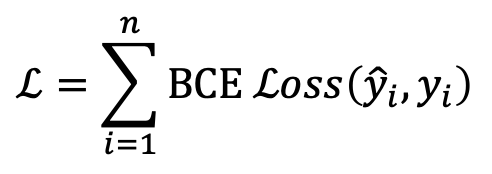Text Classification이란, 텍스트∙문장∙문서를 입력으로 받아 사전에 정의된 클래스중 어디에 속하는지 분류(classification)하는 과정으로 아래와 같이 응용분야가 다양하다.
문제
클래스 예시
감성분석 (Sentiment Analysis)
긍정 / 중립 / 부정
스팸메일 탐지 (Spam Detection)
정상 / 스팸
사용자 의도 분류 (Intent Classification)
명령 / 질문 / 잡담 등
주제 분류 (Topic Classification)
각 주제
카테고리 분류 (Category Classification)
각 카테코리
딥러닝 이전에는 Naïve Bayes Classification, Support Vector Machine 등 다양한 방법으로 Text Classification을 진행하였다. 이번시간에는 딥러닝 이전의 가장 간단한 분류방식인 Naïve Bayes방식을 비롯, 여러 딥러닝 방식을 알아보자.
2. Naïve Bayes 활용하기
Naïve Bayes는 아주 강력한("각 feature는 independent하다!"라는 강력한 가정을 가짐) 분류방식으로
성능은 준수하지만 단어라는 불연속적인 symbol을 다루는 NLP에서는 아쉬운 면이 존재한다.
2.1 MAP (Maximum A Posterior)
❗️Bayes Theorem 이때, 대부분의 문제에서 evidence, P(D)는 구하기 어렵기에 P(c | D) ∝ P(D | c)∙P(c) 식으로 접근하기도 한다. 앞의 성질을 이용하면, 주어진 data D에 대해 확률을 최대로 하는 클래스 c를 구할 수 있는데,
❗️MAP 이처럼 사후확률을 최대화하는 클래스 c를 구하는 것을 MAP(사후확률최대화)라 한다.
❗️MLE 이와 마찬가지로 가능도를 최대화하는 클래스 c를 구하는 것을 MLE(최대가능도추정)이라 한다.
MLE는 주어진 data D와 label C에 대해 확률분포를 근사하기 위한 parameter θ를 훈련하기위한 방법으로 사용된다.
MLE. vs. MAP MAP가 경우에 따라 MLE보다 더 정확할 수 있다. (∵ 사전확률이 포함되어있어서)
2.2 Naïve Bayes Naïve Bayes는 MAP를 기반으로 작동한다. 가정: 각 feature는 independent하다! 라는 강력한 가정을 바탕으로 진행된다. 대부분의 경우, 사후확률을 구하기 어렵기에 가능도와 사전확률의 곱으로 클래스를 예측한다.
만약 다양한 특징으로 이루어진 data의 경우, feature가 희박하기에 가능도를 구하기 또한 어렵다. 이때, Naïve Bayes가 매우 강력한 힘을 발휘하는데, 각 특징이 독립적이라는 가정을 통해 사전확률이 실제 data corpus에서 출현한 빈도를 통해 추정이 가능해지는 것이다.
이처럼 간단한 가정으로 데이터의 희소성문제를 해결하는 쉽고 강력한 방법으로 MAP의 정답클래스라벨예측이 가능해지는 것이다.
상세예시 및 식은 아래 2.3을 참고
2.3 Sentiment Analysis 예제
위와 같이 class와 data가 긍정/부정과 document로 주어질 때, 'I am happy to see this movie' 라는 문장이 주어진다면, 이 문장이 긍정인지 부정인지 판단해보자! Naïve Bayes를 활용해 단어의 조합에 대한 확률을 각각 분해할 수 있다. 즉, 각 단어의 출현확률을 독립적이라 가정 후, 결합가능도확률을 모두 각각의 가능도확률로 분해한다. 그렇게 되면 데이터 D에서의 출현빈도를 구할 수 있다.
