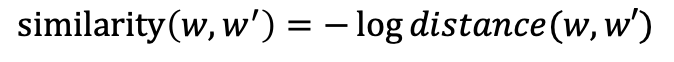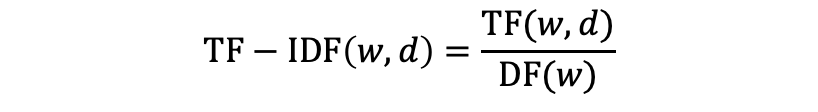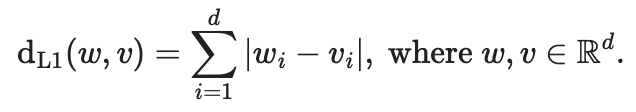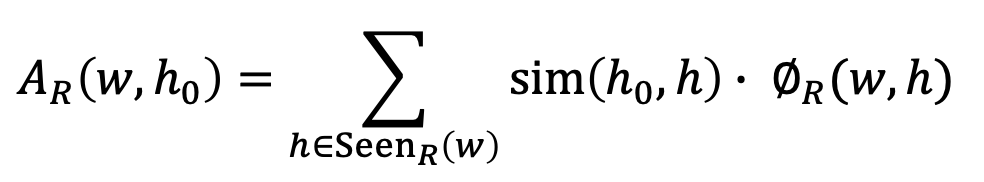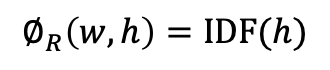1.1 단어와 의미의 관계성 NLP에서 가장 기초가 되는 근간이자 가장 어려운 문제인 단어의 의미(word sense)와 의미의 유사성, 모호성에 대해 알아보자. 단어는 겉으로 보이는 형태인 표제어(lemma)안에 여러 의미를 담고있어서 상황에 따라 다른 의미로 사용된다. 이때, 주변정보(context)에 따라 숨겨진 의미를 파악하고 이해해야하지만 context가 부족하면 ambiguity가 증가할 수 있다. ( ∵ 과거기억 등의 이유)
즉, 한가지 형태의 단어에 여러 의미가 포함되어 생기는 '중의성' 문제는 NLP에서 매우 중요한 위치를 갖는데, 특히 기계번역에서는 단어의 의미에 따라 해당 번역 단어의 형태가 완전히 바뀌기에 매우 중요하다. 즉, lemma(표제어)를 매개체 삼아 내부 latent space의 'word sense'로 변환해 사용해야한다.
1.2 동형어∙다의어 동형어: 형태는 같으나 뜻이 서로 다른 단어 (ex. 차 - tea / car) 다의어: 동형어개념 + 그 의미들이 서로 관련이 있는 뜻 (ex. 다리 - leg / desk leg)
이때, 한 형태내 여러 의미를 갖는 동형어∙다의어의 경우, 단어 중의성해소(WSD)라는 방법을 통해 단어의 의미를 더 명확히 하는 과정이 필요하다. 단어의 의미를 더 명확히 하기 위해 주변문맥을 통해 원래단어의미를 파악해야하는데, 이때 end-to-end 방법이 DNN에서 선호된다. 이로인해 단어 중의성 해소에 대한 필요도가 낮아졌지만 아직 ambiguity는 문제해결이 어려운 경우가 많다.
동의어 동의어: 다른 형태의 단어간에 의미가 같은 단어 (ex. home, place) 물론, 의미가 완전히 딱 떨어지지는 않고 똑같지 않을 수도 있지만 일종의 동의(consensus)가 존재하며, 이 동의어가 여러개 있을 때, 이를 동의어 집합(synset)이라 한다.
상위어∙하위어 단어는 하나의 추상적 개념을 가지며 이때, 그 개념들을 포함하는 상∙하위 개념이 존재하며 이에 해당하는 단어들을 상위어(hypemym), 하위어(hyponym)이라 한다. (ex. 동물-포유류, 포유류-코끼리)
이런 단어들의 어휘분류(taxonomy)에 따라 단어간 관계구조를 계층화 할 수 있다.
1.3 모호성 해소 (WSD) 컴퓨터는 오직 text만 가지므로 text가 내포한 진짜 의미를 파악하는 과정이 필요하다. 즉, 단어의 겉 형태인 text만으로는 모호성(ambiguity)이 높기에 모호성을 제거하는 과정인, WSD(단어 중의성 해소)으로 NLP의 성능을 높일 수 있다.
