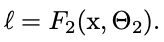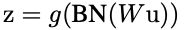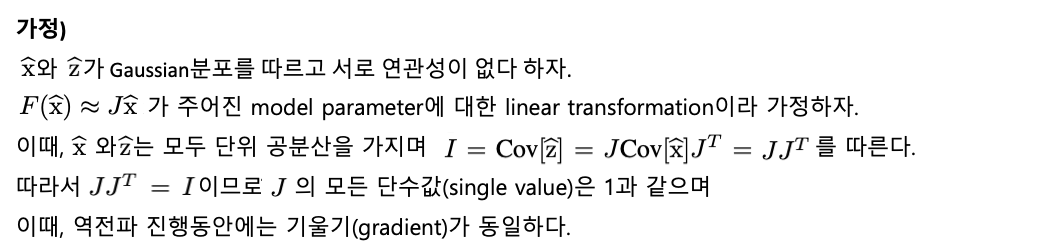- Deep Neural Net의 training은 "각 층의 input과 parameter가 변한다" 는 점에서 매우 복잡하다는 것이 정론이다. - 낮은 학습율, 조심스런 parameter 초기화로 인해 training을 느리게 만들고 포화 비선형성(saturating nonlinearity)으로 인해 model train을 악명높게 만든다. - 우리는 위와 같은 현상을internal covariate shift라 부르며, 이런 문제를 input layer를 normalizing을 통해 다룬다.
- 우리의 방법은 model 구조의 일부의 normalization과 for each training mini-batch에 normalization을 적용함을 통한 Batch-Normalization을 통해 더 높은 learning rates와 초기화에 대해 덜 신경 쓸 수 있도록 하는 그런 강점을 이끌어 내었다. - Batch-Normalization은 또한 regularizer의 역할도 할 수 있는데, 어떠한 경우에는 Dropout의 필요성을 없애주었다.
- BN(Batch Normalization)의 앙상블의 사용으로 ILSVRC에서 최상의 결과를 얻었으며 더 조금의 training step으로 같은 결과에 도달할 수 있었다.
1. 서론 (Introduction)
- 딥러닝에서 SGD는 매우 효과적인 훈련방법으로 증명되었는데, SGD의 변형(momentum, Adagrad)들은 예술의 경지라 할 만하다. - SGD는 loss를 최소화하기 위해 x1..N의 training data set에서 신경망의 parameterΘ를 최적화 한다. - SGD의 이용시 training의 과정 및 각 step의 과정에서 크기 m의 mini-batch x1...m에 대해 생각해보자. mini-batch는 parameter의 계산에 관한 loss function의 gradient값을 추정하곤 한다. • mini-batch의 사용은 몇몇 장점이 있다. ①mini-batch에 대한 loss의 기울기(gradient) = 배치가 증가하면서 품질이 향상되는 training set에 대한 기울기의 추정치이다. ②둘째, 현대 컴퓨팅 플랫폼이 제공하는 병렬 처리로 인해 배치를 통한 계산은 개별 예제에 대한 m값 계산보다 훨씬 더 효율적일 수 있다.
- 이런 SGD는 간단하면서 효율적이지만 hyper-parameter, 특히 learning rate와 관련하여 세밀한 조정이 필요하다. 작은 변화라 해도 깊이가 깊어질수록 그런 변화들이 증대되기(amplify) 때문이다.
- layer들이 새로운 분포에 지속적으로 적응할 필요가 있어서 layer의 input의 분포(distribution)변화는 문제를 제시한다. 학습입력분포의 변화는 covariate shift(공변량 이동)을 경험하는데, 이는 보통 domain adaptation으로 해결한다. 다만, covariate shift의 개념은 sub-network(하위 신경망)나 layer가 동일한 부분에 적용해야 한다. 이로 인해 learning system이 전체를 넘어서 확장될 수 있다. F1과 F2가 임의의 transformation이고, Loss를 최소화하기 위해 parameter Φ1, Φ2가 학습되는 신경망의 계산을 생각해보자. 학습 Φ2는 입력 x = F1(u, Φ1)이 sub-network에 공급되는 것(fed into)처럼 볼 수 있다. 예를 들어 경사하강단계에서 (batch size m .&. learning rate α) input x가 있는 독립실행형 신경망 F2의 경우와 정확하게 동등다. 따라서 train과 test data간의 동일한 분포를 갖는 것처럼 train을 더 효율적으로 만드는 input 분포의 속성(property)은 sub-network training에도 적용된다. 그래서 x의 분포는 시간이 지나게 되면 고정된 상태를 유지하는 것이 유리하다. 그러므로 Φ2는 x의 분포 변화를 보상하기 위해 재조정할 필요가 없다.