이처럼 corpus에서 단순히 각 단어의 class당 출현빈도를 계산하는 것만으로도 간단한 sentiment analysis가 가능하다.
2.4Add-One Smoothing Naïve Bayes가정을 통해 corpus에서 출현확률을 독립으로 만들어 출현횟수를 적극적으로 활용할 수 있게 되었다. 여기서 문제점이 발생하는데, 만약 Count(happy, neg)=0이라면? P(happy | neg)=0이 되어버린다.
아무리 data corpus에 존재하지 않더라도 그런 이유로 해당 sample의 출현확률을 0으로 추정해버리는 것은 매우 위험한 일이 되어버리기에 아래처럼 분자(출현횟수)에 1을 더해주면 쉽게 문제해결이 가능하다.(물론 완벽한 해결법은 아님)
2.5 장점 및 한계 장점: 단순히 출현빈도를 세는 것처럼 쉽고 간단하지만 강력!! 딥러닝을 활용하기에 label랑 문장 수가 매우 적은 경우, 오히려 복잡한 딥러닝방식보다 더 나은 대안이 될 수 있다.
한계: 'I am not happy'와 'I am happy'에서 not의 추가로 문장은 정반대뜻이 된다. 수식으로는 P(not, happy) ≠ P(not)∙P(happy)가 된다. 단어간 순서로 인해 생기는 정보도 무시할 수 없는데, "각 특징은 서로 독립적이다."라는 Naïve Bayes의 기본가정은 언어의 이런 특징을 단순화해 접근해 한계가 존재한다.
3. 흔한 오해 2
표제어추출(lemmatization), 어간추출(stemming)을 수행해 접사등을 제거한 이후 Text Classification을 진행해야하는가?? 예를들어, "나는 학교에 가요"라는 원문이 있다면, [나 학교 가] 처럼 어간추출이 진행된다.
이는 적은 corpus에서 효과를 발휘하여 희소성문제에서 어느정도의 타협점이 존재할 수 있게된다. 특히, DNN이전 전통적 기계학습방법에서 불연속적 존재인 자연어에 좋은 돌파구를 마련해주었다.
하지만, DNN시대에서는 성공적으로 차원축소(https://chan4im.tistory.com/197#n2)를 수행할 수 있게 되면서 희소성문제는 더이상 큰 장애물이 되지는 않기에 lemmazation, stemming등은 반드시 정석이라 하긴 어렵다.
또한, "나는 학교에 가요" / "나만 학교에 가요" 라는 두 문장은 서로 긍정 / 부정이라는 다른 class를 갖기에 lemmazation이나 stemming을 한 후 Text Classification에 접근하는 것은 바람직하지 못한 방법일 수도 있다. 따라서 이후 설명될 신경망모델을 사용해 text classification을 시도하는것이 훨씬 바람직하다.
만약, 성능향상을 위해 tuning 및 여러 시도에서 corpus의 부족이 성능저하의 원인이라 생각될 때, 추가적인 실험으로는 괜찮은 시도가 될 수 있다.