2. One-Hot Encoding
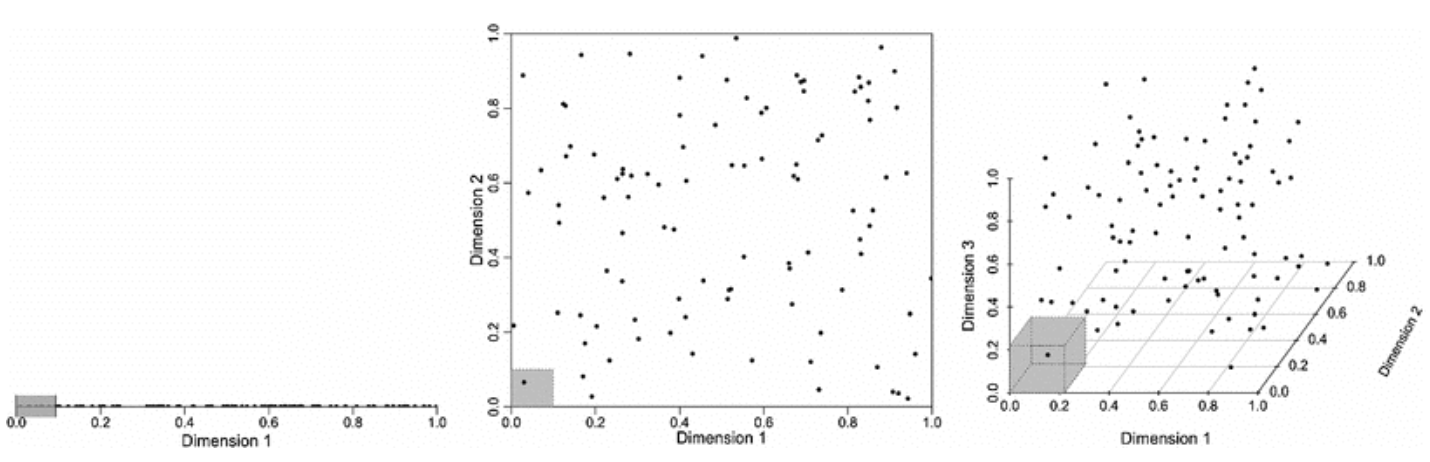
2.1 One-Hot Encoding 단어를 컴퓨터가 인지할 수 있는 수치로 바꾸는 가장 간단한 방법은 벡터로 표현하는 것으로 가장 기본적인 방법 중 하나는 one-hot encoding이라는 방식이다. 말 그대로 단 하나의 1과 나머지 수많은 0들로 표현된 encoding방식으로 one-hot encoding vector의 차원은 보통 전체 vocabulary의 개수가 된다. (보통 그 숫자는 매우 큰 수가 됨; 보통 30,000~100,000)
단어는 연속적인 심볼로써 이산확률변수로 나타낸다.
위와 같이 사전(dictionary)내의 각 단어를 one-hot encoding 방식을 통해 vector로 나타낼 수 있는데, 이 표현방식은 여러 문제점이 존재한다. Prob 1. vector space가 너무 커졌다. (하나만 1, 나머지는 0; 이때 0으로 채워진 vector를 sparse vector라 한다.) Prob 2. sparse vector의 가장 큰 문제점은 vector간 연산 시 결과값이 0이 되는, orthogonal하는 경우가 많아진다. - 즉, 다시 말하면 '강아지', '개'라는 단어는 상호유사하지만 이 둘의 연산 시 둘의 유사도가 0이 되어버릴 것이고, 일반화에 어려움을 겪을 수 있다.
- 이는 Curse of Dimensionality와 연관되는데, 차원이 높아질수록 정보를 표현하는 각 점(vector)가 매우 낮은 밀도로 sparse하게 퍼져있게 된다. 따라서 차원의 저주로부터 벗어나고자 차원의 축소하여 단어를 표현할 필요성이 대두된다.
3. Thesaurus (어휘분류사전)
3.1 WordNet Thesaurus(어휘분류사전)는 계층적 구조를 갖는 단어의미를 잘 분석∙분류해 구축된 데이터베이스로 WordNet은 가장 대표적인 시소러스의 일종이다.
WordNet은 동의어집합(Synset), 상위어, 하위어 정보가 특히 유향비순환그래프(DAG)로 잘 구축되어있다는 장점이 있다. (트리구조가 아님: 하나의 노드가 여러 상위노드를 가질 수 있기 때문.)
WordNet은 워드넷 웹사이트에서 바로 이용할 수도 있다. (http://wordnetweb.princeton.edu/perl/webwn) 아래 사진을 보면 명사일 때 의미 10개, 동사일 때 의미 8개를 정의하였으며 명사 bank#2의 경우, 여러 다른표현(depository financial institution#1, banking concern#1)들도 같이 게시되어있다. (이것들이 바로 동의어 집합)
이처럼 wordnet은 단어별 여러 가능한 의미를 미리 정의하고 번호를 매기고, 동의어를 링크해 동의어 집합을 제공한다. 이는 WSD에 매우 좋은 label data가 되며 wordnet이 제공하는 이 data들을 바탕으로 supervised learning을 진행하면 단어중의성해소(WSD)문제를 풀 수 있다.
