- 심층신경망은 "over-parameterized"되거나 "weight_decay. &. dropout"같은 엄청난 양의 noise와 regularize로 훈련될 때, 종종 잘 작동하곤한다. 비록 Dropout이 FC.layer층에서 매우 포괄적으로 사용되는 regularization기법이지만, conv.layer에서 종종 덜 효과적이다. 이런 Conv.layer에서의 Dropout기법의 성공의 결핍은 conv.layer의 activation unit이 "dropout에도 불구하고 공간적 상관관계"가 있기에 정보가 여전히 conv.layer를 통해 흐를 수 있다는 점이다. ∴ CNN의 정규화를 위해 구조화된 형태의 dropout기법이 필요하다!
- 이 구조화된 형태의 dropout기법을 본 논문에서 소개하는데, 바로 Dropout이다. Dropout기법은 특징맵의 인접영역에 있는 units를 함께 Drop시키는 방법을 채택한다. 우린 "skip-connection"에 DropBlock을 적용함으로써 정확도의 향상을 이룩했다. 또한, training시 Drop의 수를 점차 늘리면서 2가지 이점을 얻었다. i) 더 나은 accuracy ii) hyperparameter의 선택의 확고성(robust)
- 수많은 실험에서 DropBlock은 CNN을 규제화하는 데 Dropout보다 더 잘 작동한다. ImageNet에서 DropBlock을 사용하는 ResNet-50 아키텍처는 78.13%의 정확도를 달성하여 기존보다 1.6% 이상 향상되었다. COCO Detection에서 DropBlock은 RetinaNet의 평균 정밀도를 36.8%에서 38.4%로 향상시킨다.
1. 서론 (Introduction)
- 심층신경망은 "over-parameterized(= parameter수가 많은)"되거나 "weight_decay. &. dropout"같은 엄청난 양의 noise와 regularize로 훈련될 때, 종종 잘 작동하곤한다. CNN에서 dropout의 첫등장으로 막대한 성공에도 불구하고, 최근 연구에서 convolutional architectures에서 dropout이 사용되는 경우는 극히 드물다. [BN, ResNet,...등 논문] 대부분의 경우, dropout은 CNN에서 주로 "Fully-Connected layer"에서 메인으로 사용된다.
- 우린 Dropout의 핵심결점이 "drops out featurerandomly"라고 주장한다. 특징을 무작위로 제거하는 것이 FC.layer에서는 좋을 수는 있으나, "공간적 상관관계"가 존재하는 Conv.layer에서는 덜 효과적이다. dropout에도 불구하고, 특징간의 상관관계가 존재한다는 것은 "input정보가 다음층에도 전달된다는 것"이며 이는 신경망의 "overfitting"을 야기할 수 있다. 이런 직관은 CNN의 규제화를 위해 더 구조화된 dropout이 필요하다는 것을 시사한다.
- 본 논문에서, (dropout을 구조화하여 CNN규제화에 부분적으로 효과가 있는) DropBlock에 대해 소개한다. DropBlock에서 block내의 특징, 즉 특징맵의 인접영역이 함께 drop된다. DropBlock은 상관영역의 특징을 폐기(discard)하므로 신경망은 data에 적합한 증거를 다른 곳에서 찾아야한다. (그림 1 참조).
- 우리 실험에서, DropBlock은 다양한 모델과 dataset에서 dropout보다 훨씬 낫다. ResNet-50 에 DropBlock을 추가하면 ImageNet의 Image Classification의 정확도가 76.51%에서 78.13%로 향상된다. COCO detection에서 DropBlock은 RetinaNet의 AP를 36.8%에서 38.4%로 향상된다.
2.Related work
- 서론에서 말했듯, Dropout은 DropConnect, maxout, StochasticDepth, DropPath, ScheduledDropPath, shake-shake regularization, ShakeDrop regularization같은 신경망에 대한 여러 정규화 방법에서 영감을 받었다. 이런 방법들의 기본 원칙은 training data에 overfitting되지 않기위해 신경망에 noise를 추가한다. CNN의 경우, 전술한 대부분의 성공적 방법은 noise가 구조화되어야 한다는 것이다. 예를 들어, DropPath에서 신경망의 전체 계층은 특정 단위뿐만 아니라 훈련에서 제외된다. 이러한 dropping out layer의 전략은 입출력 branch가 많은 계층에 잘 적용될 수 있지만 branch가 없는 계층에는 사용할 수 없다. cf) "block"을 conv.layer내의 인접한 특징맵의 집합으로 정의하고 "branch"를 동일한 공간 해상도를 공유하는 연속된 block의 집합으로 정의한다.