4. RNN 활용하기
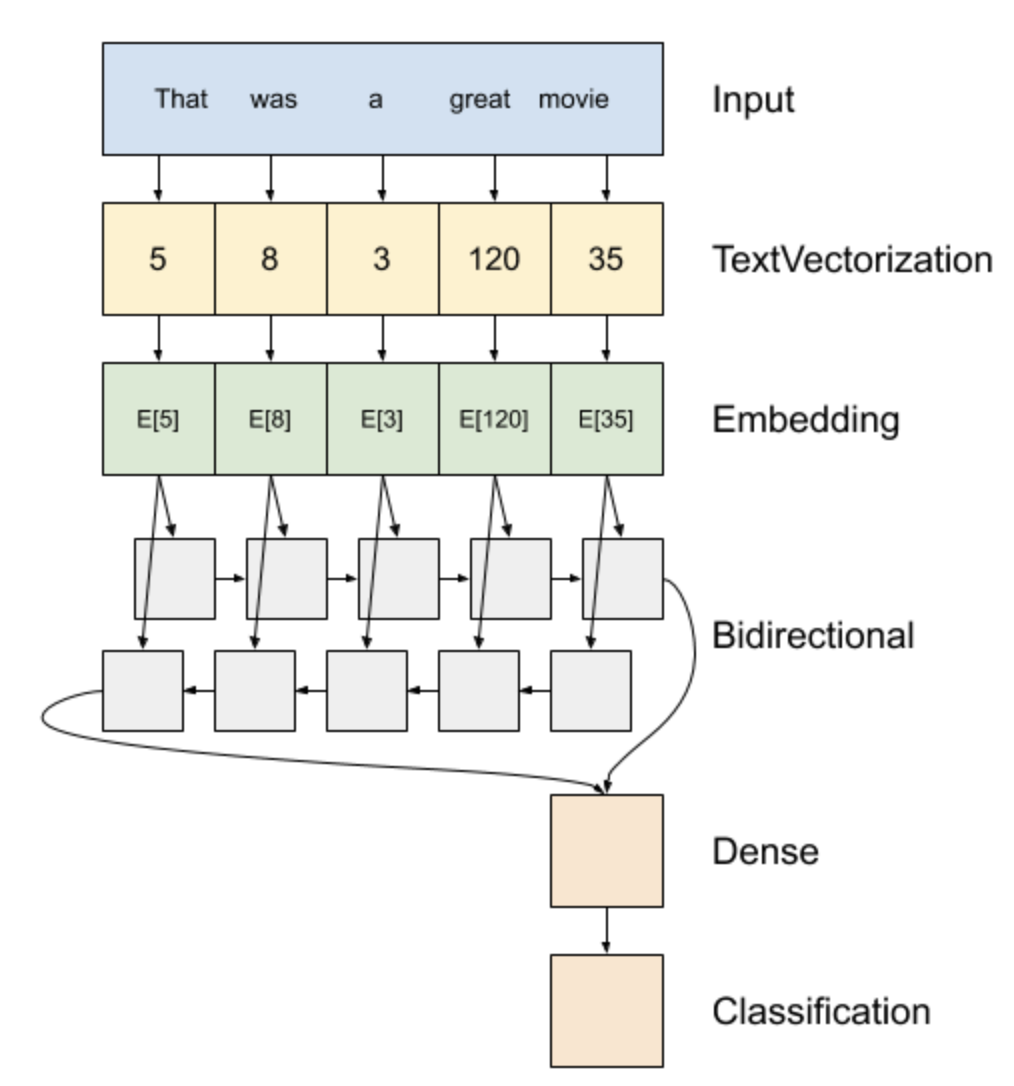
이제 DNN을 통한 text classification문제를 살펴보자. 가장 간단한 방법은 RNN을 활용하는 것으로 sequential data라는 문장의 특징을 가장 잘 활용가능한 신경망 구조이다.
n개의 단어로 이루어진 문장 x에 대해 RNN이 순전파 시, n개의 hidden_state를 얻는다. 이때, 가장 마지막 은닉층으로 text classification이 가능하며 RNN은 입력으로 주어진 문장을 분류문제에 맞게 encoding할 수 있다. 즉, RNN의 출력값은 문장임베딩벡터(sentence embedding vector)라 할 수 있다.
