- ResNet은 는 설득력 있는 정확도와 멋진 수렴동작을 보여주는 매우 심층적인 아키텍처군으로 부상했다.
본 논문에서는 "Identity Mapping"을 "Skip Connection" 및 "After-addition Activation"로 사용할 때 순전파/후전파 signal이 한 블록에서 다른 블록으로 직접 전파될 수 있음을 제안하는 residual building block 이후의 propagation공식을 분석한다.
일련의 제거(ablation)실험은 이런 identity mapping의 중요성을 뒷받침한다. 이는 새로운 residual unit을 제안하도록 동기부여하여 훈련을 더 쉽게 하고 일반화를 개선한다.
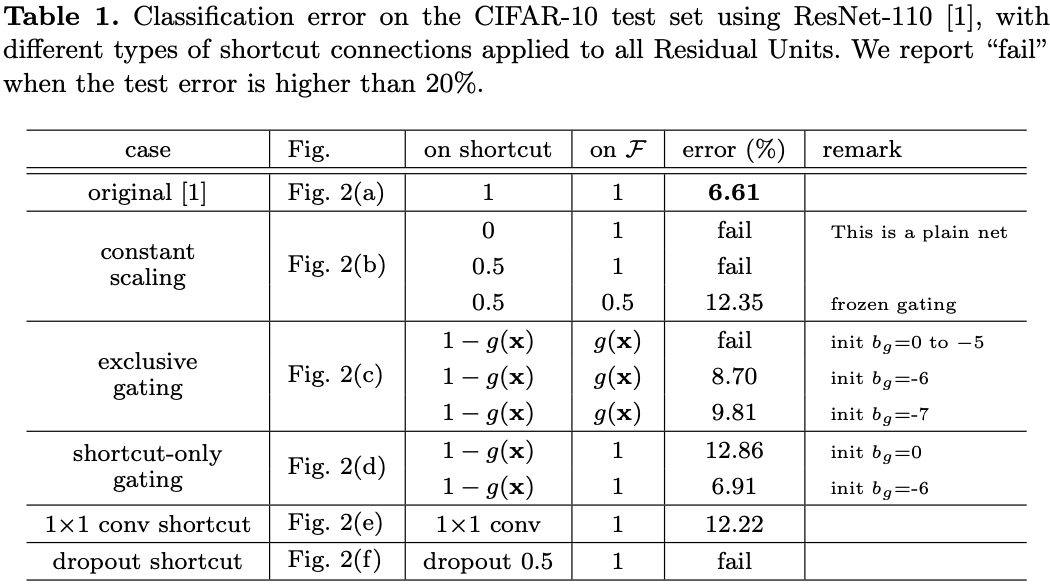
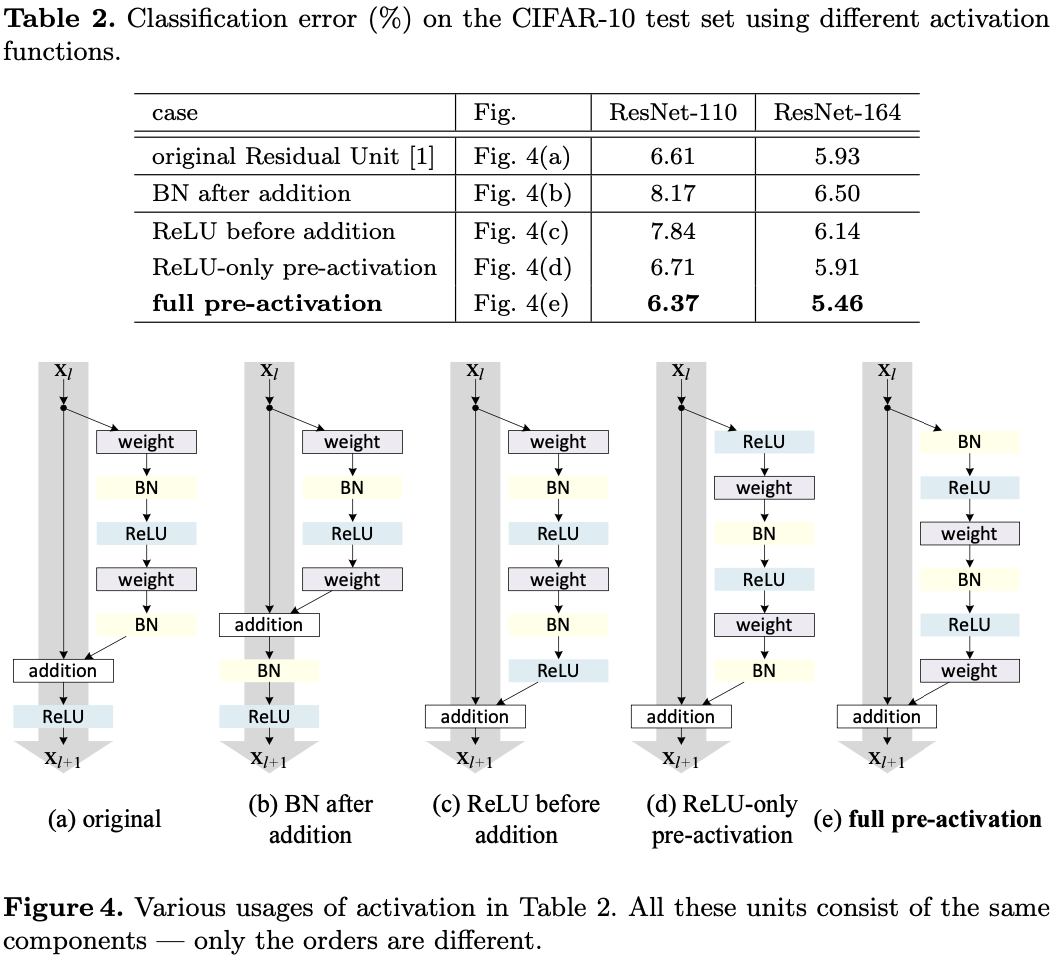
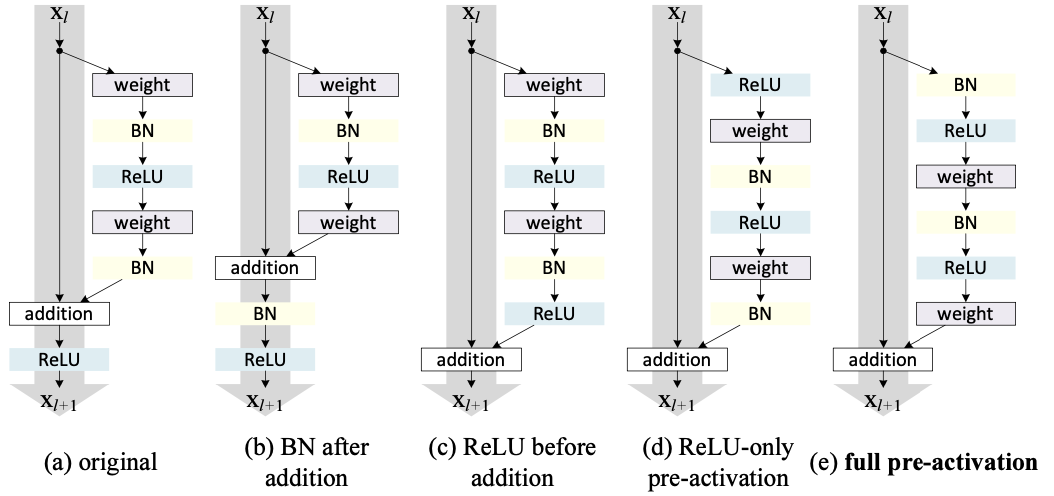
이 Section에서는 ResNet-110과 164층의 Bottleneck Architecture(ResNet-164라고도 함)으로 실험한다.