우리의 방법인 DropBlock은 CNN의 모든 곳에 적용할 수 있다는 점에서 더 일반적이다. 우리의 방법은 전체 channel이 특징맵에서 drop되는 SpatialDropout과 밀접한 관련이 있기에 우리의 실험은 DropBlock이 SpatialDropout보다 더 효과적이라는 것을 보여준다.
- Architecture에 특정된 이런 noise주입 기술의 개발은 CNN에만 국한되지 않는다. 실제로 CNN과 유사하게 RNN은 자체적인 noise의 주입방식을 필요로 한다. 현재, Recurrent Connections에 noise를 주입하는 데 가장 일반적으로 사용되는 방법 중 두 가지가 있는데, 바로 Variational Dropout과 ZoneOut이다.
- 우리의 방법은 입력 예제의 일부가 영점 처리(zeroed out)되는 데이터 증강 방법인 Cutout에서 영감을 얻었다. DropBlock은 CNN의 모든 특징맵에서 Cutout을 적용하여 Cutout을 일반화한다. 우리의 실험에서, training 중 DropBlock에 대해 고정된 zero out비율을 갖는 것은 훈련 중 zero out비율이 증가하는 schedule을 갖는 것만큼 강력하지 않다. 즉, 교육 중에는 초기에 DropBlock 비율을 작게 설정하고, 교육 중에는 시간이 지남에 따라 선형적으로 증가시키는 것이 좋으며, 이 scheduling 체계는 ScheduledDropPath와 관련이 있다.
3. DropBlock
- DropBlock은 dropout과 비슷한 간단한 방법이지만, dropout과의 주된 차이점은 Dropout: dropping out independent random unit DropBlock: drops contiguous regions from a feature map of a layer DropBlock은 2가지의 주요 parameter가 있다. i) block_size : drop할 block의 크기 ii) 𝛾 :얼마나 많은 activation units를 drop할 것인지 우리는 서로 다른 feature channel에 걸쳐 공유된 DropBlock mask를 실험하거나 각 feature channel에 DropBlock 마스크를 지니게 한다. Algorithm 1은 후자에 해당하며, 이는 우리의 실험에서 더 잘 작동하는 경향이 있다.
Dropout과 유사하게 우리는 추론시간중 DropBlock을 적용하지 않는데, 이는 기하급수적으로 크기가 큰 하위신경망의 앙상블에 걸쳐 평균예측을 평가하는 것으로 해석된다. 이런 하위신경망은 각 신경망이 각 특징맵의 인접한 부분을 보지 못하는 Dropout으로 커버되는 특별한 하위신경망의 하위집합을 포함한다.
• Setting the value of block_size
•Setting the value of 𝛾
•Scheduled DropBlock
4. Experiments
다음 Section에서는 Image Classification, Object Detection 및 Semantic Segmentation에 대한 DropBlock의 효과를 경험적조사를 진행한다. Image Classification을 위한 광범위한 실험을 통해 ResNet-50에 DropBlock을 적용한다. 결과가 다른 아키텍처로 전송가능여부의 확인을 위해 최첨단 모델인 AmoebaNet에서 DropBlock을 수행하고 개선 사항을 보여준다. Image classification 외에도, 우리는 DropBlock이 Object Detection 및 Semantic Segmentation을 위한 RetinaNet을 훈련하는 데 도움이 된다는 것을 보여준다.
4.1 ImageNet Classification
ILSVRC 2012 classification dataset - train: 1.2M , valid: 5만 , test: 15만, 1000-class label 이미지에는 1,000개의 범주가 레이블로 지정됩니다. [GoogLeNet, DenseNet]처럼 training하기 위해 horizontal flip, scale, 종횡비율확대를 사용했다. evaluation에서 multiple crop대신, single crop을 적용했다. 일반적 관행에 따라 검증 세트에 대한 분류 정확도를 보고한다.