4.1 Architecture 알다시피, text에서 단어는 불연속적 값이기에 이들이 모인 문장 또한, 불연속적값이다. 즉, 이산확률분포에서 문장을 sampling한 것이므로 입력으로는 one-hot벡터들이 여러 time-step으로 주어진다.
mini-batch까지 고려한다면, 입력은 3차원 tensor (n×m×|V|)가 될 것이다. ∙ n : mini_batch size (= 한번에 처리할 문서의 개수) ∙ m : sentence length (= feature vector의 차원수 = 텍스트 문서의 단어의 개수) ∙|V| : Vocabulary size (= Dataset내의 고유한 단어/토큰의 총 수)
하지만 원핫벡터는 주어진 |V| 차원에 단 하나의 1과 |V|-1개의 0으로 이루어진다. 효율적 저장을 위해 굳이 원핫벡터 전체를 가지고 있을 필요는 없기에 원핫벡터를 0 ~ |V|-1 사이 정수로 나타낼 수 있게 된다면, 2차원 matrix (n×m)으로 충분히 나타낼 수 있다.
이렇게 원핫인코딩된 (n×m) tensor를 embedding층에 통과시키면, word embedding tensor를 얻을 수 있다.
이후 word_embedding tensor를 RNN에 통과시키면 된다. 이때, 우린 RNN에 대해 각 time-step별, 계층별로 구분해 word_embedding tensor나 hidden_state를 넣어줄 필요가 없다.
최종적으로 제일 마지막 time-step만 선택해 softmax층을 통과시켜 이산확률분포 P(y | x;θ)로 나타낼 수 있다. 이때 제일 마지막 time-step은 H[:, -1]과 같은 방식으로 index slicing을 통해 도출할 수 있다.
모델구조로 보면 아래와 같다.
마지막으로 원핫벡터 y이기에 인덱스의 로그확률값만 최대화하면 되므로 CE Loss 수식은 NLL(음의 로그가능도)를 최소화하는 것과 동치이다.
Pytorch 구현예제 앞의 수식을 pytorch로 구현한 예제코드로 여러계층으로 이뤄진 LSTM을 사용했다. ∙ LSTM에는 각 층마다 Dropout이 사용되며 ∙ NLL(음의 로그가능도)손실함수로 최적화하기 위해 logsoftmax로 로그확률을 반환한다.
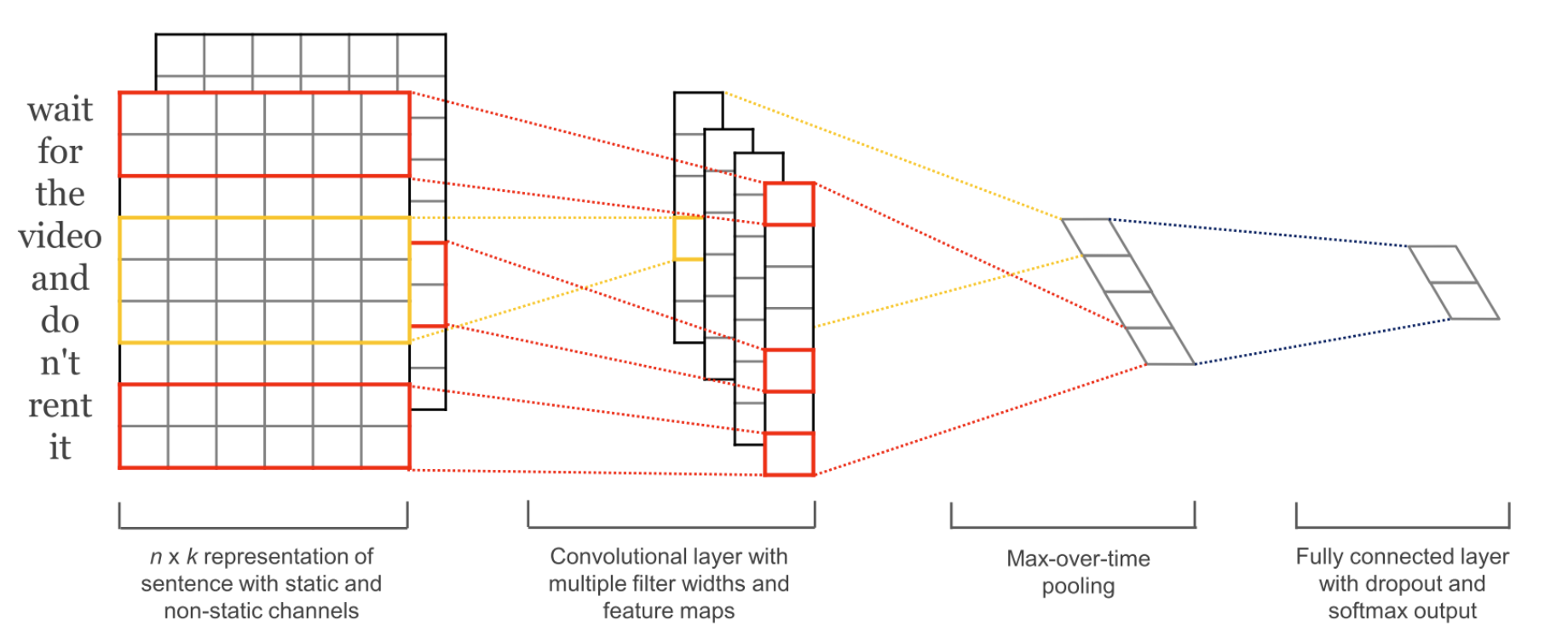
5.3 Text Classification with CNN CNN은 RNN과 달리 순차적 정보보다는 패턴인식 및 파악에 중점을 두는 구조를 갖는다. CNN은 classification에 중요한 단어들의 조합에 대한 패턴을 감지하기도 하는데, 해당 클래스를 나타내는 단어조합에 대한 pattern의 유무를 가장 중시한다.