• z = g(Wu + b) ( g(x)는 sigmoid 1 / 1+exp(-x)함수, u는 input, b는 bias )에 대해 g'(x) = exp(x) / (exp(x)+1)^2으로 x의 절대값이 증가할 수록 0으로 수렴하는데, 이로 인해 gradient vanishing이 발생해 train이 느려진다. 이때, x=Wu + b에서 x는 아래층 parameter에 영향을 많이 받아 train중 parameter의 변경은 x의 많은 차원을 "비선형성의 포화상태(saturated regime of the nonlinearity)"로 만들고 수렴을 느리게 만든다. 이런 영향은 depth가 깊어질수록 증대되는데, 실제로 포화문제와 gradient소실문제를 다루기 위해 Rectified Linear Units(ReLU(x) = max(x,0))과 신중한 초기화, 작은 learning rates를 이용한다.
- 다만 입력값의 비선형성의 분배(non-linearity distribution)는 신경망의 훈련을 더 안정적으로 할 것이며 optimizer가 포화될 가능성이 적게 하고 훈련을 가속화 할 것을 확신할 수 있다. (Rectified Linear Unit (ReLU) activation이 신경망의 비선형성(non-linearity)을 만들 수 있다!)
• Internal Covariate Shift (내부 공변량 이동) - training과정에서 심층신경망의 내부 노드 분포의 변화를 내부 공변량 이동이라 하며 이를 제거하면 training을 빠르게 할 가능성이 있다. - 이를 위한 새로운 기술을 도입하는데, 이것이 바로 BN, Batch-Normalization으로 내부공변량이동을 줄여줘 심층신경망에서 매우 극적으로 training을 가속화시킬 수 있다.
- layer의 입력값의 평균(means)과 분산(variance)을 고정함으로 이를 달성한다. - Batch Normalization의 추가적인 이점은 바로 신경망에서의 gradient flow이다. - 이는 발산(divergence)의 위험성없이 더 높은 learning rate의 사용을 허용하게 한다. - 또한, BN은 model을 규제화(regularize)하고 Dropout의 필요성을 줄여준다. 즉, 신경망의 포화상태에 고착되는 것을 막아줌으로 포화 비선형성(saturating nonlinearity)을 가능하게 해준다.
cf.
non-linearity는 선형이 아닌 수학적연산을 말하며 이는 출력이 입력에 비례하지 않음을 의미. (선형적이면 입력에 비례하기 때문)
이는 출력에 적용되는 활성화함수를 통해 도입된다.
[Saturation]
- input이 증가해도 함수의 output이 포화되거나 특정값에 "고정"되는 현상
- 활성화함수 입장에서 포화는 일반적으로 input이 극단적으로 크거나 작을 때 발생한다.
- 이로 인해 input과 관계없이 일정한 값을 출력하게 하여 기울기가 매우 작아지는(gradient vanishing) 문제가 발생한다.
- 결과적으로 신경망에서 학습속도를 늦추거나 방해할 수 있다.
[Saturating non-linearity]
- 포화를 나타내는 활성화함수로 sigmoid, tanh함수가 대표적인 포화 비선형성(saturating non-linearity)예시이다.
- ReLU 및 그 변형 활성화함수는 포화를 나타내지 않아 비포화 비선형성(non-saturating non-linearity)라 부른다.
[linearity]의 종류
Identity Function: f(x) = x
Constant Function: f(x) = c (c는 상수., 상수함수)
Polynomial Function: f(x) = an x^n + a{n-1} x^{n-1} + ... + a1 x + a0 (an, a{n-1}, ..., a0가 모두 상수값)
Linear Regression: y = b1 x + b0 (b0과 b1가 상수값)
Affine Function: f(x) = a x + b (a 와 b 가 상수값)
2.TowardsReducingInternalCovariate Shift
- Internal Covariate Shift는 training시 신경망의 parameter를 바꿀 때 발생한다. - 따라서 training의 향상을 위해서는 내부공변량이동을 줄여야 한다.
•Whitening
- layer의input feature를 조정하고평균(means)과 단위분산(unit variance)가 0이 되게 하는 정규화(normalization) 기술로 training수렴이 빨라진다. - input을 whitening함으로써 BN은 각 계층에 대한입력 분포(input distribution)를 안정화하는 데 도움이 될 수 있으므로 신경망이 입력 분포의 변화에 덜 민감해지고 더 빠르고 안정적으로 수렴할 수 있다. - 또한 다른 뉴런과 activation 사이의 공분산을 줄여 신경망을 정규화(regularize)하는 데 도움이 되고 일반화 성능을 향상시킬 수 있다. -이런 whitening은신경망을 즉시 수정하거나optimization algorithm의 parameter를 바꾸는 것으로 고려될 수 있다.
