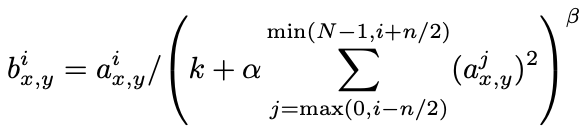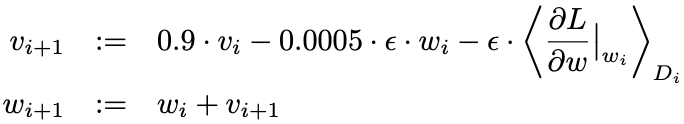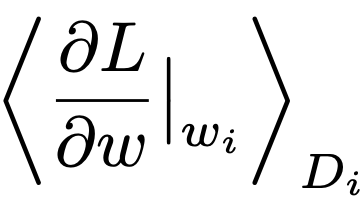- ImageNet에서 120만개의 고해상도 image를 대상으로 1000개의 클래스를 분류하는 문제에 대해 좋은 결과를 내었음
- 6000만개의 parameter와 650,000여개의 뉴런 [5개의 CONV 층(maxpool), 3개의 FullyConnected 층(마지막은 1000개 클래스를 구분하는 softmax층)]으로 구성 - training을 빨리 하기 위해 포화되지 않은(non-saturating) 뉴런들과 효과적인 GPU를 사용 - overfitting을 줄이기(reduce)위해 dropout(매우 효과적으로 증명된 regularized method)을 사용
- ILSVRC-2012 대회에서 2등인 26.2%에 비해 15.3%의 error rate를 성취하였음 (Imagenet Large-scale Visual Recognition Challenge)
1. 서론 (Introduction)
- 현재 사물인식에서 기계학습(machine learning)방식의 사용은 필수적이다. - 이를 위해 다음과 같은 방법으로 향상을 시키는데, 더 많은 데이터셋, 강력한 모델 및 더 좋은 과적합을 막는 기술등이 있다. 과거, MNIST와 같은 데이터들은 적은 양으로도 가능하였지만 현실에서는 상당히 다양하며(considerable variablility) 따라서 더 많은 training set을 필요로 하는 것은 필수불가결한 사항이 되어버렸다.
- 수많은 사물을 구분하려면 많은 학습능력을 지녀야 한다. 하지만, 사물인식의 거대한 복잡도의 문제는 ImageNet같은 거대한 dataset에서 명시될 수 없다는 점이다.
- 학습능력은 depth와 breadth를 다양화하면서 조정할 수 있는데, feedforward neural network와 비교했을 때, CNN은 더 적은 연결과 parameter를 갖기에 train하기 쉽고 이론적으로 최상의 효과를 약간의 단점만으로 낼 수 있다.
2.The Dataset
- ImageNet을 이용했는데, ImageNet은 22,000개의 카테고리, 1500만개의 라벨링된 고해상도의 사진으로 이루어져 있다. - 따라서 image를 down-sample하여 해상도를 256X256으로 맞춰 image를 rescale하였다. - raw RGB의 pixel로 train을 진행하였다.
3.The Architecture
3.1 ReLU Nonlinearity
- Deep CNN에서 tanh unit의 사용보다 ReLU의 사용이 훨씬 빠르다는 것을 알 수 있다. 이런 빠른 학습은 큰 데이터셋을 갖는 large한 모델에 매우 훌륭한 영향을 준다. 위 그림에 대한 설명이다. - 실선: 4개의 Conv층 (with relu), 6배 더 빠르다. - 점선: 4개의 Conv층 (with tanh) - ReLu는 지속적인 학습의 진행으로 saturating neuron보다 더 빠르게 학습한다. 우리는 여기서 미리 포화된(large neural net)뉴런 모델을 굳이 경험할 필요가 없음을 알 수 있다.