우리는 모든 모델에 대해 - 기본 image size (ResNet-50의 경우 224 x 224,AmebaNet의 경우 331 x 331) - batch size (ResNet-50의 경우 1024,AmebaNet의 경우 2048) - 및 하이퍼 파라미터 설정을 적용했다. 우린 단지 ResNet-50 아키텍처에 대한 training epoch을 90개에서 270개로 늘렸을 뿐이다. 학습률은 125, 200, 250 epoch마다 0.1배 감소했다.
AmebaNet 모델은 340epoch 동안 훈련되었으며 학습률스케줄링을위해 지수decay체계가 사용되었다. 기존의 모델은 일반적으로 더 긴 training scheme으로 인해 overfitting되어서 훈련이 종료되면 validation accuracy가 낮다. 따라서 공정한 비교를 위해 전체 training과정에 걸쳐 가장 높은 validation accuracy를 보고한다
4.1.1 DropBlock in ResNet-50
ResNet-50은 이미지 인식을 위해 널리 사용되는 CNN아키텍처이다. 다음 실험에서, 우리는 ResNet-50에 다른 규제화 기술을 적용하고 결과를 DropBlock과 비교한다. 결과는 표 1에 요약되어 있다.
•Where to apply DropBlock ResNet에서 building block은 몇 개의 conv.layer와 identity mapping을 수행하는 별도의 skip-connection으로 구성된다. 모든 conv.layer는 Batch Normalizatoin layer 및 ReLU activation에 따른다. building block의 출력은 convolution building block의 출력은 convolution branch의 출력과 skip connection 출력의 합이다.
ResNet은 활성화함수의 공간적 해상도에 기초하여 그룹을 구축하여 나타낼 수 있는데, building group은 여러 building block으로 구성된다. 우리는 그룹 4를 사용해 ResNet의 마지막 group(즉, conv5_x의 모든 layer)을 나타낸다.
다음 실험에서는 ResNet에서 DropBlock을 적용할 위치를 연구한다. ① conv.layer이후에만 DropBlock을 적용하거나 ② conv.layer와 skip-connection 둘 모두 뒷부분에 DropBlock을 적용하는 실험을 했다. 다양한 특징 그룹에 적용되는 DropBlock의 성능을 연구하기 위해 그룹 4 또는 그룹 3과 그룹 4 모두에 DropBlock을 적용하는 실험을 했다.