하지만 이런 수정이 optimization단계와 같이 분산되면 경사하강 시 update할 normalization을 선택해 gradient의 효과를 줄이는데, 다음 예시를 통해 설명한다. bias b를 추가하고 train data로 계산된 활성화 평균을 뺀 결과를 정규화하는 input u를 갖는 layer에 대해: x_hat = x - E[x]에서 x = u + b, X = {x1...N}은 training set에 대한 x의 집합이고 E[x] = (1/N)Σ N i=1 xi, 이다. 경사하강단계가 b에 대한 E[x]의 의존성을 무시할 때, b ← b + ∆b를 update한다. (∆b ∝ −∂l / ∂x_hat일 때.) 그렇게 되면 u+(b+∆b)−E[u+(b+∆b)] = u+b−E[u+b]이다.
따라서 b로의 update와 그에 따른 noramlization의 변화의 조합은 layer의 output의 변화, loss를 초래하지 않았다. training이 계속될수록 b는 loss값이 고정된 상태에서 무한히(indefinitely) 커질 것이다. 이 문제는 정규화가 activation의 중심일 뿐만아니라 scale조정 시 더 악화될 수 있다는 점이다. normalization parameter가 경사하강단계시 외부에서 계산되면 모델이 터져버린다.
이 문제의 해결을 위해 모든 parameter값에 신경망이 항상 원하는 분포로 activation을 생성하려 하는데, 이는 모델의 parameter 변수에 대한 loss 기울기(gradient)가 normalization을 설명하고 모델 parameter Θ에 대한 의존성을 설명할 수 있다.
x = layer input X = training data에 대한 이런 input 집합 이에 대해 Normalization은 다음과 같이 작성된다. 이때, 정규화식은 training 예제인 x 뿐만 아니라 모든 예제인 X에 의존하게 되며 x가 다른층에 의해 생성될 때, 각각의 예제는 Θ에 의존하게 된다. 역전파를 위해 Jacobians를 계산해야 하며 이는 아래와 같다. 입력 x, X에 대한 gradient를 계산하는데 필요한 편미분함수이때, 후자(X에 대한 편미분함수)를 무시하면 위에서 설명한 것처럼 exploding을 초래한다. 여기서 layer input을 whitening하려면 공분산 행렬
와 그 역 제곱근을 계산해 다음과 같은 whitening activation
과 역전파를 위한 transform의 미분값을 생성해야하기 때문에 비용이 많이 든다.
- 이는 다른 대안을 찾게 만드는데, input normalization의 성능은 전체 training set의모든parameter update이후에 대한 분석을 필요로 하지 않는데, 이는 우리로 하여금 전체 training data에 대해 trianing과정 중 activation의 normalization을 통한 신경망정보의 보존을 하도록 하였다.
3. NormalizationviaMini-Batch Statistics
각 layer입력부의 full whitening은 비용이 많이들고 모든곳에서 구별할 수 있는 것이 아니기 때문에 2가지 중요한 단순성을 만들었다. ① layer의 input과 output을 긴밀하게 하기위해 feature를 whitening하는 대신, N(0, 1)의 normalization을 각 scalar feature에 독립적으로 정규화시킨다. - d차원의 input x = (x1 . . . xd)에 대해 각 차원을 정규화(normalize)하면 다음과 같다. (이때, E는 Expectation, Var는 Variance로 training dataset에 대해 계산된 값) - LeNet(LeCun et al., 1998b)에서 보였듯 normalization은 수렴속도를 높여준다. 이때, 간단한 정규화는 각 층의 입력부가 바뀔 수 있는데, 예를 들면 sigmoid input의 정규화(normalization)의 경우, 비선형성의 상황을 linear하게 만들 수도 있다. 이를 다루기 위해 우린 "신경망에 삽입된 transformation이 transform의 성질을 나타낼 수 있다(
the transformation inserted in the network can represent the identity transform
)"라는 것을 확신할 수 있다. - 이를 위해 각 activation을 x(k), parameter쌍을 γ(k), β(k)라 할 때, 정규화된 값의 scale과 shift는 다음과 같다. 이 parameter들은 기존모델parameters와 함께 학습되며 신경망의 표현력을 회복시킨다. - batch 설정에서 전체를 정규화한 activation으로 할 때, SGD의 사용은 비현실적(impractical)이어서 두번째 단순화를 만들었다.
②training에서 SGD를 이용해 mini-batch의 사용으로 각 mini-batch는 각 activation의 평균과 분산의 추정치를 생성한다. 이런 통계로 normalization의 사용은 gradient 역전파에 전체적으로 관여한다. - 주목할 점은 mini-batch의 사용은 공동의(joint) covariance보다 차원별 분산의 계산을 통해 가능하다는 점이다. in the joint case, (singular covariance행렬들의 결과에서) whiten된 activation의 수보다 mini-batch size가 더 작기 때문에 regularization이 필요하다.
