1.1 번역의 목표 NMT는 end-to-end학습으로써, 규칙기반기계번역(RBMT)과 통계기반기계번역(SMT)의 명목을 이어받아서 가장 큰 성취를 이룩해냈다. cf) end-to-end학습: 입력 데이터에서부터 원하는 출력을 직접 예측하고 학습하는 방식, 중간 단계나 특징 추출 단계 없이 입력과 출력 간의 관계를 모델링하려는 것을 의미
번역의 궁극적인 목표: 어떤 언어 f의 문장이 주어질 때, 가능한 e 언어의 번역문장 중, 최대확률을 갖는 값을 찾는것
1.2 기계번역의 역사 ∙ 규칙기반 기계번역[RBMT] 주어진 문장의 구조를 분석, 그 분석에 따라 규칙을 세우고, 분류를 나눠 정해진 규칙에 따라 번역 이 과정을 사람이 모두 개입해야하기에 비용적 측면에서 매우 불리하다.
∙ 통계기반 기계번역[SMT] 대량의 Bi-Direction corpus에서 통계를 얻어 번역시스템을 구성하는 것으로 알고리즘이나 시스템으로 인해 언어쌍을 확장할 때, RBMT에 비해 훨씬 유리하다.
∙ 신경망 기계번역[NMT] - DNN 이전: Encoder-Decoder형태의 구조 - DNN 이후: end-to-end 모델, NNLM기반, 훌륭한 문장임베딩 등의 장점으로 매우 powerful해졌다.
2. seq2seq
2.1 Architecture seq2seq는 사후확률 P(Y | X;θ)를 최대로하는 모델의 파라미터를 찾아야 하며, 이 사후확률을 최대로 하는 Y를 찾아야 하기에 크게 3가지의 서브모듈[ Encoder / Decoder ]로 구성된다.
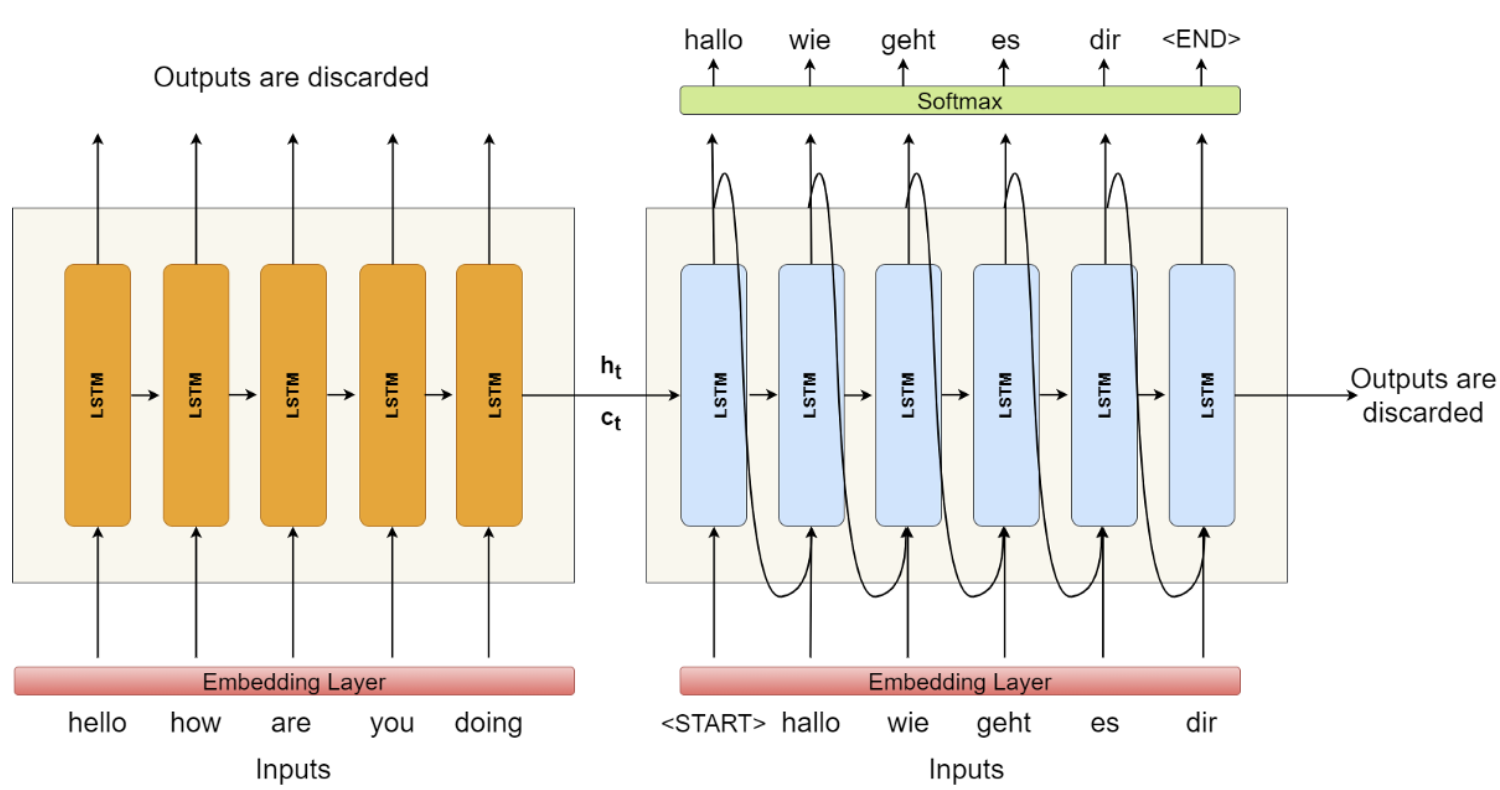
seq2seq : Sequence to Sequence[Sutskever2014; https://arxiv.org/abs/1409.3215]의 혁신성은 "가변길이의 문장을 가변길이의 문장으로 변환"할 수 있다는 것이다. ex) 한국어→영어로 번역 시, 둘의 문장길이가 달라 seq2seq model이 필요
- 학습 시 Decoder의 input부분과 output부분이 모두 동작한다. 즉, 정답에 해당하는 출력을 알려주는 교사강요(teacher forcing)방법을 사용. teacher forcing에 대해서는 아래 5번항목에서 설명하겠다.