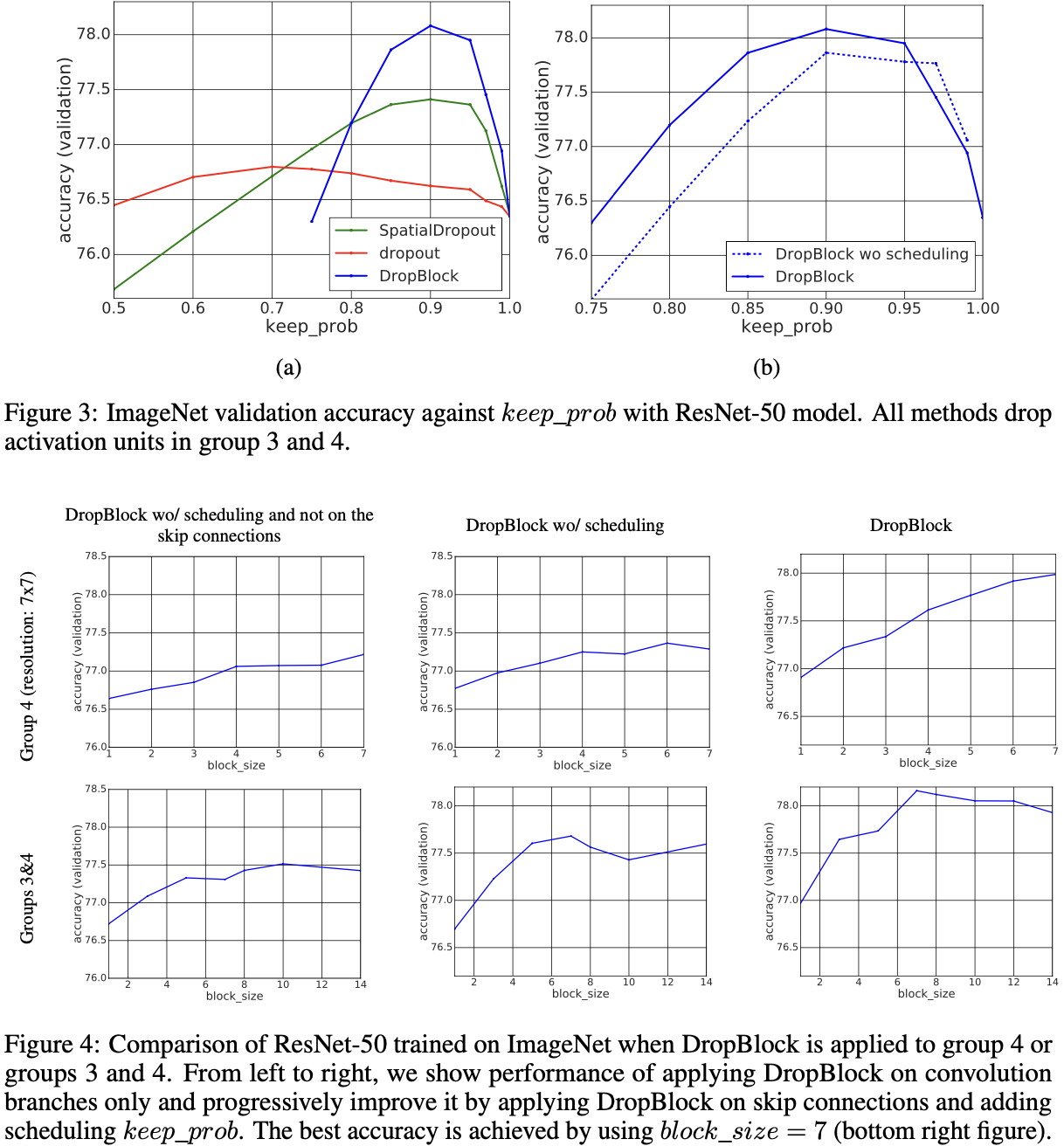
•DropBlock. vs. dropout 원래 ResNet 아키텍처는 모델의 Dropout을 적용하지 않는다. 다만 논의의 용이성을 위해 기존 ResNet의 Dropout을 convolution branch에만 dropout을 적용하는 것으로 정의한다. 기본적으로block_size= 7로 그룹 3과 4 모두에 DropBlock을 적용한다. 우리는 모든 실험에서 그룹 3에 대해 parameter𝛾를4만큼감소시켰다. 그림 3-(a)에서, 우리는 top-1 accuracy에서 DropBlock이 1.3%로 Dropout을 능가한다는 것을 보여준다. reservedkeep_prob는 DropBlock을keep_prob의 변경에 더 강력하게 만들고 keep_prob(3-(b))의 가장 많은 값에 대한 개선을 추가한다.
그림 3에서 최고의keep_prob를 통해 발결한 점은 바로block_size가 1에서 전체 특징맵을 포함하는block_size로 바뀌었다는 것이다. 그림 4는 일반적으로 1의block_size를 적용하는 것보다 큰block_size를 적용하는 것이 더 낫다는 것을 보여주며 최상의 DropBlock 구성은block_size= 7을 그룹 3과 4에 모두 적용하는 것입니다.
모든 구성에서 DropBlock과 Dropout은 유사한 추세를 공유하며 DropBlock은 최상의 Dropout 결과에 비해 큰 이득을 보입니다. 이것은DropBlock이Dropout에 비해 더 효과적인 규제화 도구라는 증거를 보여준다.
•DropBlock. vs. SpatialDropout 기존의 Dropout과 유사하게, 우리는 기존의 SpatialDropout기법이 convolution branch에만 적용하는 것으로 정의한다. SpatialDropout기법은Dropout기법보다는 낫지만 DropBlock다는 떨어진다. (즉, DropBlock >SpatialDropout > Dropout) 그림 4에서 그룹 3의 고해상도 특징맵에 적용할 때,SpatialDropout기법이 너무 가혹할 수 있음을 발견했다. DropBlock은 그룹 3과 그룹 4 모두에서 일정한 크기의 Block을 Drop하여 최상의 결과를 달성합니다.