- 크기가 m인 mini-batch 𝛣에 대해 생각해보자. 각 activation은 독립적으로 normalization이 적용되며 부분activation x(k)에 집중해보자. (이때, 명확성(clarity)을 위해 k는 생략한다.) [Batch Normalizing Transform의 Algorithm] ⲉ는 수치적안정성(numerical stability)를 위해 mini-batch의 분산에 도입된 상수이다.
•numerical stability - training시,loss함수의 기울기는 Back propagation으로 계산된다. (부분도함수의 다중연결계산이 포함됨) - 이 계산은 많은 수를 포함하기에gradient vanishing/exploding같은수치적 불안정성으로optimization이 어렵거나 불가능할 수 있다. (소수점 이하와 같은 수치계산시의 오차, 부정확성을 최소화 하기 위한 개념) -Batch Normalization은 중간층의 activation을 normalize하여 training중의 수치적 안정성을 향상시키는 기술로 도입되었다. (이 논문에서는 SGD를 사용해 신경망을 훈련시키는 부분에서의 수치적 안정성의 중요성을 말한다.) - Activation scale을 줄여 BN은 gradient vanishing, exploding을 방지해 더 안전하고 효율적인 training이 가능해졌다. - 또한 bias를 사용하지 않음을 통해 수치계산의 오차를 최소화 할 수도 있다. (다만, 성능저하의 우려로 인해 성능과 수치적 안정성간의 적절한 균형이 필요하다.) [numerical instability with. overfitting] - 수치적 불안정성은 overfitting으로 이어질 수 있는데, 예를들어기울기가 매우 커지거나 작아지면 optimization이 불안정해지고 overfitting이 발생할 수 있다. - 또한 수치적 불안정성으로수치계산이 부정확해지면 최적의 값으로의 수렴이 되지 않아overfitting발생이 가능하다. - 다만 model의 복잡도, train data의 불충분 및 노이즈로 overfitting이 수치적불안정성이 없어도 발생가능하다.
- BN transform은 activation을 조정하기 위해 도입될 수 있다. 이런 값의 분포는 Expectation 0과 1의 분산값을 갖는것 뿐만 아니라 각각의 mini-batch의 원소들이 우리가 ⲉ를 무시한다면 같은 분포로 부터 표본이 나오는데, 이는 아래와 같은 expectation 즉, 기댓값에서 관찰가능하다. training에서 transformation과정을 통해 나온 loss의 기울기 ℓ에 대해 backpropagation을 진행하고 BN transformation의 parameter에 대한 gradient(기울기)를 계산할 필요가 있다. 이때, chain rule을 사용해 아래와 같이 단순화 한다. 즉, BN transformation은 정규화된 activation을 신경망에 전하는 차별화된(differentiable) tranformation이다. 이는 model training에서 layer가 internal covariate shift가 적은 입력분포로 학습을 계속함을 통해 학습을 가속화한다는 것을 확신하게 해준다. 또한 이런 정규화된 activation에 적용되어 학습(learn)된affine transformation은 BN transformation이 identity transformation을 나타내게 하며 신경망의 수용력을 보존한다.
3.1 Training and Inference with Batch-Normalized Networks
-Batch Normalization 신경망을 위해 우린 activation의 부분집합을 특정해야하고 그 각각에 대해 BN transform을 Algorithm. 1.을 이용해 집어넣어야 한다. - 일전에 x를 입력으로 받은 모든층은 이제 BN(x)로 표기한다. - BN을 사용하는 모델은 [BGD || mini-batch size m > 1인SGD || Adagrad(Duchi et al., 2011)]같은 변형(variants)을 사용해 훈련할 수 있다. - mini-batch에 의존하는 activation의 정규화는 효과적인 training을 허용하지만, 추론(inference)에서 필요하지도, 바람직하지도 않는데 우리의 output이 결과적으로 input값에만 의존하기를 원하기 때문이다.
3.2 Batch-Normalized Convolutional Networks
-Batch Normalization은 신경망의 모든 activation집합에 적용할 수 있기에 우리는 요소별(element-wise) 비선형성을 따르는 affine transformation으로 구성된 transform에 초점을 맞춘다.