3.2 WordNet을 활용한 단어간 유사도 비교 추가적으로 NLTK에 wrapping되어 포함되므로 import하여 사용가능하다.
from nltk.corpus import wordnet as wn
def hypernyms(word):
current_node = wn.synsets(word)[0]
yield current_node
while True:
try:
current_node = current_node.hypernyms()[0]
yield current_node
except IndexError:
break
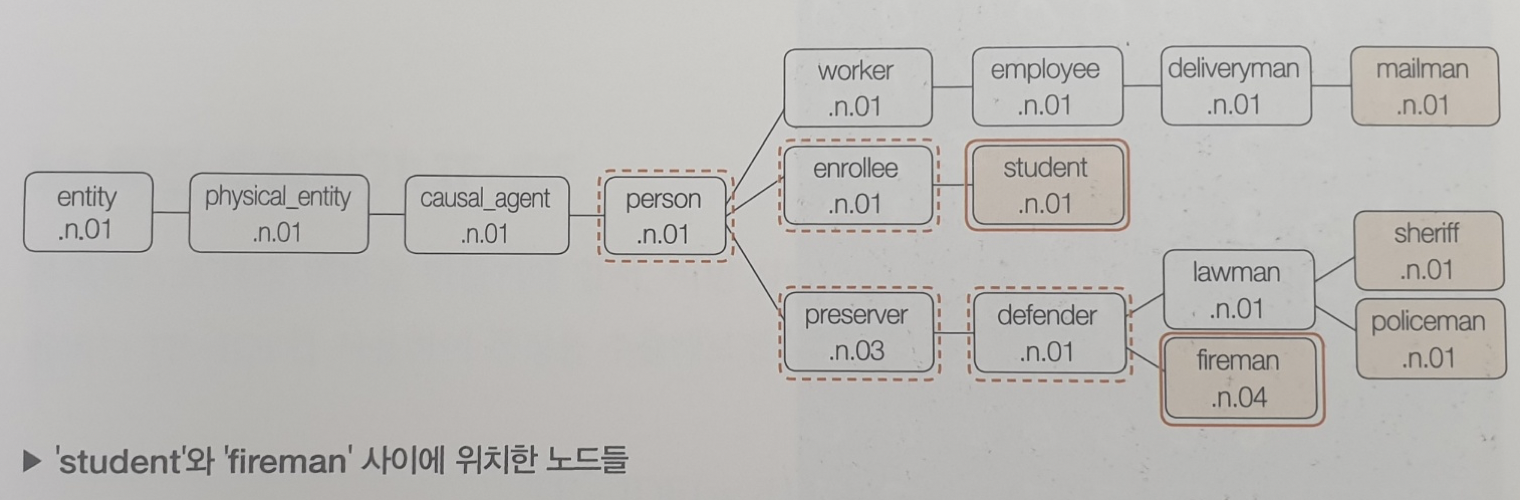
위의 코드는 wordnet에서 특정 단어의 최상위 부모노드까지의 경로를 구할 수 있고, 추가적으로 단어마다 나오는 숫자로 각 노드 간 거리를 알 수 있다.
예를 들어, 위의 경우, 'student'와 'fireman' 사이의 거리는 5 임을 알 수 있다.
이를 통해 각 최하단 노드간의 최단거리를 알 수 있고, 이를 유사도로 치환해 활용할 수 있다. 이를 이용해 공식을 적용해보면 아래와 같다. 한계점: 사전을 구축하는데 비용과 시간이 많이 소요되고 상하위어가 잘 반영된 사전이어야만 해서 사전에 기반한 유사도 구하기 방식은 정확성은 높으나 한계가 뚜렷하다는 단점이 존재.
4. Feature
4.1 Feature 지금까지는 one-hot vector를 통해 단어를 표현했을 때, 많은 문제가 발생한다고 설명하였다. 이는 one-hot vector의 표현방식이 효과적이지 않기 때문이다.
효과적인 정보 추출 및 학습을 위해서는 대상의 특징(feature)을 잘 표현해야한다. 이런 특징은 수치로 표현되며, 최대한 많은 samples를 설명할 수 있어야하기에 samples는 수치가 서로 다른 공통된 특징을 갖고 다양하게 표현되는것이 좋다. 즉, 각 sample의 feature마다 수치를 갖게하여 이를 모아 벡터로 표현한 것을 feature vector라 한다.
4.2 단어의 feature vector 구하기 위한 가정 ① 의미가 비슷한 단어 → 쓰임새가 비슷할 것 ② 쓰임새가 비슷 → 비슷한 문장안에서 비슷한 역할로 사용될 것 ③ ∴ 함께 나타나는 단어들이 유사할 것
5. Feature Extraction. &. Text Mining (TF-IDF)
특징벡터를 만들기 앞서 text mining에서 중요하게 사용되는 TF-IDF를 사용해 특징을 추출하는 방법을 알아보자.