•Comparision withDropPath Scheduled DropPath기법에서 "skip-connection"을 제외한 모든 연결에 Scheduled DropPath를 적용했습니다. 우리는keep_prob매개 변수에 대해 다른 값으로 모델을 훈련시켰으며, 모든 그룹에서 DropPath를 적용하고 그룹 4 또는 그룹 3과 그룹 4에서만 다른 실험과 유사한 모델을 훈련시켰다. keep_prob= 0.9인 그룹 4에만 적용했을 때 77.10%로 최상의 validation accuracy를 달성했다.
•Comparision with Cutout 또한 데이터 증강 방법 중 하나인 Cutout기법과 비교하여 입력 이미지에서 고정 크기 블록을 무작위로 떨어뜨렸다. Cutout기법은 Cutout논문에서 제안한 대로 CIFAR-10 dataset의 정확도향상을 되지만, 우리 실험에서 ImageNet dataset의 정확도를 향상시키지는 않는다.
•Comparision with other regularization techniques 우리는 DropBlock을 일반적으로 사용되는 2가지 regularization기술(data augmentation, label smoothing)과 비교한다. 표 1에서 DropBlock은data augmentation, label smoothing에 비해 성능이 우수하다. DropBlock과 label smoothing 및 290epoch training을 결합하면 성능이 향상되어 규제화 기술이 더 오래 훈련할 때, 보강이 될 수 있음을 보여준다.
4.1.2DropBlock in AmoebaNet
-또한 진화적구조의 search를 사용하여 발견된 최신 architecture는AmoebaNet-Barchitecture에서 DropBlock의 효과를 보여준다. 이 모델은 0.5의 keep probability로 dropout하지만 최종 softmax층에서만 dropout된다.
- 우린모든 Batch Normalization층 후에 DropBlock을 적용하고 또한마지막셀의 50%에 Skip-Connection에도 적용한다. 이러한 셀에서 특징맵의 해상도는 331x331 크기의 입력 이미지에 대해 21x21 또는 11x11이다. 마지막 Section의 실험을 기반으로, 우리는0.9의keep_prob를 사용하고 마지막 특징맵의 width인block_size= 11을 설정했다. DropBlock은AmoebaNet-B의 top-1 accuracy를 82.25%에서 82.52%로 향상시킨다(표 2).
4.2 Experimental Analysis
DropBlock은드롭아웃에비해ImageNet classification정확도를 향상시키는 강력한 경험적 결과를 보여준다.
우리는conv.layer의 인접 영역이 강하게 상관되어 있기 때문에Dropout이충분하지 않다고 가정한다. unit을임의로 떨어뜨려도 인접 unit을 통해 정보가 흐를 수 있기 때문이다.
이Section에서는DropBlock이 semantic정보를 삭제하는 데 더 효과적이라는 것을 보여주기 위해 분석을 수행한다.
결과적으로,DropBlock에 의해 규제화된모델은Dropout에의해규제화된모델에 비해 더 강력하다.
우리는추론 중,block_size가1과7인DropBlock을 적용하고 성능의 차이를 관찰하여 문제를 연구한다.
• DropBlock drops more semantic information
먼저 규제화 없는 훈련된 모델을 가져와서block_size= 1및block_size = 7을 사용하여DropBlock으로테스트했다. 그림5의 녹색 곡선은 추론 중에keep_prob가 감소함에 따라 validation accuracy가 빠르게 감소함을 보여준다.
이것은DropBlock이 semantic정보를 제거하고 분류를 더 어렵게 한다는 것을 시사한다.
정확도는 DropBlock이dropout보다 semantic정보를 제거하는 데 더 효과적이라는 것을 시사하는block_size= 7과 비교하여block_size= 1에 대해keep_prob가 감소할수록 더 빠르게 떨어진다.
• Model trained with DropBlock is more robust
다음으로 우리는 더 많은 의미 정보를 제거하는 큰 블록 크기로 훈련된 모델이 더 강력한 정규화를 초래한다는 것을 보여준다.
우리는추론 중에block_size= 7과 적용된block_size= 1로 훈련된 모델을 취함으로써 그 사실을 입증하고 그 반대도 마찬가지이다.
그림5에서block_size= 1과block_size = 7로 훈련된 모델은 모두 추론 중에block_size = 1이 적용된 상태에서 견고하다.그러나block_size = 1로 훈련된 모델의 성능은 추론 중에block_size = 7을 적용할 때keep_prob가 감소함에 따라 더 빠르게 감소했다.