W와 b는 학습된 매개변수이고 g(.)는 (sigmoid, ReLU같은)비선형성함수(saturating nonlinearity)이다. 이 식은 FC층과 convolution층 모두 적용되는데, 비선형성 전에 x =Wu + b를 정규화 함을 통해 바로 BN transform을 추가해줬다. 더불어 input u도 정규화할 수 있었지만 u는 다른 비선형성의 출력일 가능성이 높아 분포가 training과정에서 바뀔 수 있기에 첫번째와 두번째 moment를 제한하는 것만으로는 공변량이동을 제거하지 않을 것이다.
- 그와는 대조적으로Wu + b는 대칭적이고 희소하지않은 분포를 가질 가능성이 더 높으며, 이는 "more Gaussian (Hyva ̈rinen & Oja, 2000)"으로; 이 분포를 정규화하면 안정적인 분포의 activation이 될 가능성이 높다.
- 따라서 이에대해 주목할 점은, 우리가Wu + b를 정규화하기에bias b의 효과는 후속 평균의 차에 의해 취소될 것이기에무시될 수 있다. 이때, bias의 역할은 Algorithm. 1.의β에 의해 가정된다. 따라서z = g(Wu + b)는 다음과 같이 BN transformation이 x =Wu의 각 차원에 독립적으로 적용되는 방식으로 아래와 같이대체된다. (이때, 각 차원에는 학습된매개 변수 γ(k), β(k)라는 별도의 쌍이 존재한다.)
- conv.layer에서 우린 convolution의 속성을 복종시키기 위해 normalization을 사용하는데, 그래서 동일한 특징맵의 다른위치에 있는 다른 원소들이 동일한 방식으로 정규화된다. 이를 달성하기 위해 우린 모든 위치의 mini-batch의 activation을 긴밀하게 연결한다.
- Algorithm.1.에서, 우린𝜝가 mini-batch의 요소와 공간위치 모두에 걸쳐 특징맵의 모든 요소의 집합이 되게 한다. - 따라서 크기가 m인 mini-batch와pxq크기의 특징맵의 경우, 크기가m' = |𝜝| =m · pq인 효과적인 mini-batch를 사용한다.
- 우린 activation당이 아닌, feature map당 parmeter변수 쌍인γ(k)와 β(k)를 학습한다. - Algorithm.2.가 비슷하게 수정되었는데, 추론하는동안 BN transform은 주어진 특징맵의 각 activation에 동일한 linear transformation을 적용한다.
- 전통적인 심층신경망에서,너무 높은 학습율은 poor local minima에 갇히는 것 뿐만 아니라 기울기 소실/폭발을 야기했다. - Batch Normalization은이런 문제를다루는 것을 도와준다. - 신경망을 거친 activation을 정규화함으로써 parameter에 대한 작은 변경이 activation의 기울기를 더 크고 최적의 변화로 증폭되는 것을 방지하는데, training이 비선형성의 포화상태에 갇히는 것을 방지하는것이 바로 그 예시이다.
- 또한 BN은 training에서 parameter부근을 더 회복력 있게 만드는데, 보통large learning rate는 parameter의 규모를 증가시켜 gradient 역전파에서 model의 폭발을 초래한다. 하지만Batch Normalization과 함께라면 layer에서의 Back Propagation은 parameter의 규모면의 영향을 받지 않는다.
이때, Scale은 Jacobian layer나 결과적으로 gradient 전파에 영향을 미치지 않는다. 게다가 가중치가 클수록 기울기가 작아지고 BN은 parameter의 성장(growth)을 안정화한다. 또한 Batch Normalization이 layer Jacobian이 training에 유리한 것으로 알려진 1에 가까운 단수값(singular value)을 갖도록 할 수 있다고 추측한다.(Saxe et al., 2013) 실제로 transformation은 선형적이지 않고 정규화된 값이 Gaussian분포이거나 독립적이라는 보장은 없다. 하지만, 그럼에도 불구하고 Batch Normalization이 gradient propagation을 더 잘 작동시킬 것이라 믿는다.
- gradient propagation(기울기 전파)에 대한 Batch Normalization의 정확한 영향은 추가적인 연구로 남아있다.
3.4 Batch Normalization regularizes the model
-Batch Normalization으로 training할 때, training예제는 mini-batch의 다른 예시들과 함께(conjunct) 표시되며, training 신경망은 더 이상 주어진 training 예제에 대한 결정적인 값을 생성하지 않는다. 이 효과는 신경망의 일반화(generalization)에 매우 이점을 갖는다(advantageous).
- Dropout(Srivastava et al., 2014)이 overfitting을 줄이기 위해 일반적으로 사용되는 방식인 반면에Batch Normalization이 적용된 신경망은 Dropout이 감소되거나 제거될 수 있음을 발견했다.