3.2 Training on Multiple GPUs
-single GTX 580 GPU 코어는 메모리가 3GB이기에 훈련가능한 신경망의 최대크기가 제한된다. - 따라서 2개의 GPU에 신경망을 흩어뜨리는GPU병렬화(parallelization scheme)를 이용한다. -이때, 2개의 GPU net이 1개의 GPU net보다 훈련에 더 적은 시간이 걸리고 오류율도 1.2~1.7%정도 감소시켰다.
3.3 Local Response Normalization
- ReLU는 포화(saturating)방지를 위한 입력 정규화를 필요로 하지 않는 바람직한 특성을 갖는다. - ReLU는 local 정규화 일반화에 도움이 된다.
- 위의 식은 다음과 같이 해석된다.
kernel i의 위치 (x,y)를 적용해 계산된 뉴런의 activity이다. 여기에 ReLU의 비선형성을 적용한다.
이때, 합은 동일한 공간위치에서 n개의 '인접한(adjecent)' kernel map에 걸쳐 실행된다. (N은 layer의 총 kernel수) kernel map의 순서는 training이 시작하기 전에 임의로(arbitrary) 결정된다. 이런 반응정규화(response normalization)의 종류는 영감을 받은(inspired) 측면억제(lateral inhibition)형태를 구현, 이를 통한 다른 커널의 사용으로 계산된 뉴런 출력간의 large activity에 대한 경쟁(competition)을 생성한다.
상수 k, n, α, β는 validation set을 사용하여 값이 결정되는 hyper-parameter로 각각k = 2, n = 5, α = 10-4, β = 0.75를 사용하며 특정 layer에서 ReLU의 비선형성을 적용한 후 이 정규화를 적용했다(3.5 참조).
Jarrett의 local contrast normalization과 비슷하지만 mean activity를 빼지(subtract)않았기에 우리의 이 정규화를 'brightness normalization'이라 더 장확하게 부를 것이다.
3.4 Overlapping Pooling
CNN에서의 pooling layer는 동일한 kernel map에서 '인접한(adjacent)' 뉴런 그룹의 output을 summarize한다. 보편적으로 adjacent pooling으로 요약되면 unit들이 겹치지 않는다. 즉,pooling layer는 픽셀들 사이에 s만큼의 간격을 둔 pooling unit들의 grid로 구성되며, 각각은 pooling unit의 위치를 중심으로 한 크기(zxz)의 neighbor를 요약한다. 만약위에서의 s를 s = z로 설정하면 CNN에서 일반적으로 사용되는 보편적인 local pooling을 얻을 수 있으며, s < z를 설정하면 overlapping pooling을 얻을 수 있다.
이때문에 전반적인 신경망에서 s=2나 s=3으로 사용하는 것이다. 또한 일반적인 training에서는overlapping pooling이 있는 모델이 모델을 과적합하기가 약간 더 어렵다는 것을 알 수 있다
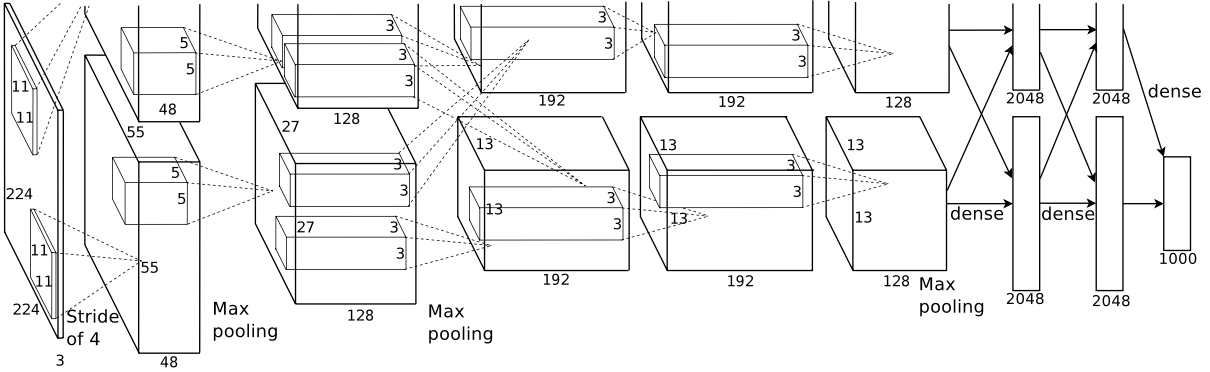
3.5 Overall Architecture
총 8개의 weight를 갖는 layer로 구성되어 있다. - 5개의 CONV (convolution layer) -3개의 FC (Fully-connected layer) + 마지막은 1000개의 클래스를 구분하는 softmax층
이 모델은 다항식 logistic regression 분석목표를 최대화 하는데, 이는 예측분포(prediction distribution)하에서 올바른 label의 log확률(log-probability)의 training cases에 대한 평균(average)을 최대화하는 것과 같다.