5.1 TF-IDF (Term Frequency-Inverse Document Frequency) TF-IDF: 출현빈도를 사용해 어떤단어 w가 문서 d 내에서 얼마나 중요한지 나타내는 수치이다. 즉, TF-IDF의 값이 높을수록 w는 d를 대표하는 성질을 가진다. TF: 단어의 문서내에 출현한 횟수 IDF: 그 단어가 출현한 문서의 숫자(DF)의 역수
예를 들어, 'the'의 경우, TF값이 매우 클 것이다. 하지만, 'the'가 중요한 경우는 거의 없을 것이기에 이를 위해 IDF가 필요하다. (IDF를 사용함으로써 'the'와 같은 단어들에 penalty를 준다.)
∴ 최종적으로 얻게되는 숫자는 "다른 문서들에서는 잘 나타나지 않지만 특정 문서에서만 잘 나타나는 경우큰 값을 가지며, 특정 문서에서 얼마나 중요한 역할을 차지하는지 나타내는 수치가 될 수 있다."
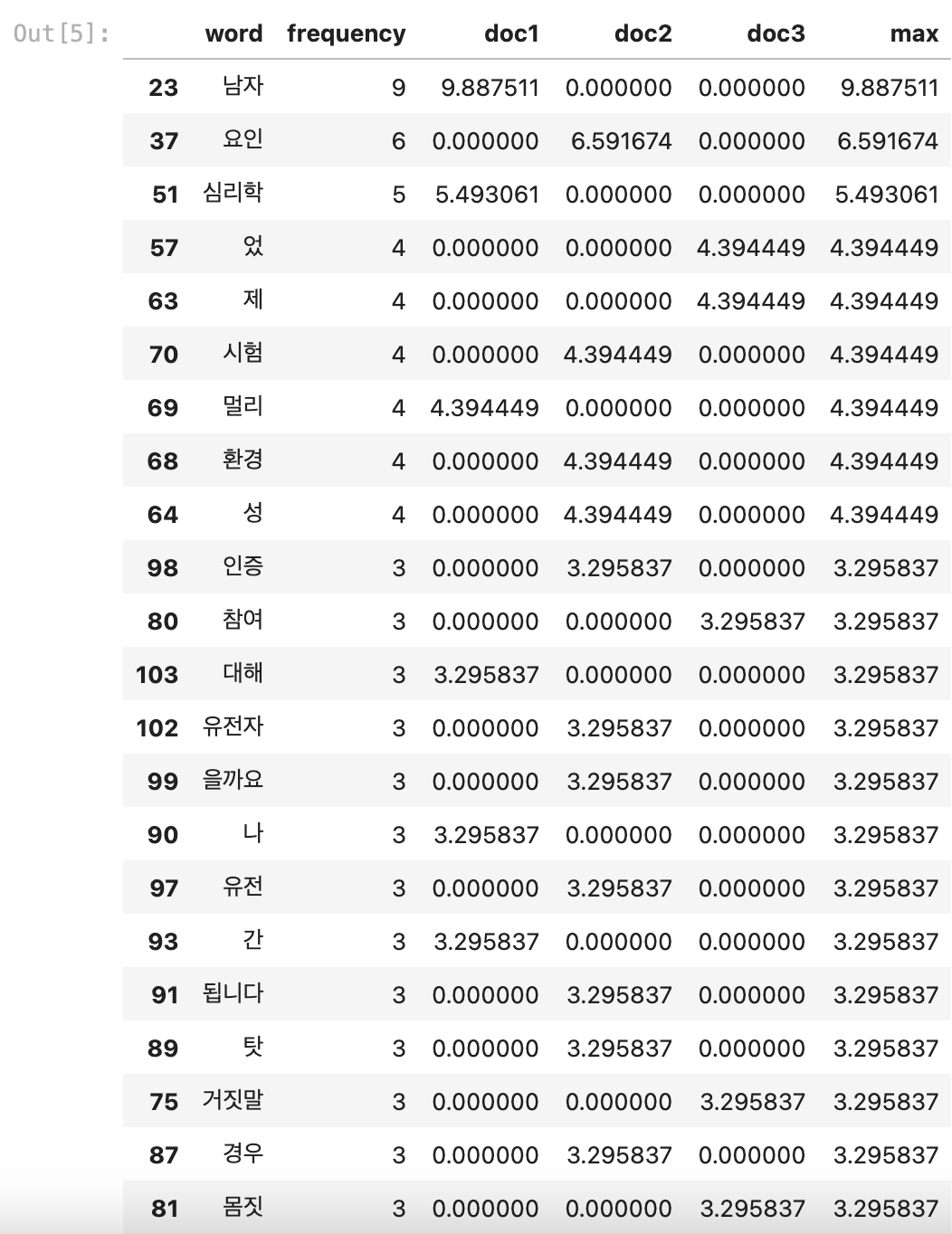
5.2 TF-IDF 구현예제 ∙ 3개의 논문스크립트가 담긴 문서들이 doc1, doc2, doc3변수에 들어있다 가정하자.
📌 TF 함수
def get_term_frequency(document, word_dict=None):
if word_dict is None:
word_dict = {}
words = document.split()
for w in words:
word_dict[w] = 1 + (0 if word_dict.get(w) is None else word_dict[w])
return pd.Series(word_dict).sort_values(ascending=False)
📌 DF 함수
def get_document_frequency(documents):
dicts = []
vocab = set([])
df = {}
for d in documents:
tf = get_term_frequency(d)
dicts += [tf]
vocab = vocab | set(tf.keys())
for v in list(vocab):
df[v] = 0
for dict_d in dicts:
if dict_d.get(v) is not None:
df[v] += 1
return pd.Series(df).sort_values(ascending=False)
📌 TF-IDF 함수
def get_tfidf(docs):
vocab = {}
tfs = []
for d in docs:
vocab = get_term_frequency(d, vocab)
tfs += [get_term_frequency(d)]
df = get_document_frequency(docs)
from operator import itemgetter
import numpy as np
stats = []
for word, freq in vocab.items():
tfidfs = []
for idx in range(len(docs)):
if tfs[idx].get(word) is not None:
tfidfs += [tfs[idx][word] * np.log(len(docs) / df[word])]
else:
tfidfs += [0]
stats.append((word, freq, *tfidfs, max(tfidfs)))
return pd.DataFrame(stats, columns=('word',
'frequency',
'doc1',
'doc2',
'doc3',
'max')).sort_values('max', ascending=False)
get_tfidf([doc1, doc2, doc3])
<출력>
6. Feature Vector 생성
6.1 TF 행렬 만들기 TF 또한 좋은 특징이 되는데, 출현한 횟수가 차원별로 구성되면 하나의 특징벡터를 이룰 수 있다. (물론 문서별 TF-IDF자체를 사용하는것도 좋음.)
def get_tf(docs):
vocab = {}
tfs = []
for d in docs:
vocab = get_term_frequency(d, vocab)
tfs += [get_term_frequency(d)]
from operator import itemgetter