4.Experiments
4.1 Activations over time
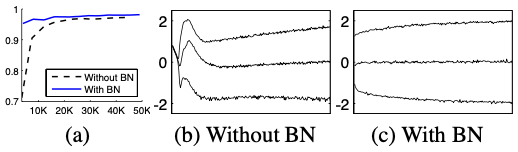
- training에서 internal covariateshift와 이에 대항하는Batch Normalization의 능력을 증명하기 위해 MNIST dataset을 사용. (이때, 28x28의 작은 image를 input으로 3개의 FC-layer와 100개의 activation을 각각 갖는 단순한 신경망을 사용) - 각 층은 sigmoid함수 y = g(Wu + b)를 통해 계산되며, 이때 W는 작은 무작위 Gaussian값으로 초기화된다. - 마지막 층은 FC-layer를 이용해 10개의 activation이며 cross-entropy loss를 사용한다. - Section 3.1에서처럼 신경망의 각 은닉층에 Batch Normalization을 사용한다. - 우리의 주 관심사는 model의 성능보다는 baseline과 BN간의 비교에 중점을 둔다. (a)를 보면, BN을 사용한 것이 더 높은 정확도를 갖는데, 그 이유를 조사하기위해 training과정중의 신경망의 sigmoid에 대해 연구하였다. (b,c)에서 original network(b)는 전반적으로 평균과 분산이 많이 변화하는 반면, BN을 사용한 network(c)의 경우, 분포(distribution)가 안정적임을 볼 수 있는데, 이를 통해 training에 도움을 주는 것을 알 수 있다.
4.2 ImageNet Classification
- 2014년의 Inception network에 Batch Normalization을 적용, 더 자세한 사항은 부록(Appendix)에 기재. - (Sutskever et al.,2013)에 기재된 momentum계수와 32 mini-batch size를 사용 - 이때, 기존의 Inception에 Batch Normalization을 추가한 수정된 모델을 사용하여 evaluate를 진행하였다. - 특히,Normalization은 Conv.layer의 비선형성(non-linearity., ReLU)이 입력부분에 적용하였다. 즉, 코드로 나타내면 다음과 같다는 것을 알 수 있다
• 4.2.1 Accerlerating BN Networks
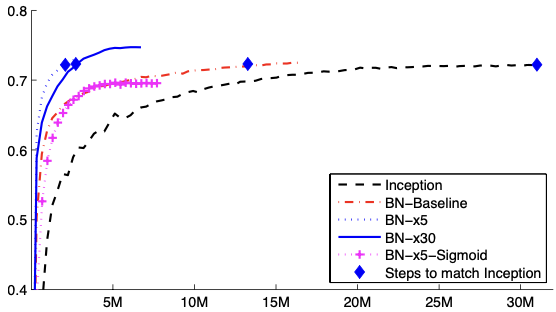
단순히 Batch Normalization을 신경망에 추가한다고 완전한 이점을 주는 것은 아니다. 완전한 이점을 위해신경망 및 training parameter에 대해 다음과 같은 변형이 필요하다. Increase learning rate. - training speed를 높임 Remove Dropout. - Batch Normalization은 Dropout과 동일한 목표를 이행하기 때문 Reduce the L2 weight regularization. -L2 가중치를 줄여서 정확도를 높였음 Accerlerate the learning rate decay. -learning rate의 감쇠율을 기하급수적으로 진행(for train faster) Remove LocalResponseNormalization. -BN의 사용으로LRN의 필요가 없어짐 Shuffle training examples more thoroughly. -철저하게 train예시를 섞음으로mini-batch에서 동일한 예제가 나오는 것을 방지 - Reduce the photometric distortions. -광도측정의 왜곡을 줄여 real image에 집중하게함 (∵ BN신경망은 train faster. &.observe fewer time이기 때문) Inceoption의 Single Crop validation accurarcy 분포로 BN과의 비교를 나타내는 그래
• 4.2.2 Single-Network Classification
Inception. - 처음 learning rate는 0.0015로 초기화하여 train BN-Baseline. - non-linearity이전, Batch Normalization을 적용한 Inception과 동일 BN-x5. -위의 모델에 Section 4.2.1을 적용 - 초기 학습률은 0.0075로 5배 증가시켰으며 동일한 학습률로 기존 Inception의 매개변수가 무한대에 도달하게함 BN-x30. -BN-x5와 동일하지만,초기학습률은 0.045로 Inception의 30배이다. BN-x5-Sigmoid. -BN-x5와 동일하지만, ReLU대신 sigmoid non-linearity를 사용했다.
위의 그림은 4.2.1의 그래프의 Max validation accuracy 뿐만 아니라 72.2%이 정확도에 도달하기까지 걸린 Step에 대한 표이다.