Bottleneck Residual Unit은 다음과 같이 구성된다. 차원축소를 위한 1×1 및 3×3 layer 차원복원을 위한 1×1 layer 이는 [ResNet논문]에서의 설계방식처럼 계산복잡도는 2개의 3×3 Residual Unit과 유사하다. (자세한 내용은 부록에 기재) 또한, 기존의 ResNet-164는 CIFAR-10에서 5.93%의 결과를 보였다.(표2)
•BN after addition
•ReLU before addition
•Post-activation or Pre-activation ?
4.2 Analysis
•Ease ofoptimization
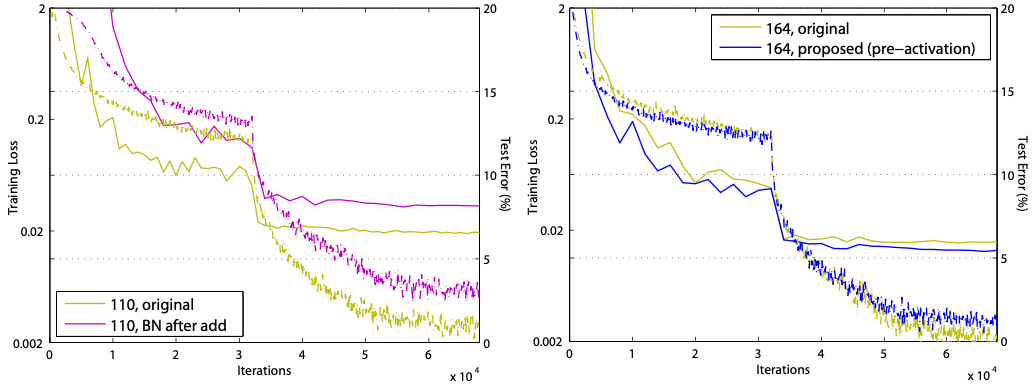
- 이 효과는ResNet-1001을 훈련할 때 매우 두드러진다. (그림1의 곡선.) [ResNet논문]의 기존 설계방식으로 훈련을 시작하면 training Loss가 매우 느리게 감소한다. f =ReLU가 음의 값을 경우, 신호에 영향을 미치는데 이는 Residual Unit이많으면 이 효과가 두드러진다. 즉, Eqn.(3)(따라서Eqn.(5))은 좋은 근사치가 아니게 된다. 반면,f가 identity mapping인 경우,신호는 임의의 두 Unit 사이에 직접 전파될 수 있다. 1001층이나 되는 신경망의 training Loss값을 매우 빠르게 감소시킨다(그림1). 또한 우리가 조사한 모든 모델 중 가장 낮은 Loss를 달성하여 최적화의 성공을 보여준다.
- 또한ResNet이 더 적은 층을 가질 때f =ReLU의 영향이 심각하지 않다는 것을 발견했다(예:그림6(오른쪽)). 훈련 초반, training곡선이 조금 힘들어 보이지만 곧 좋은 상태로 된다.
그러나 단절(truncation)은1000개의 레이어가 있을 때 더 빈번히 일어난다.
•ReducingOverfitting 제안된 "pre-activation" unit을 사용하는 것이 Regualarizatoin에 미치는 또 다른 영향은 그림 6(오른쪽)과 같다.
"pre-activation" 버전은 수렴 시training Loss값이 약간 더 높지만 "test Error"는 더 낮다.
이현상은CIFAR-10과100모두에서ResNet-110, ResNet-110(1-layer)및ResNet-164에서 관찰된다. 이때, 우리는 이것이 BN의 "regularization" 효과에 의해 발생한 것으로 추정된다.
원래 Residual Unit(그림4(a)에서BN이 신호를 정규화(normalize)하지만,이는 곧 shortcut에 추가되므로 병합된 신호는정규화(normalize)되지않습니다.
이정규화되지않은 신호는 그다음 weight-layer의 입력값으로 사용된다.
대조적으로, 우리의 "pre-activation"버전에서,모든weight-layer의 입력값이정규화되었다.