import numpy as np
stats = []
for word, freq in vocab.items():
tf_v = []
for idx in range(len(docs)):
if tfs[idx].get(word) is not None:
tf_v += [tfs[idx][word]]
else:
tf_v += [0]
stats.append((word, freq, *tf_v))
return pd.DataFrame(stats, columns=('word',
'frequency',
'doc1',
'doc2',
'doc3')).sort_values('frequency', ascending=False)
get_tf([doc1, doc2, doc3])
<출력> 이때, 각 열들은 아래와 같다. frequency: TF(w) doc1: TF(w, d1) doc2: TF(w, d2) doc3: TF(w, d3)
TF(w, d1), TF(w, d2), TF(w, d3)는 문서에 대한 단어별 출현횟수를 활용한 특징벡터가 될 것이다. 예를들어 '여러분'은 [5, 6, 1]이라는 특징벡터를 갖는다. 문서가 많다면 지금보다 더 나은 특징벡터를 구할 수 있다.
다만, 문서가 지나치게 많으면 벡터의 차원 역시 지나치게 커질 수 있다. 문제가 되는 이유: 지나치게 커진 차원의 벡터 대부분의 값이 0으로 채워진다는 것.
위의 표에서 3개의 문서 중 일부만 출현해 TF가 0인 경우가 상당히 존재한다. 이렇게 벡터의 극히 일부분만 의미있는 값으로 채워진 벡터를 희소벡터라 한다. 희소벡터의 각 차원은 사실 대부분의 경우 0이기에 유의미한 특정통계를 얻기에 방지턱이 될 수 있다. 즉, 단순히 문서출현횟수로만 특징벡터를 구성하게되기에 많은 정보가 소실되었다. ( ∵ 매우 단순화되었기에 아주 정확한 특징벡터를 구성했다기엔 여전히 무리가 있다.)
6.2 context window로 함께 출현한 단어들의 정보 활용하기 앞선 TF로 특징벡터를 구성한 방식보다 더 정확하다.
context window: 함께 나타나는 단어들을 조사하기 위해 windowing을 실행하여 그 안에 있는 unit들의 정보를 취합하는 방법에서 사용되는 window를 context window라 한다. context window는 window_size라는 하나의 hyper-parameter가 추가되기에 사용자가 그 값을 지정해줄 수 있다. ∙ window_size가 지나치게 클 때: 현재 단어와 관계없는 단어들까지 TF를 count ∙ window_size가 지나치게 작을 때: 관계가 있는 단어들의 TF를 count
[문장들을 입력으로 받아 주어진 window_size내에 함께 출현한 단어들의 빈도를 세는 함수]
from collections import defaultdict
import pandas as pd
def get_context_counts(lines, w_size=2):
co_dict = defaultdict(int)
for line in lines:
words = line.split()
for i, w in enumerate(words):
for c in words[i - w_size:i + w_size]:
if w != c:
co_dict[(w, c)] += 1
return pd.Series(co_dict)
[TF-IDF를 위해 작성한 get_term_frequency()함수를 활용해 동시발생정보를 통해 벡터를 만드는 코드]
def co_occurrence(co_dict, vocab):
data = []
for word1 in vocab:
row = []
for word2 in vocab:
try:
count = co_dict[(word1, word2)]
except KeyError:
count = 0
row.append(count)
data.append(row)
return pd.DataFrame(data, index=vocab, columns=vocab)
<출력> 앞쪽의 출현빈도가 높은 단어들은 대부분의 값이 잘 채워져 있는 것을 알 수 있다. 뒤쪽의 출현빈도가 낮은 단어들은 대부분의 값이 0으로 채워져 있음을 알 수 있다.