여기서 흥미로운 점은 BN-x30이 다소 초기에는 느렸지만 더 높은 최종 accuracy에 도달했다는 점이다. internal covariance shift의 감소로sigmoid를 비선형성으로 사용할 때, Batch Normalization을 훈련할 수 있다는 것을 증명하였다. (흔히들 그런 신경망 train이 어렵다고 알려진 것에도 불구하고.)
• 4.2.3 Ensemble Classification
BN-x30을 기반을 둔6개의 신경망을 이용해다음과 같은 사항에 집중해 수정하였으며 결과는5. Conclusion의 표를 참고한다. - Conv.layer의 초기 weight를 증가시킴 - Dropout의 사용 (Inception에서 사용하는 40%에 비해5~10%정도만수행) - model의 마지막 은닉층과 함께 non-convolution, activation 당 Batch Normalization을 사용
5.Conclusion
- 기계학습의 training을 복잡하게 만드는 것으로 알려진 Covariate Shift(공변량 이동)은 sub-network와 layer에도 적용되며 network의 내부 활성화에서 이를 제거하면 training에 도움이 된다는 전제(premise)를 기반으로 한다. - Normalization은 network를 train에 사용되고 있는 optimization method를 적절하게 다룰 수 있다. 각각의 mini-batch에 Normalization을 적용하고 normalization parameter를 통한 기울기의 역전파를 위해 SGD를 사용한다.
- network의 결과는 포화비선형(saturating nonlinearity)로 훈련될 수 있고, training rate의 증가에 더욱 관대(tolerant)하며 정규화(regularization)를 위한 Dropout이 필요하지 않은 경우가 많다.
- 최첨단 image classification model에 Batch-Normalization을 추가하는 것 만으로도 training속도를 크게 향상시킬 수 있다.
- learining rate를 높이고 Dropout을 제거하고Batch-Normalization에 의해 제공되는 기타 수정사항을 적용함으로 우리는 적은 training step으로 이전의 첨단기술에 도달하며 이후의 single-network image classification을 능가한다. 또한, Batch-Normalization으로 훈련된 여러 모델들의 결합으로 ImageNet에서 가장 잘 알려진 방법보다 훨씬 우수한 성능을 발휘할 수 있다.
[Batch-Normalization의 목표]
- 훈련 전반에 걸쳐 activation값의 안정적인 분포(distribution)의 달성 -experiments에서출력분포의 1차 모멘트와 2차 모멘트를 일치시키면 안정적 분포를 얻을 가능성이 높다. ∴ 비선형성 전에 Batch-Normalization을 적용시킨다.
- BN의 또다른 주목할 점은 Batch Normalization transform이 동일성(표준화 layer는 개념적으로 필요한 scale과 shift를 흡수하는 learned linear transform이 뒤따르기에 필요하지 않았음)을 나타내도록하는learned scale과 shift, conv.layer의 처리, mini-batch에 의존하지 않는 결정론적 추론, 신경망의 각 conv.layer의 BN이 포함된다.
- 즉, Batch Normalization이 conv.layer를 처리할 수 있고 미니 배치에 의존하지 않는 결정론적 추론을 가지고 있다는 뜻이며 추가적으로 신경망의 각 conv.layer를 정규화한다는 의미이다.
[이번 연구의 문제점 및 향후 목표] BN가 잠재적으로 가능케하는 모든 범위의 가능성을 탐구하지 "않았다." - 따라서 internal covariate shift와 gradient vanishing, exploding가 특히나 심각할 수 있다. - normalization이 gradient propagation을 향상시킨다는 가설을 철저하게 검증하는 방법은 당연히도 말이다. - 우리는 전통적인 의미에서 적용의 부분에 도움이 될 지 [신경망에 의해 수행되는 normalization이 모집단의 평균과 분산의 재계산만으로 새 데이터분포보다 쉽게 일반화 가능한지의 여부]를 조사할 계획이다.