5. Results
•Comparisons on CIFAR-10/100 - 표 4는 CIFAR-10/100에 대한 최첨단 방법을 비교하여 경쟁력 있는 결과를 얻는다. 우린 신경망 폭이나 filter크기를 특별히 조정하거나 작은 dataset에 매우 효과적인 정규화 기술(예: Dropout)을 사용하지 않는다는 점에 주목한다. 우리는 단순하지만 필수적인 개념을 통해 더 깊이 들어가 이러한 결과를 얻어서 깊이의 한계를 밀어내는 잠재력을 보여준다.
•Comparisons on ImageNet - 다음으로 1000-class ImageNet dataset에 대한 실험 결과이다. ResNet-101을 사용해 ImageNet의 그림 2와 3에서 연구한 skip connection을 사용하여 예비 실험을 수행했을 때, 유사한 최적화 어려움을 관찰했다. 이러한 non-idntity shortcut network의 training오류는 첫 learning rate(그림 3과 유사)에서 기존 ResNet보다 분명히 높으며, 자원이 제한되어 훈련을 중단하기로 결정했다. 그러나 우리는 ImageNet에서 ResNet-101의 "BN after addition" 버전(그림 4(b)을 마쳤고 더 높은 training Loss와 validation error오류를 관찰했다. 이 모델의 단일 크롭(224×224)의 validation error는 24.6%/7.5%이며 기존ResNet-101의 23.6%/7.1%이다. 이는 그림 6(왼쪽)의 CIFAR 결과와 일치합니다.
- 표 5는 모두 처음부터 훈련된 ResNet-152와 ResNet-200의 결과를 보여준다. 우리는 기존 ResNet 논문이 더 짧은 측면 s∈ [256, 480]을 갖는 scale-jittering을 사용하여 모델을 훈련시켰기 때문에 s = 256 ([ResNet논문]에서와 같이)에서 224×224crop의 test는 negative쪽으로 편향되어 있었다.
대신, 모든 기존 및 ResNets에 대해 s = 320에서 단일 320x320 crop을 test한다. ResNets는 더 작은 결과물에 대해 훈련받았지만, ResNets는 설계상 Fully-Convolution이기 때문에 더 큰 결과물에서 쉽게 테스트할 수 있다. 이 크기는 Inception v3에서 사용한 299×299에 가깝기 때문에 보다 공정한 비교가 가능하다.
- 기존 ResNet-152는 320x320 crop에서 top-1 error가 21.3%이며, "pre-activation"은 21.1%이다. ResNet-152에서는 이 모델이 심각한 일반화(generalization) 어려움을 보이지 않았기 때문에 이득이 크지 않다. 그러나 기존 ResNet-200의 오류율은 21.8%로 기존 ResNet-152보다 높다. 그러나 기존 ResNet-200은 ResNet-152보다 training error가 낮은데, 이는 overfitting으로 어려움을 겪고 있음을 시사한다.
"pre-activation" ResNet-200의 오류율은 20.7%로 기존 ResNet-200보다 1.1% 낮고 ResNet-152의 두 버전보다 낮다. GoogLeNet과 InceptionV3의 scale 및 종횡(aspect)의 비율의 확대를 사용할 때, ResNet-200은 Inception v3보다 더 나은 결과를 보인다(표 5). 우리의 연구가 진행될 때와 동시에, Inception-ResNet-v2 모델은 19.9%/4.9%의 single crop 결과를 달성하였다.
• Computational Cost - 우리 모델의 계산 복잡도는 깊이에 따라 선형적이다(따라서 1001-layer net은 100-layer net보다 10배 복잡하다). CIFAR에서 ResNet-1001은 2개의 GPU에서 훈련하는 데 약 27시간이 걸리고, ImageNet에서 ResNet-200은 8개의 GPU에서 훈련하는 데 약 3주가 걸린다(VGGNet논문과 동등).