결과는block_size = 7이 더 강력하고block_size = 1의 이점이 있지만 그 반대는 아님을 시사한다.
DropBlock으로훈련된 모델은DropBlock이 인접한 영역에서 semantic정보를 제거하는 데 효과적이다. 따라서 공간적으로 분산된 표현을 학습해야 한다고 가정한다.
DropBlock에 의해규제화된모델은 하나의 독자적 영역에만 초점을 맞추는 대신 여러 독자적 영역을 학습해야 한다.
우리는ImageNet validation set에서ResNet-50의conv5_3클래스 activation을 시각화하기 위해 클래스 활성화 맵(CAM)을 사용한다.
그림6은block_size = 1및block_size = 7인DropBlock으로훈련된 기존모델과 모델의 클래스 activation을 보여준다.
일반적으로DropBlock으로훈련된 모델은 여러 영역에서 높은 클래스 activation을 유도하는 공간적으로 분산된 표현을 학습하는 반면,규제화가 없는 모델은 하나 또는 매우적은 수의 영역에 초점을 맞추는 경향이 있다.
4.3 Object Detection in COCO
DropBlock은 CNN을 위한 일반적인 regularization 모듈이다. 이 Section에서는 DropBlock이 COCO dataset의 training object detector에도 적용될 수 있음을 보여준다. 우리는 실험에 RetinaNet을 사용하며, image에 대한 single label을 예측하는 image classification과 달리, RetinaNet은 multi-scale Feature Pyramid network(FPN)에서 convolution으로 실행되어 다양한 스케일과 위치에서 object를 localizatoin하고 분류한다. [Focal loss for dense object detection]의 모델 아키텍처와 anchor 정의를 따라 FPN과 classifier/regressor의 branch들을 구축했다.
• Where to apply DropBlock to RetinaNet model RetinaNet 모델은 ResNet-FPN을 백본 모델로 사용한다. 단순성을 위해 ResNet-FPN의 ResNet에 DropBlock을 적용하고 ImageNet classification 훈련에 대해 찾은 최상의keep_prob를 사용한다. DropBlock은 지역 제안(region proposal)의 특징에 구조화된 패턴을 drop하는 방법을 배우는 최근 연구[A-Fast-RCNN]과는 다르다.
• Training object detector from random initialization 무작위 초기화에서 object detector를 훈련하는 것은 어려운 작업으로 간주되어 왔다. 최근, 몇몇 논문들은 새로운 모델 아키텍처, 큰 mini-batch size 및 더 나은 normalization layer를 사용하여 이 문제를 해결하려고 시도했다. 우리의 실험에서, 우리는 모델의 규제화 관점에서 문제를 살펴본다. training image classification model과 동일한 hyper parameter인keep_prob = 0.9로 DropBlock을 시도하고 다른 block_size로 실험했다. 표 3에서 무작위 초기화에서 훈련된 모델이 ImageNet으로 사전 훈련된 모델을 능가한다는 것을 보여준다. DropBlock을 추가하면 1.6%의 AP가 추가되는데, 그 결과는 모델 규제화가 Object Detector를 처음부터 훈련시키는 중요한 요소이며 DropBlock은 물체 감지를 위한 효과적인 규제화 접근법임을 시사한다. • Implementation details 우리는 실험을 위해 RetinaNet3의 오픈 소스 구현을 사용한다. 모델은 64개의 이미지를 한 batch동안 처리하여 TPU에 대해 훈련되었다. 교육 중에 multi-scale jittering을 적용해 scale간의 image sizewhwjd gn ekdma image를 최대차수 640으로 padding/crop을 진행. 테스트하는 동안 최대 차수는 640의 singel-scale image만 사용되었다. Batch Normalization층은 classifier/regressor branch를 포함한 모든 conv.layer 이후에 적용되었다.
모델은 150 epoch(280k training step)을 사용해 훈련되었다. 초기 학습률 0.08은 처음 120 epoch에 적용되었고 120 epoch과 140epoch에 0.1씩 감소했다. ImageNet 초기화를 사용한 모델은 16 및 22 epoch에서 learning decay와 함께 28 epoch에 대해 훈련되었다. 초점 손실에는 α = 0.25와 𝛾 = 1.5를 사용했다. weight_decay =0.0001. &. 0.9의 momentum = 0.9 이 모델은 COCO train 2017에서 훈련되었고 COCO val 2017에서 평가되었다.