😶 부록 (Appendix)
Variant of the Inception Model Used
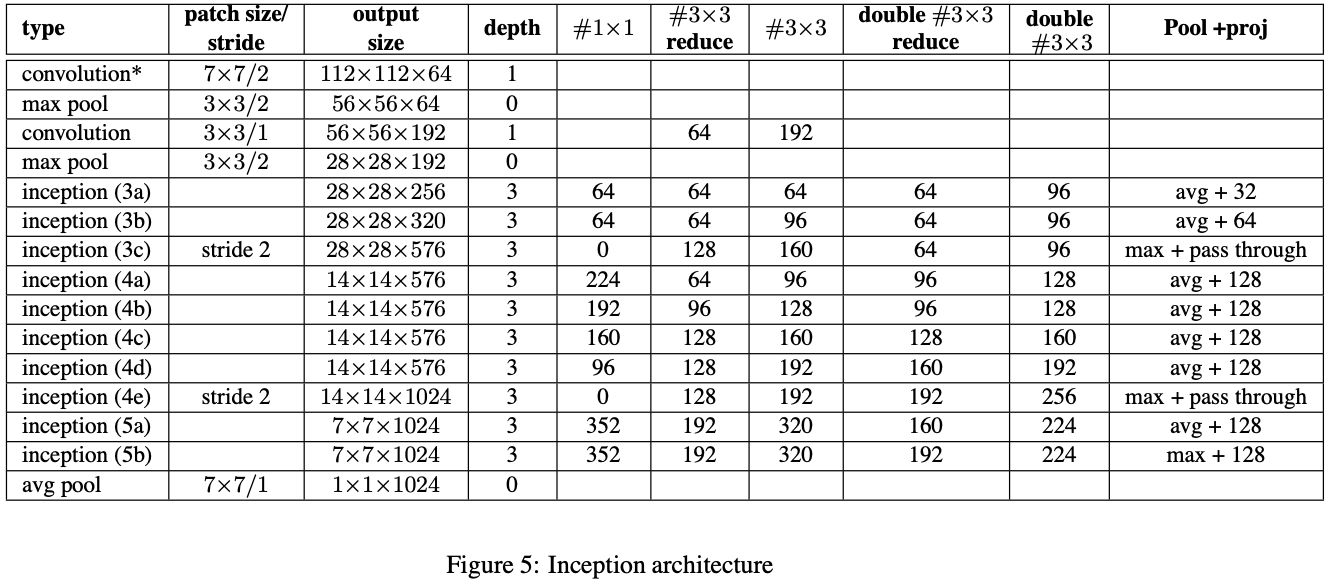
위의 Figure 5는 GoogleNet구조와 관련해 비교한 것으로 표의 해석은 GoogleNet(Szegedy et al., 2014)을 참조. GoogLeNet과 비교했을 때, 주목할만한 구조는 다음과 같다. • 5x5 conv.layer는 2개의 연속된(consecutive) 3x3 conv.layer로 대체된다. - 이는 network의 최대깊이를 9개의 weight layer로 증가시킨다. - 또한, parameter수를 25% 증가시키고 계산비용(computational cost)를 30%정도 증가시킨다.
• 28x28 inception module은 2개에서 3개로 증가시킨다. • module내부에서는 maxpooling과 average pooling이 사용된다. • 두 inception module사이에서 pooling layer는 없지만 module 3c, 4e에서 filter 연결 전에 stride=2의 conv/pooling layer가 사용된다.
우리의 model은 첫번째 conv.layer에서 8배의 깊이를 사용하는 분리가능한 convolution을 사용했다. 이는 training시의 Memory소비를 증가시키고 computational cost를 감소시킨다.
🧐 논문 감상_중요개념 핵심 요약
"Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift" Sergey Ioffe와 Christian Szegedy가 2015년에 발표한 연구 논문으로 이 논문은 심층 신경망의 훈련을 크게 향상시킬 수 있는 Batch Normalization이라는 기술을 제안한다.
[핵심 개념]
1. Internal Covariate Shift 이 논문은 내부 공변량 이동(Internal Covariate Shift) 문제에 대해 설명하는데, 이 문제는 training시 레이어에 대한 입력 값이나 parameter 분포의 변화를 의미한다. 이것은후속 계층학습의 학습속도를 늦추는 것으로 학습과정을 어렵게만들 수 있다.
2. Batch Normalization 이 논문은 내부 공변량 이동 문제에 대한 해결책으로 Batch-Normalization을 제안한다. 배치 정규화는 배치 평균(mean)을 빼고 배치 표준편차(standard deviation)로 나누어 계층에 대한 입력을 정규화하는 것입니다
3. Learnable Scale and Shift 입력을 정규화(normalization)하는 것 외에도 배치 정규화는 두 가지 학습 가능한 매개변수인 scale parameter와 shift parameter를 도입한다. 이러한 parameters를 통해 신경망은 정규화된 입력에 대한 optimal scale 및 shift를 학습할 수 있다.
4. Improved Training 이 논문은 배치 정규화가 내부 공변량 이동의 영향을 줄임으로써 심층 신경망의 교육을 크게 개선할 수 있음을 보여준다. 이것은 더 빠른 수렴, 더 나은 일반화 및 다양한 작업에서 향상된 성능으로 이어진다.
5. Compatibility 이 논문은 배치 정규화가 다양한 신경망 아키텍처 및 활성화 기능과 함께 사용될 수 있음을 보여준다.
전반적으로 이 논문은 심층 신경망 훈련을 개선하기 위한 중요한 기술을 소개하고 다양한 작업에 대한 효과에 대한 증거를 제공한다.