7. Vector Similarity (with Norm)
앞서 구한 특징벡터를 어떻게 사용할 수 있을까? 특징벡터는 단어간의 유사도를 구할 때 아주 유용하다.
가장 먼저 언급한 WordNet의 그래프구조에서 단어사이의 거리를 측정, 이를 바탕으로 단어사이의 유사도를 구하는 방법에 대해 알아보다.
이번에는 벡터간의 유사도 or 거리를 구하는 방법들을 다뤄볼 것이다.
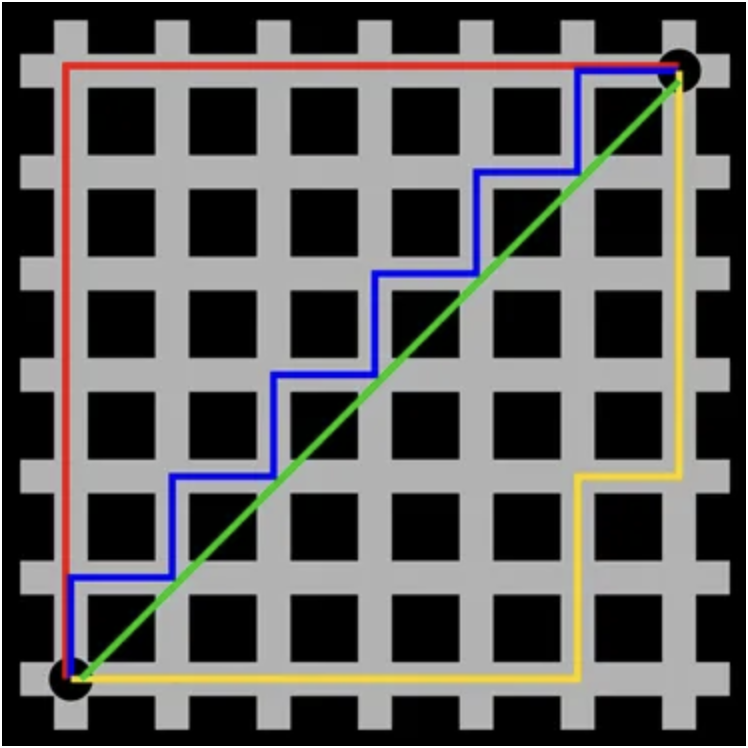
7.1 L1 Distance (Manhattan Distance) L1 Distance는 L1 norm을 사용하는 것으로 Manhattan Distance라고도 한다. 이 방법은 두 벡터의 각 차원별 값의 차이의 절대값을 모두 합한 값이다. 코드로 나타내면 아래와 같다.
7.4 Cosine Similarity 코사인 유사도함수는 두 벡터사이의 방향과 크기를 모두 고려하는 방법이다. 특히, 자연어처리에서 가장 널리 쓰이는 유사도측정방법 이다. ∙ 수식에서 분자는 두 벡터간의 요소곱(element-wise)을 사용한다.(= 내적곱) - 코사인 유사도의 결과가 1에 가까울수록 방향은 일치하고 - 코사인 유사도의 결과가 0에 가까울수록 직교이며 - 코사인 유사도의 결과가 -1에 가까울수록 방향은 반대이다.
[유의할 점] 다만, 분자의 벡터곱연산이나 분자의 L2 norm 연산은 cost가 높아 벡터차원이 커질수록 연산량이 커진다. 이는 희소벡터일 경우, 가장 큰 문제가 발생하는데, 해당차원이 직교하면 곱의 값이 0이되므로 정확한 유사도 및 거리를 반영하지 못한다.
7.5 Jarccard Similarity jarccard similarity는 두 집합간의 유사도를 구하는 방법이다.
∙ 수식에서 분자는 두 집합의 교집합크기이고, 분모는 두 집합의 합집합니다. - 이때, 특징벡터의 각 차원이 집합의 요소(element)이다. - 다만, 각 차원에서의 값이 0 or 0이 아닌 값이 아닌, 수치 자체에 대해 jarccard similarity를 구하고자 할 때는, 2번째 줄의 수식처럼 두 벡터의 각 차원의 숫자에 대해 min, max연산으로 계산할 수 있다.
7.6 문서 간 유사도 구하기 문서 = 문장의 집합 ; 문장 = 단어들의 집합 앞서 설명한 7절의 내용들은 단어에 대한 특징을 수집, 유사도를 구하는 방법이다.
따라서 문서에 대한 특징을 추출하여 문서간의 유사도를 구할 수 있는데, 예를들어, 문서 내의 단어들에 대한 TF나 TF-IDF를 구해 벡터를 구성하고, 이를 활용해 벡터간의 유사도를 구할 수 있다.