6. Conclusions
이 논문은 ResNet의 connection메커니즘 뒤에서 작동하는 전파 공식을 조사한다. 우리의 결과물은 identity shortcut connection 및 identity after-addition activation이 정보의 전파를 원활하게 하기 위해 필수적이라는 것을 시시한다. 이런 변인통제실험(Ablation Experimanet)은 우리의 결과물과 일치하는 현상을 보여준다. 우리는 또한 쉽게 훈련되고 정확도를 향상시킬 수 있는 1000층 심층신경망을 제시한다
•Appendix:Implementation Details
🧐 논문 감상_중요개념 핵심 요약
"Identity Mappings in Deep Residual Networks" Kaiming He, Xiangyu Zhang, Shaoqing Ren 및 Jian Sun이 2016년에 발표한 연구 논문으로 이 논문은 심층 신경망의 성능 저하 문제를 해결하는 새로운 잔차 네트워크 아키텍처를 제안한다.
[핵심 개념]
1.기존 ResNet과의 차이점 1. Shortcut Connections 이 논문은 기존의 ResNet에서layer간의 shortcut connection에서 "Identity Mapping"을 사용한다는 것이다. - 기존 ResNet: 다음층의 출력차원과 일치하도록 입력을 변환하는 Residual Mapping을 사용 - ResNet V2: transformation을 우회하고 입력을 다음층으로 직접전파하는 "Identity Mapping"을 사용
2. Pre-activation 이 논문은 ResNet을 응용한 ResNetV2로 사전 활성화(pre-activation)에 대한 개념을 도입했다. - BatchNormalization 및 ReLU를 각 conv.layer이후가 아닌, 이전에 적용한다. - 이를 통해training performance를 개선하고 매우 깊은 신경망에서의 overfitting을 줄여주었다.
[장점 ①_ Easy to Optimization] - 이 효과는 깊은 신경망(1001-layer ResNet)을 학습시킬 때 분명하게 나타난다. 기존 ResNet은 Skip connetion을 거쳐서 입력값과 출력값이 더해지고, ReLU 함수를 거친다. 더해진 값이 음수이면 ReLU 함수를 거쳐서 0이 되는데, 이는 만약, 층이 깊다면 이 증상의 영향이 더 커지게 되어 더 많은 값이 0이 되어 초기 학습시에 불안정성으로 인한 수렴이 되지 않는 문제가 발생할 수 있다. 실제로 아래 학습 곡선을 보면 초기에 Loss가 수렴되지 않는 모습을 볼 수 있다. Bold: test, 점선: train 하지만 pre-activation 구조는 더해진 값이 ReLU 함수를 거치지 않아, 음수 값도 그대로 이용할 수 있게 된다. 실제로 학습 곡선을 살펴보면 제안된 구조가 초기 학습시에 loss를 더 빠르게 감소시킴을 볼 수 있다.
[장점 ②_ Reduce Overfitting] - 위 그림을 보면 수렴지점에서 pre-activation 구조의 training loss가 original보다 높다. - 반면, test error가 낮다는 것은 overfitting을 방지하는 효과가 있다는 것을 의미합니다. - 이 논문에서 이 효과에 대해 Batch Normalization 효과 때문에 발생한다고 추측하는데, Original Residual unit은 BN을 거치고 값이 shortcut에 더해지며, 더해진 값은 정규화되지 않는다. 이 정규화되지 않은 값이 다음 conv. layer의 입력값으로 전달된다. Pre-activation Residual unit은 더해진 값이 BN을 거쳐서 정규화 된 뒤에 convolution layer에 입력되서 overfitting을 방지한다고 저자는 추측한다.
3. Recommendation 이 논문에서는 ResNet V2 설계 및 훈련을 위해 소개된 실용적인 권장사항을 제안하는데, 아래와 같다. ① Initialization - 표준편차 = sqrt(2/n) 인 Gaussian분포를 사용해 Conv.layer weight초기화를 권장 (이때, n은 input channel수)
② Batch Normalization - pre-activation을 이용한 Batch Normalization을 권장한다. - mini-batch의 statistics 영향을 줄이기 위해 training/test중에는 statistics이동평균을 사용한다.
③ Learning Rate Schedule -초기 수렴의 가속화를 위해 warming up구간에서 상대적으로 큰학습률 사용 - 미세조정을 위해decay구간에서 더 작은 학습률사용