2, 4, 5번째의 CONV의 kernel은 동일한 GPU에 있는 이전 layer의 kernel map에만 연결된다. (아래그림 참조) 3번째 CONV는 2번째 CONV의 모든 kernel map들과 연결되며 완전히 연결된 층의 뉴런은 이전 층의 모든뉴런들과 연결된다.
response-normalization층들은 1, 2번째 CONV를 따르며 3.4절에 기술된 종류의 MaxPooling은 response-normalization layer와 5번째 CONV layer를 모두 따른다.
ReLU의 비선형성은 모든 CONV와 FC의 출력에 적용되며 첫 번째 CONV은11×11×3의 96개의 kernel을 가지며 224×224×3(150,528 차원)의 input image를 stride=4로 filtering을 진행한다. (신경망의 뉴런수는 다음과 같다. 150,528-253,440–186,624–64,896–64,896–43,264–4096–1000)
2번째 CONV는 첫번째 CONV의 출력을 입력으로 받아5×5×48의 256개의 kernel로 filtering을 진행하며 3번째 CONV는3×3×256의 384개의 kernel을 두번째 CONV output과 연결하고 4번째 CONV는 3×3×192의 384개의 kernel로, 5번째 CONV는3×3×192의 256개의 kernel로 filtering하며 3, 4, 5번째 CONV는 어떠한 간섭(intervening)pooling과 normalization layer없이 서로 연결된다.
또한 FC (Fully-Connected layer)는 각각 4096개의 뉴런을 갖는다.
4.Reducing Overfitting
4.1 Data Augmentation
① image translation. &. horizontal reflection - image translation: 한 도메인의 입력 이미지를 다른 도메인의 해당 이미지로 변환하는 것 - 이 방법을 통해 train에 상호의존적일 수 있고 이런 scheme이 없었다면 overfitting의 어려움을 겪었을 것이다.
② altering intensities of the RGB channels - ImageNet의 training set 전체의 RGB픽셀값에 PCA를 수행 - 각 train image에 해당 eigenvalues(고유값)에 비례하는 크기와 평균 0, 표준편차 0.1을 갖는 zero-mean Gaussian 분포(정규분포)에서 도출된 random변수를 곱해 나온 주요 구성요소의 배수를 추가한다. - 따라서 RGB 픽셀 Ixy =[IR , IG , IB ]T에 아래 값을 추가한다. - 이때, pi와 yi는 각각 RGB pixel의 3x3 covariance(공분산)행렬의 i번째 eigenvector와 eigenvalue이며 αi는 이전에 설명한 random 변수이다. 각 αi는 해당 이미지가 다시 훈련에 사용될 때까지 특정 훈련 이미지의 모든 픽셀에 대해 한 번만 그려지며, 이 시점에서 다시 그려진다.
4.2 Dropout
- Dropout은 전진의 기여도를 없애고 역전파를 관여하지 못하게 하는 방식으로 많고 다른 뉴런들의 부분집합을 random하게 결합시키는데 유용하다. - 0.5의 비율로 FC의 처음 2개의 layer에 적용하였으며 dropout이 없으면 상당한 과적합을 보여주었다.