물론, 현재 딥러닝에서는 훨씬 더 정확한 방법을 통해 문서간 또는 문장간 유사도를 구할 수 있다.
8. 단어 중의성 해소 (WSD)
8.1 Lesk Algorithm (Thesaurus 기반 WSD) Lesk 알고리즘은 가장 간단한 사전 기반 중의성해소방법이다. 주어진 문장에서 특정단어의 의미를 명확히 할 때 사용할 수 있다.
∙ Lesk 알고리즘의 가정: 문장내 같이 등장하는 단어들은 공통 토픽을 공유
Lesk Algorithm
∙ 중의성을 해소하고자하는 단어에 대해 사전(wordnet)의 의미별 설명을 구함
∙ 주어진 문장 내 등장단어의 사전에서 의미별 설명 사이 유사도를 구한다.
주로 유사도를 구할 때, 단어의 개수를 구한다.
∙ 문장 내 단어들의 의미별 설명과 가장 유사도가 높은 의미를 선택한다.
<예제> In [26] 전까지는 잘 작동하지만, In [26]은 전혀 다른 의미로 예측하는 것을 볼 수 있다. Lesk Algorithm은 명확한 장단점을 갖는다. - 장점) WordNet과 같이 잘 분류된 사전이 있다면, 쉽고 빠르게 WSD(단어 중의성 해소)문제를 해결할 수 있다. - 단점) 사전의 단어 및 의미에 관한 설명에 크게 의존하게되고, 설명이 부실하거나 주어진 문장에 큰 특징이 없다면 WSD능력이 크게 떨어진다.
9. Selection Preference
선택선호도(Selection Preference): 문장은 여러 단어의 시퀀스로 이뤄지는데, 문장 내 주변 단어들에 따라 의미가 정해지며 이를 더 수치화해 나타내는 방법이다. 이를 통해 WSD문제를 해결할 수 있다.
ex) '마시다'라는 동사에 대한 목적어로는 '음료'클래스에 속하는 단어가 올 가능성이 높기에 '차'라는 단어가 '음료'일지 '자가용'일지 어디에 속할 지 쉽게 알 수 있다.
9.1 Selection Preference Strength 선택선호도는 단어간 관계가 좀 더 특별한 경우를 수치화해 나타내는데 단어간 분포의 차이가 클수록 더 강력한 선택선호도를 갖는다 (= 선택 선호도 강도(strength)가 강하다).
이를 KLD(KL-Divergence)를 사용해 정의하였다. 선택선호도 강도 SR(w)은 w가 주어졌을 때, 목표클래스 C의 분포 P(C|w)와 그냥 해당 클래스들의 사전분포 P(C)와의 KLD로 정의되어 있음을 알 수 있다. (즉, 특정 클래스를 얼마나 선택적으로 선호하는지를 알 수 있다.)
9.2 Selectional Association 술어와 특정클래스사이 선택관련도를 살펴보자.
위의 수식에 따르면, 선택선호도강도가 낮은 술어에 대해 분자의 값이 클 경우, 술어와 클래스사이 더 큰 선택관련도를 갖는다는 것을 의미한다. 즉, 선택선호도강도가 낮아 해당 술어는 클래스에 대한 선택적선호강도가 낮지만, 특정클래스만 유독 술어에 영향을 받아 분자가 커져 선택관련도의 수치가 커질 수 있음을 내포한다.
9.3 Selection Preference. &. WSD 이런 선택선호도의 특징을 이용하면 WSD에 활용할 수 있다. ex) '마시다'라는 동사에 '치'라는 목적어가 함께 있을 때, '음료'클래스인지 '자가용'클래스인지만 알아내면 된다.
우리가 아는 corpus들은 단어로 표현되어 있을 뿐, 클래스로 표현되어 있지 않기에 이를 위해 사전에 정의된 지식이나 dataset이 필요하다.
9.4 WordNet기반 Selection Preference 여기서 WordNet이 큰 위력을 발휘한다. WordNet을 이용하면 '차(car)'의 상위어를 알 수 있고 이를 클래스로하여 필요정보를 얻을 수 있다. 술어와 클래스사이 확률분포를 정의하는 출현빈도의 계산수식을 아래와 같이 정의할 수 있다. 클래스 c에 속하는 표제어(headword), 즉 h는 실제 corpus가 나타난 단어로 술어(predicate) w와 함께 출현한 h의 빈도를 세고, h가 속하는 클래스들의 집합의 크기인 |Classes(h)|로 나누어준다. 그리고 이를 클래스 c에 속하는 모든 표제어에 대해 수행한 후 이를 합한 값을 CountR(w,c)를 근사한다. 이를 통해 술어 w와 표제어 h가 주어졌을 때 h의 클래스 c를 추정한 c_hat을 구할 수 있다.
