
//1 2 3 4 5 20 50 10 출력
}
표준 컨테이너 시간 복잡도 (The C++ Programming Language)
※ bitset 비트연산의 간편화를 위해 사용하는 라이브러리
#include <bitset>
int main() {
bitset<100000> a(76),b(44); // 각각 76, 44의 비트가 입력됨
cout << (a & b) << '\n';
cout << (a | b) << '\n';
cout << (a ^ b) << '\n';
cout << (~a) << '\n';
cout << (~b) << '\n';
return 0;
}