예를들어, 'good'이라는 단어는 긍정/부정 분류에 핵심이 되는 중요한 signal로 작동한다. 그렇다면, 'good'에 해당하는 embedding vector의 pattern을 감지하는 filter를 모델이 학습한다면? → 'better', 'best', 'great'등의 단어들도 'good'과 비슷한 벡터값을 갖게 될 것이다. → 더 나아가 단어들의 조합 패턴(word sequence pattern)을 감지하는 filter도 학습이 가능할 것이다.
모델 구조에 대해 간단히 설명하자면, 아래와 같다. 먼저 one-hot벡터를 표현하는 인덱스값을 단어임베딩벡터(1차원)로 변환한다. 그 후 문장 내 모든 time-step의 단어임베딩벡터를 합치면 2차원 행렬이 된다. 그 후 Convolution Operation을 수행하면 CNN이 효과를 발휘한다.
Pytorch 구현예제 RNN의 text classification처럼 NLL(음의 로그가능도)손실함수로 최적화하기 위해 logsoftmax로 로그확률을 반환한다.
import torch
import torch.nn as nn
class CNNClassifier(nn.Module):
def __init__(
self,
input_size,
word_vec_size,
n_classes,
use_batch_norm=False,
dropout_p=.5,
window_sizes=[3, 4, 5],
n_filters=[100, 100, 100],
):
self.input_size = input_size # vocabulary size
self.word_vec_size = word_vec_size
self.n_classes = n_classes
self.use_batch_norm = use_batch_norm
self.dropout_p = dropout_p
# window_size means that how many words a pattern covers.
self.window_sizes = window_sizes
# n_filters means that how many patterns to cover.
self.n_filters = n_filters
super().__init__()
self.emb = nn.Embedding(input_size, word_vec_size)
# Use nn.ModuleList to register each sub-modules.
self.feature_extractors = nn.ModuleList()
for window_size, n_filter in zip(window_sizes, n_filters):
self.feature_extractors.append(
nn.Sequential(
nn.Conv2d(
in_channels=1, # We only use one embedding layer.
