🤫 CNN, 합성곱 신경망이란? 여러 분야, 특히나 image classification에서 좋은 성능을 보여주는 방법이다. 이런 합성곱 신경망에서 합성곱의 연산은 정의 자체에 가중치를 flip하는 연산이기에 아래와 같은 수식으로 표현한다. i와 j시점에서 input x와 kernel(= weight)의 합성곱에 편향(bias)를 각 pixel에 더해 output y를 도출한다. 이때, 아래와 같은 연산식을 Cross-Correlation이라 부른다.
🤫 CNN이 등장하게 된 이유는 무엇일까? MLP vs CNN ▶ image classification에서 MLP보다 CNN이 더 선호된다.
1.MLP는 각 input(한 image의 pixel)에 대해 하나의 퍼셉트론만 사용하고 large한 image에 대해 weight가 급격하게 unmanageable해진다. 이는 너무 많은 parameter들이 fully-connected되어 있기 때문이다. 따라서 일반화를 위한 능력을 잃는, 과적합(overfitting)이 발생할 수 있다.
2. MLP는 input image와 shift된 image가 다르게 반응한다는 점이다. (translation invariant(불변)가 아니기 때문)
예를 들어 고양이 사진이 한 사진의 이미지 왼쪽 상단에 나타나고 다른 사진의 오른쪽 하단에 나타나면 MLP는 자체 수정을 시도하고 고양이가 이미지의 이 섹션에 항상 나타날 것이다.
즉, MLP는 이미지 처리에 사용하기에 가장 좋은 아이디어가 아니다. 주요 문제 중 하나는 이미지가 MLP로 flatten(matrix -> vector)될 때 공간 정보가 손실된다.
∴고양이가 어디에 나타나든 사진에서 고양이를 볼 수 있도록 image features(pixel)의 공간적 상관 관계(spatial correlation)를 활용할 방법이 필요.
∴ 이를 위한 해결책으로 등장한 것이 바로 CNN 이다!
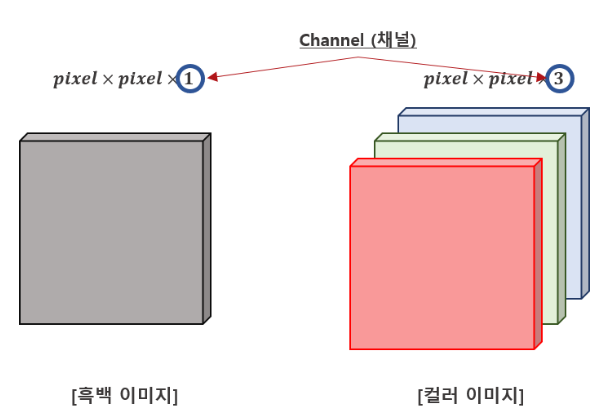
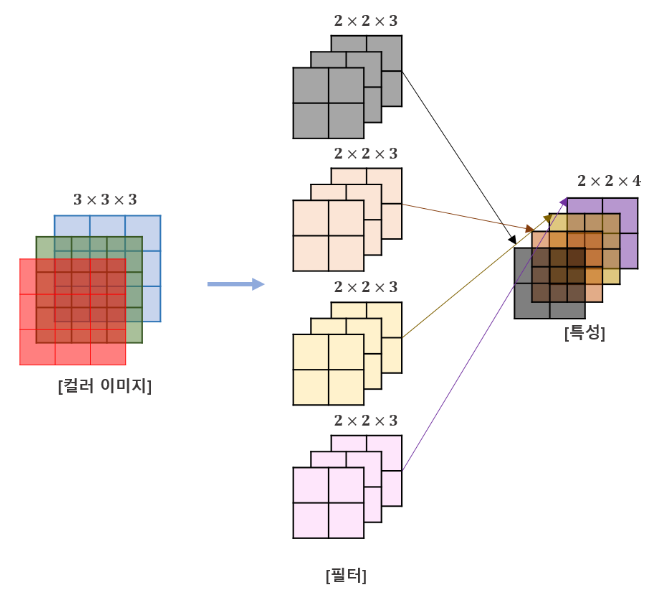
좀 더 일반적으로, CNN은 공간적 상관관계가 있는 data에 잘 반응할 수 있다. 따라서 CNN은 input으로 image data를 포함하는 문제에 대한 prediction의 한 방법이다.
이런 CNN의 사용은 2차원 이상의 image의 내부적 표현에 대한 좋은 이점을 갖는다. 즉, image작업 시, 가변적인 구조의 data안에서의 position과 scale을 model이 배우기 쉽게 해준다.
🧐 Padding, Stride, Pooling
🤫 Padding 예를들어 4x4차원이 input에 2x2의 kernel로 합성곱을 하게되면 output 차원은 3x3으로 차원이 줄어든다. 이렇게 차원이 줄어드는 현상을 방지하기 위해서 padding이라는 방법을 사용한다. 위 사진처럼입력 데이터는 3x3이지만zero-padding을 통해 차원의 축소가 일어나지 않게 할 수 있다.
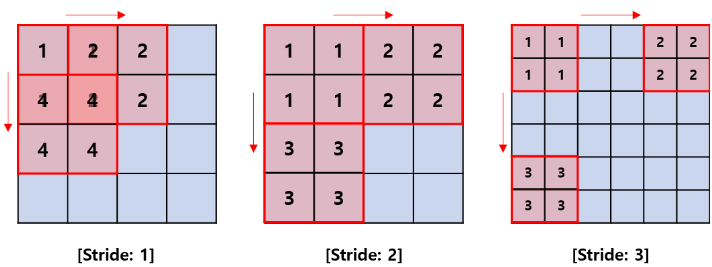
🤫 Stride 한 번의 합성곱연산 이후 다음 계산영역으로 이동을 해야하는데, 이때 얼마나 이동할 것인지 간격을 정하는 값이며 이때 output 데이터 행렬의 차원이 더 작아지는 것을 알 수 있다. 그렇다면, padding과 stride를 해도 output data의 크기를 미리 계산할 수는 없을까?
🤫 Pooling CNN에서 feature의 resolution을 줄일 때, 사용하는 방식으로 아래와 같이 작동한다.
그렇다면, 이쯤에서 드는 생각이 있을 것이다. Question? 왜 굳이? pooling을 사용하는거지? 그냥 convolution layer를 stride = 2로 줄여서 작동하면 같은작업이지 않나?
Answer!
convolution layer를 이용하여stride = 2로 줄이면학습 가능한 파라미터가 추가되므로 학습 가능한 방식으로 resolution을 줄이게 되나 그만큼 파라미터의 증가 및 연산량이 증가하게 됩니다.
반면pooling을 이용하여 resolution을 줄이게 되면 학습과 무관해지며 학습할 파라미터 없이 정해진 방식 (max, average)으로 resolution을 줄이게 되어 연산 및 학습량은 줄어든다. 다만convolution with stride방식보다 성능이 좋지 못하다고 알려져 있습니다. 따라서,layer를 줄여서 gradient 전파에 초점을 두려고 할 때 pooling을 사용하는게 도움이