<-- wi에서 평가된 w의 미분(derivative)의 i번째 batch Di의 평균으로 Loss function의 기울기을 의미한다.
<초기화> 표준편차가 0.01인 zero-mean Gaussian 분포로 각 층의 weight를 초기화 2,4,5 CONV층과 FC층은 상수 1로 , 나머지 층은 0으로 bias를 초기화 validation error가 개선되지 않으면 학습율을 10으로 나눔 (0.01로 초기화 하였으며 종료전에 3배정도 감소하였음)
6.Results
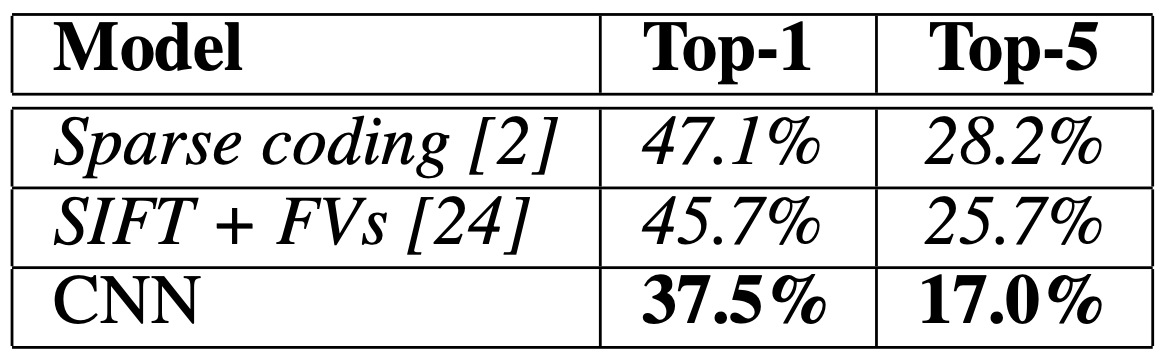
- ILSVRC-2010에 대한 결과의 요약은 다음과 같다. 신경망은 37.5%와 17.0%5의 상위 1위와 상위 5위의 테스트 세트 오류율을 달성하는 것을 볼 수 있다.
ILSVRC-2010 경쟁에서 달성된 최고의 성능은 서로 다른 기능에 대해 훈련된 6개의 spase coding 모델에서 생성된 예측을 평균화하는 접근 방식으로 47.1%와 28.2%였다. 그 이후 가장 잘 발표된 결과는 Fisher Vectors (FVS)에 대해 훈련된 두 분류기의 예측을 평균화하는 접근 방식으로 45.7%와 25.7%였으며 두 가지 유형의 조밀하게 샘플링된 특징으로부터 계산되었다.
- 또한 ILSVRC-2012 대회에서의 결과는 다음과 같다. 단락(paragraph)의 나머지 부분에서는 검증 및 테스트 오류율이 0.1% 이상 차이가 나지 않기 때문에 서로 교환하여 사용한다.
이 논문에서 설명한 CNN은 다음과 같은 성과를 거두었다 상위 5위 이내의 오류율 18.2%. 5개의 유사한 CNN의 예측을 평균하면 16.4%의 오류율을 얻었다.
- 마지막 pooling layer에서 추가적으로 6차 컨볼루션 레이어가 있는 CNN 하나를 교육하여 ImageNet Fall 2011 release (15M images, 22K categories)를 분류한 다음 ILSVRC-2012에서 "미세 조정(fine-tuning)"하면 16.6%의 오류율을 얻을 수 있다. 앞서 언급한 5개의 CNN으로 2011년 가을 전체 릴리스에서 사전 훈련된 2개의 CNN의 예측을 평균하면 15.3%의 오류율을 얻을 수 있다. 두 번째로 우수한 콘테스트 항목은 다양한 유형의 조밀하게 샘플링된 기능에서 계산된 FV에 대해 훈련된 여러 분류기의 예측을 평균화하는 접근 방식으로 26.2%의 오류율을 달성했다.