4.4 Semantic Segmentation in PASCAL VOC
-우리는 DropBlock이 semantic segmentation모델도 개선한다는 것을 보여준다. PASCAL VOC 2012 데이터 세트를 실험에 사용하고 일반적인 관행을 따라 증강된 10,582개의 training이미지로 훈련하고 1,449개의 testset 이미지에 대한 mIOU를 보고한다. 우리는semantic segmentation를 위해 오픈 소스 RetinaNet 구현을 채택한다. 구현은 ResNet-FPN backborn 모델을 사용하여 multi-scale feature를 추출하고 segmentation을 예측하기 위해 Fully-Convolution Network를 상단에 부착한다. 우리는 훈련을 위해 오픈 소스 코드의 default hyper-parameter를 사용한다.
- Object Detection실험에 이어 random initialization에서 훈련 모델에 대한 DropBlock의 효과를 연구한다. 우리는 45개의 epoch에 대해 pre-trained ImageNet 모델로 시작한 모델과 500개의 epoch에 대해 무작위 초기화된 모델을 훈련시켰다. ResNet-FPN backborn 모델과 Fully-Convolution Network에 DropBlock을 적용하는 실험을 수행했으며Fully-Convolution Network에 DropBlock을 적용하는 것이 더 효과적이라는 것을 발견했다. DropBlock을 적용하면 처음부터 교육 모델에 대한 mIOU가 크게 향상되고 ImageNet 사전 교육 모델과 무작위로 초기화된 모델의 교육 간 성능 격차가 줄어든다.
5. Discussion
- 이 논문에서, CNN의 training regularize기법인 DropBlock을 소개한다. DropBlock은 공간적으로 연관된 정보를 drop하는 구조화된 dropout기법이다. ImageNet, COCO detection에 dropout과 DropBlock을 비교함으로써 더욱 효과적인 규제화기법임을 증명하였다. DropBlock은 광범위한 실험 설정에서 지속적으로 드롭아웃을 능가한다. 우리는 DropBlock으로 훈련된 모델이 더 강력하고 드롭아웃으로 훈련된 모델의 이점을 가지고 있음을 보여주기 위해 분석을 수행하였으며, class activation mapping은 모델이 DropBlock에 의해 정규화된 더 많은 공간적으로 분산된 표현을 학습할 수 있음을 시사한다.
- 우리의 실험은 conv.layer외에 "skip-connection"에 DropBlock을 적용하면 정확도가 증가한다는 것을 보여준다. 또한 훈련 중에 삭제된 unit의 수를 점진적으로 증가시키면 정확도가 향상되고 hyper-parameter선택에 더욱 강력해진다.
🧐 논문 감상_중요개념 핵심 요약
"DropBlock: A regularization method for convolutional networks"
[핵심 개념]
Dropout은 딥러닝에서 널리 사용되는 regularization방법이지만 구조적 특성으로 인해 CNN에서는 제대로 작동하지 않을 수 있다.
DropBlock은 CNN용으로 특별히 설계된 정규화 방법이다. 개별 단위 대신 교육 중에 기능 맵의 전체 연속 블록을 무작위로 삭제하여 작동합니다.
DropBlock 방법은 개별 픽셀 대신 인접한 블록을 드롭(contiguous block drop)하는 공간적 드롭아웃 방법의 일반화로 볼 수 있다.
DropBlock은 CIFAR-10, CIFAR-100 및 ImageNet을 포함한 여러 dataset에서 CNN의 일반화 성능을 향상시켰다.
DropBlock은 기존 CNN구조에 쉽게 통합될 수 있으며 "weight_decay" 및 "data augmentation"같은 다른 "regularization"방법과 함께 사용할 수 있다.
또한 학습 중 신경망에서 연결의 전체 경로를 무작위로 drop하는 유사한 정규화 방법인 "drop-path"의 개념을 도입했다.
전반적으로 DropBlock 방법은 CNN을 위해 특별히 설계된 강력하고 효과적인 정규화 기술로 여러 벤치마크dataset에서 네트워크의 일반화 성능을 개선하는 것으로 나타났으며 기존 아키텍처에 쉽게 통합할 수 있다.