out_channels=n_filter,
kernel_size=(window_size, word_vec_size),
),
nn.ReLU(),
nn.BatchNorm2d(n_filter) if use_batch_norm else nn.Dropout(dropout_p),
)
)
# An input of generator layer is max values from each filter.
self.generator = nn.Linear(sum(n_filters), n_classes)
# We use LogSoftmax + NLLLoss instead of Softmax + CrossEntropy
self.activation = nn.LogSoftmax(dim=-1)
def forward(self, x):
# |x| = (batch_size, length)
x = self.emb(x)
# |x| = (batch_size, length, word_vec_size)
min_length = max(self.window_sizes)
if min_length > x.size(1):
# Because some input does not long enough for maximum length of window size,
# we add zero tensor for padding.
pad = x.new(x.size(0), min_length - x.size(1), self.word_vec_size).zero_()
# |pad| = (batch_size, min_length - length, word_vec_size)
x = torch.cat([x, pad], dim=1)
# |x| = (batch_size, min_length, word_vec_size)
# In ordinary case of vision task, you may have 3 channels on tensor,
# but in this case, you would have just 1 channel,
# which is added by 'unsqueeze' method in below:
x = x.unsqueeze(1)
# |x| = (batch_size, 1, length, word_vec_size)
cnn_outs = []
for block in self.feature_extractors:
cnn_out = block(x)
# |cnn_out| = (batch_size, n_filter, length - window_size + 1, 1)
# In case of max pooling, we does not know the pooling size,
# because it depends on the length of the sentence.
# Therefore, we use instant function using 'nn.functional' package.
# This is the beauty of PyTorch. :)
cnn_out = nn.functional.max_pool1d(
input=cnn_out.squeeze(-1),
kernel_size=cnn_out.size(-2)
).squeeze(-1)