- 마지막으로, 우리는 또한 10,184개의 범주를 가진 Fall 2009 version of ImageNet에 대한 오류율을 보고한다 그리고 890만 장의 이미지가 있는데, 이 dataset에서 우리는 학습을 위해 이미지의 절반을 사용하고 테스트를 위해 이미지의 절반을 사용하는 문헌의 관례를 따른다. 확립된 testset이 없기 때문에, 우리의 분할은 반드시 이전 저자들이 사용한 분할과 다르지만, 이것은 결과에 크게 영향을 미치지 않으며 이 dataset에서 상위 1위와 상위 5위의 오류율은 67.4%와 40.9%이며, 위에서 설명한 순으로 달성되나 마지막 pooling layer에 비해 6번째 컨볼루션 계층이 추가된다. 이 데이터 세트에 대한 가장 잘 알려진 결과는 78.1%와 60.9%이다.
6.1 Qualitative Evaluations
이 그림은 신경망의 두 data-connected layer에 의해 학습된 Convolution kernel을 보여준다. 신경망은 다양한 frequency 및 orientation-selective kernels 뿐만 아니라 다양한 색상 blob들을 사용한 것 또한 알 수 있다.
3.5에서 설명한제한된 연결의 결과로 두 GPU가 보여주는 전문화에 주목한다. GPU 1의 커널은 대부분 색상에 구애받지 않는 반면 GPU 2의 커널은 대부분 색상에 따라 다르기에이러한 종류의 전문화는 모든 실행 중에 발생하며 특정 random weight 초기화(GPU의 모듈로 번호 변경)와 무관하다.
위 사진의왼쪽은 다음과 같다. - 8개의 테스트 이미지에 대한 상위 5개 예측을 계산하여 신경망이 무엇을 배웠는지 정성적으로 평가(qualitatively assess)한다. - 이때, 진드기(mite)같이 중심을 벗어난 물체도 net로 인식할 수 있다는 점을 유의해야 한다. (상위 5개의 label은 대부분 합리적인 것으로 보인다.)
위 사진의오른쪽은첫 번째 열에 5개의 ILSVRC-2010 테스트 영상으로나머지 열은 테스트 이미지의 특징 벡터로부터 유클리드 거리(Euclidean distance)가 가장 작은 마지막 숨겨진 레이어에서 특징 벡터를 생성하는 6개의 훈련 이미지를 보여준다.
- 두 이미지가 작은 Euclidean separation으로 특징 활성화 벡터(feature activation vectors)를 생성할 때, 신경망의 고수준이 유사하다 간주한다고 할 수 있다.
- 그림은 testset의 5개 이미지와 이 측정에 따라 각 이미지와 가장 유사한 training set의 6개 이미지를 보여주는데, 픽셀 수준에서 검색된 교육 이미지는 일반적으로 첫 번째 열의 query image의 L2에서 가깝지 않다. 예를 들어, 회수된 개들과 코끼리들은 다양한 포즈로 나타나며 우리는 보충 자료에서 더 많은 train image에 대한 결과를 제시한다.
- 두 개의 4096차원 실제 값 벡터 사이의 Euclidean distance 사용하여 유사성을 계산하는 것은 비효율적이지만, 이러한 벡터를 짧은 이진 코드로 압축하도록 auto-encoder를 훈련시킴으로써 효율적으로 만들 수 있다. 이는 image label을 사용하지 않기에 의미적으로(semantically) 유사한지 여부에 관계없이 edge들과의 유사한 패턴을 가진 이미지를 검색하는 경향이 있는 raw-pixel에 auto-encoder를 적용하는 것보다 훨씬 나은 이미지 검색 방법을 생성해야 한다.
7. Discussion
- 크고 깊은 CNN이 기록을 깨는 좋은 결과를 내는 것을 알 수 있다. - 또한 중간층을 일부 삭제하더라도 성능이 떨어지는 것을 알 수 있듯, 깊이가 정말로 우리의 결과를 이룩하는데 중요하다는 것을 알 수 있다.