9.5 pseudo word를 통한 Selection Preference평가 유사어휘(pseudo word)가 바로 정교한 testset설계를 위한 하나의 해답이 될 수 있다. 유사어휘는 2개의 단어가 인위적으로 합성되어 만들어진 단어이다.
9.6 Similarity Based Method[2007] WordNet은 모든 언어에 존재하지 않고, 새롭게 생겨나는 신조어들도 반영되지 않을 가능성이 높다. 따라서 wordnet과 thesaurus에 의존하지 않고 선택선호도를 구할 수 있다면??
이를 위해 thesaurus나 thesaurus기반 Lesk알고리즘에 의존하지 않고 data를 기반으로 간단하게 선택선호도를 구하는 방법을 알아보자. 술어 w, 표제어 h, 두 단어 사이의 관계 R이 tuple로 주어질 때, 선택관련도를 아래와 같이 정의할 수 있다. 이때, 가중치 ØR(w,h)는 동일하게 1이나 아래처럼 IDF를 사용해 정의할 수도 있다. 또한 sim함수는 일전의 코사인유사도나 jarccard유사도를 포함, 다양한 유사도함수를 사용할 수 있다. 유사도비교를 위해 SeenR(w)함수로 대상단어를 선정하기에 corpus에 따라 유사도를 구할 수 있는 대상이 달라지며 이를 통해 thesaurus없이도 쉽게 선택선호도를 계산할 수 있게 된다.
유사도기반 선택선호도 예제
from konlpy.tag import Kkma
with open('ted.aligned.ko.refined.tok.random-10k.txt') as f:
lines = [l.strip() for l in f.read().splitlines() if l.strip()]
def count_seen_headwords(lines, predicate='VV', headword='NNG'):
tagger = Kkma()
seen_dict = {}
for line in lines:
pos_result = tagger.pos(line)
word_h = None
word_p = None
for word, pos in pos_result:
if pos == predicate or pos[:3] == predicate + '+':
word_p = word
break
if pos == headword:
word_h = word
if word_h is not None and word_p is not None:
seen_dict[word_p] = [word_h] + ([] if seen_dict.get(word_p) is None else seen_dict[word_p])
return seen_dict
def get_selectional_association(predicate, headword, lines, dataframe, metric):
v1 = torch.FloatTensor(dataframe.loc[headword].values)
seens = seen_headwords[predicate]
total = 0
for seen in seens:
try:
v2 = torch.FloatTensor(dataframe.loc[seen].values)
total += metric(v1, v2)
except:
pass
return total
def wsd(predicate, headwords):
selectional_associations = []
for h in headwords:
selectional_associations += [get_selectional_association(predicate, h, lines, co, get_cosine_similarity)]
print(selectional_associations)
'가'라는 조사에 가장 잘 맞는 단어가 '학교'임을 잘 예측하는 것을 알 수 있따.
마치며...
단어는 보기에는 불연속적인 형태이지만 내부적으로는 연속적인 '의미(sense)'를 갖는다. 따라서 우린 단어의 겉모양이 다르더라도 의미가 유사할 수 있음을 알고 있으며, 단어의 유사도를 걔산할 수 있더라면 corpus로부터 분포나 특징을 훈련 시, 더 정확한 훈련이 가능하다. WordNet이라는 사전의 등장으로 단어사이 유사도(거리)를 계산할 수 있게 되었지만 WordNet과 같은 Thesaurus 구축은 엄청난 일이기에 사전없이 유사도를 구하면 더 좋을 것이다.
사전없이 corpus만으로 특징을 추출해 단어를 벡터로 만든다면, WordNet보다 정교하지는 않지만 더 간단한 작업이 될 것이다. 추가적으로 corpus의 크기가 커질수록 추출할 특징들은 점차 정확해질 것이고, 특징벡터도 더 정확해질 것이다.
특징벡터가 추출된 후 cosine유사도, L2 Distance 등의 Metric을 통해 유사도를 계산할 수 있다. 하지만 앞서 서술했듯, 단어사전 내 단어 수가 많은만큼 특징벡터의 차원도 단어사전크기와 같기에 "단어대신 문서"를 특징으로 사용하더라도 주어진 문서의 숫자만큼 벡터의 차원이 생성될 것이다.
다만 더 큰 문제는 그 차원의 대부분 값이 0으로 채워지는 "희소벡터"로 무엇인가 학습하고자 할 때, cosine유사도의 경우 직교하여 유사도값을 0으로 만들 수 있다. 즉, 정확한 유사도를 구하기 어려워 질 수 있다.
이런 희소성문제는 NLP의 두드러진 특징으로 단어가 불연속적 심볼로 이뤄지기 때문이다. 전통적인 NLP는 이런 희소성문제에 큰 어려움을 겪었다. 하지만 최신 딥러닝에서는 단어의 특징벡터를 이런 희소벡터로 만들기보다는 "word embedding"기법으로 0이 잘 존재하지 않는 dense 벡터로 만들어 사용한다. ex) word2vec, GloVe, ... (https://chan4im.tistory.com/197)