# |cnn_out| = (batch_size, n_filter)
cnn_outs += [cnn_out]
# Merge output tensors from each convolution layer.
cnn_outs = torch.cat(cnn_outs, dim=-1)
# |cnn_outs| = (batch_size, sum(n_filters))
y = self.activation(self.generator(cnn_outs))
# |y| = (batch_size, n_classes)
return y
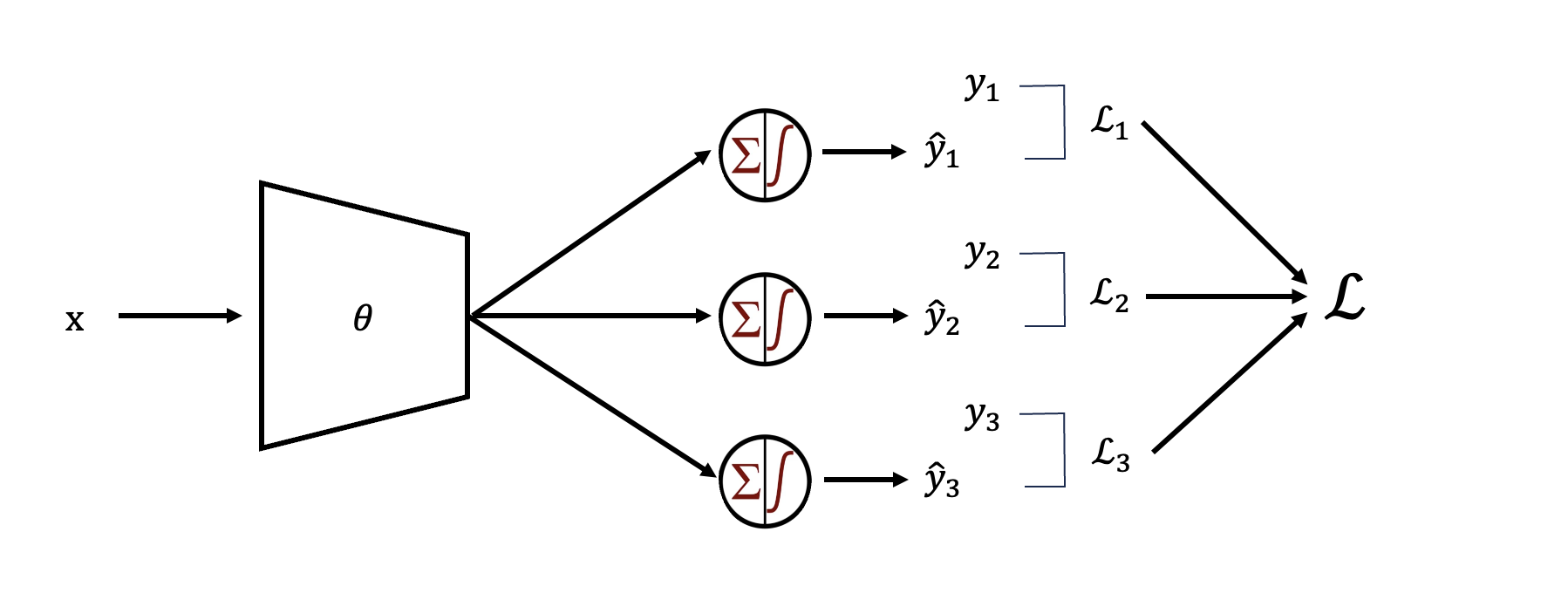
6. 쉬어가기) Multi-Label Classification
Mutli-Label Classification: 기존 softmax 분류와 달리 여러 클래스가 동시에 정답이 될 수 있는것
6.1 Binary-Classification sigmoid. &. BCELoss를 사용한다. (이진분류상황은 Bernoulli Distribution이기 때문)
수식은 아래와 같은데, BCE Loss는 이진분류에 특화된 기존 CE Loss의 한 종류이다. 이 수식에서 y는 0또는 1을 갖는 불연속적인 값이고 y_hat은 sigmoid를 통과한 0~1사이의 연속적인 출력값이다.
6.2 Multi-Binary Classification 그렇다면, Multi-Label문제에서 Binary Classification를 어떻게 적용할까?
n개의 항목을 갖는 분류에 대해 신경망의 마지막 계층에 n개의 노드를 주고, 모두 sigmoid함수를 적용한다. 즉, 하나의 모델로 여러 이진분류작업이 가능하다.
그렇다면 최종 손실함수는? 다음과 같다.
6.3ETC 이진분류가 아닐 때는, sigmoid가 아닌 softmax를 사용하고, Loss도 Cross-Entropy로 바꾸면 된다.
마치며...
이번시간에는 text classification에 대해 다루었다. text classification은 모델의 구조의 복잡도나 코드작성난도에 비해 활용도가 매우 높은 분야이다. 다만, 신경망사용이전, 불연속적값에 대한 희소성문제해결을 하지 못한 채, Naïve Bayes방식과 같이 매우 간단하고 직관적인 방법을 사용했다. 다만, Naïve Bayes방식은 "각 feature는 independent하다!"라는 강력한 가정으로인해 classification의 정확도가 떨어질 수 밖에 없었다. 하지만 딥러닝의 도입으로 매우 효율적이고 정확하게 text classification이 가능해졌는데, RNN은 단어들을 순차적으로 받아 가장 마지막 time-step에서 classification을 예측하고 CNN은 classification에 중요한 단어들의 조합에 대한 패턴을 감지하기도 한다.
∙RNN의 경우, 문장전체의 맥락과 의미에 더 집중해 classification을 수행하며 ∙CNN의 경우, 해당 클래스를 나타내는 단어조합에 대한 pattern의 유무를 가장 중시한다.
따라서 RNN과 CNN을 조합해 Ensemble Model로 구현한다면 더 좋은 결과를 얻을수도 있다. 이를 기반으로 다른 모델들을 참고한다면, 긴문장이나 어려운 텍스트에서도 더 높은 성능을 낼 수 있을 것이다.