- 실험을 단순화하기 위해, 특히 label이 지정된 데이터의 양에서 그에 상응하는 증가를 얻지 않고 신경망의 크기를 크게 늘릴 수 있는 충분한 계산 능력을 얻는 경우에 도움이 될 것으로 예상했음에도 불구하고 unsupervised pre-training을 사용하지 않았다.
🧐 논문 감상_중요개념 핵심 요약
"ImageNet Classification with Deep Convolutional Neural Networks" Alex Krizhevsky, Ilya Sutskever 및 Geoffrey Hinton이 2012년에 발표한 연구 논문으로 이 논문은 2012년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 최첨단 성능을 달성한 AlexNet이라는 심층 합성곱 신경망을 제안한다.
[핵심 개념]
1. Convolutional Neural Networks Convolutional 및 Subsampling 층의 여러 layer로 구성된 Deep CNN Architecture와 Fully-Connected layer를 제안한다.
2.Rectified Linear Units(ReLU) 이 논문은 Sigmoid 및 tanh와 같은 기존 활성화 함수보다 더간단하고 효율적인 ReLU 활성화 함수의 소개 및 활용을 진행한최초의 논문이기에 더욱 중요하다고 볼 수 있다.
3. Local Response Normalization(LRN) 이 논문은 일종의 측면 억제(lateral inhibition)를 제공하여 일반화 성능을 개선하는 데 도움이 되는LRN이라는 정규화 유형을 제안한다.
4. Dropout 이 논문은 과적합을 방지하기 위해 훈련 중에 일부 뉴런을 무작위로 제거하는 드롭아웃이라는 정규화 기술을 소개하였다.
5. Data Augmentation 이 논문은 training set의 크기를 늘리고 model의 견고성을 늘ㄹ리기 위해random crop, vertical flip같은 기술을 사용했다.
6. State-of-the-Art Performance (최신 성능) 이 논문은 ILSVRC 2012 분류 작업에서 최신 성능을 달성하여 이전 방법보다 훨씬 뛰어난 성능을 보여준다.
전반적으로 이 논문은Convolution신경망, ReLU 활성화 함수 및 데이터 증강의 사용과 같은 딥 러닝의 몇 가지 중요한 개념을 소개하고 까다로운 컴퓨터 비전 작업에서 최첨단 성능을 달성하는 데 있어 그 효과를 입증했다.
🧐 논문을 읽고 Architecture 생성 (withtensorflow)
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense, Dropout
def AlexNet(input_shape, num_classes):
input_layer = Input(shape=input_shape)
# first convolutional layer
x = Conv2D(96, kernel_size=(11,11), strides=(4,4), padding='valid', activation='relu')(input_layer)
x = MaxPooling2D(pool_size=(3,3), strides=(2,2))(x)
x = Dropout(0.25)(x)
# second convolutional layer
x = Conv2D(256, kernel_size=(5,5), strides=(1,1), padding='same', activation='relu')(x)
x = MaxPooling2D(pool_size=(3,3), strides=(2,2))(x)
x = Dropout(0.25)(x)
# third convolutional layer
x = Conv2D(384, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu')(x)
x = Dropout(0.25)(x)
# fourth convolutional layer
x = Conv2D(384, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu')(x)
x = Dropout(0.25)(x)
# fifth convolutional layer
x = Conv2D(256, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu')(x)
x = MaxPooling2D(pool_size=(3,3), strides=(2,2))(x)
x = Dropout(0.25)(x)
# flatten the output from the convolutional layers
x = Flatten()(x)
# first fully connected layer
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
# second fully connected layer
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
# output layer
output_layer = Dense(num_classes, activation='softmax')(x)
# define the model with input and output layers
model = tf.keras.Model(inputs=input_layer, outputs=output_layer)
return model
model = AlexNet(input_shape=(224,224,3), num_classes=1000)
model.summary()