- 예측 시 정답을 모르기 때문에 회색표시한 input 부분을 제외하고 자기회귀(auto-regressive) 방식으로 동작한다. 자기회귀에서 <SOS>가 입력되면 첫 단어 'That'을 출력하고 'That'을 보고 그 다음 둘째 단어 'can't'를 출력한다. 즉, 이전에 출력된 단어를 보고 현재단어를 출력하는 일을 반복하며, 문장끝을 나타내는 <EOS>가 발생하면 멈춘다.
- 한계 : 가장 큰 문제는 encoder의 마지막 hidden state만 decoder에 전달한다는 점이다. 아래 그림에서 보면 h5만 decoder로 전달된다. 따라서 encoder는 마지막 hidden state에 모든 정보를 압축해야하는 부담이 존재한다.
Encoder 주어진 문장인 여러 개의 벡터를 입력으로 받아 문장을 함축하는 문장임베딩벡터로 만든다. 즉, P(z | X)를 모델링 후, 주어진 문장을 manifold를 따라 차원축소, 해당 도메인의 latent space의 어떤 하나의 점에 투영하는 작업이다.
다만 기존의 text classification에서는 모든 정보(feature)가 필요하지 않다. 따라서 벡터생성 시 많은 정보를 가질 필요가 없다. 하지만 NMT를 위한 sentence embedding vector 생성 시, 최대한 많은 정보를 가져야한다.
추가적으로 seq2seq모델에서 hidden layer간에 concatenate 작업으로 전체 time-step을 한번에 병렬로 처리한다.
Decoder 일종의 조건부 신경망 언어모델[CNNLM]에 조건부 확률변수 부분에 X가 추가된 형태라 할 수 있다. 즉, encoder의 결과인 sentence embedding vector와 이전 time-step까지 번역해 생성한 단어들에 기반해 현재 time-step의 단어를 생성한다.
특이한 점은 Decoder의 입력의 초기값으로써 BOS token을 입력으로 준다는 점이다. ❗️BOS (Beginning of Sentence): BOS는 문장의 시작을 나타내는 특별한 토큰 또는 심볼로 주로 Seq2Seq모델과 같은 모델에서 입력 시퀀스의 시작을 표시하는 데 사용된다.
Generator Decoder에서 각 time-step별로 결과벡터 h를 받아 softmax를 계산해 각 target언어의 단어어휘별 확률값을 반환한다. 생성자의 결과값은 각 단어가 나타난 확률인 이산확률분포가 된다.
이때, 주의할 점은 문장의 길이가 |Y|=m이라면, 마지막 반환단어 ym은 EOS token이 된다는 점이다. 이 EOS로 Decoder 계산의 종료를 나타낸다. ❗️EOS (End of Sentence): EOS는 문장의 끝을 나타내는 특별한 토큰 또는 심볼로 주로 Seq2Seq 모델과 같은 모델에서 출력 시퀀스의 끝을 나타내는 데 사용됩니다.
2.3 한계 [Bottleneck Problem] 가장 큰 문제는 encoder의 마지막 hidden state만 decoder에 전달한다는 점이다. 이를 Bottleneck Problem이라 하는데, Encoder는 마지막 hidden state에 하나의 고정된 크기의 single vector로 모든 정보를 압축해야하는 부담이 존재하게 된다. 즉, 정보손실이 발생 및 기울기 소실이 되어버린다.
이런 한계를 해결하는 것이 바로 Attention 메커니즘을 이용하는 방법이다. attention 메커니즘은 관련있는 단어와의 attention을 높여 기존처럼 뒤에 집중되는 현상을 방지한다. 즉, "특정부분에 집중"하기 위해 Decoder의 각 단계에서 encoder와 직접적인 연결을 하게 한다.
Pytorch 예제
Encoder 클래스 Encoder는 RNN을 사용한 text classification과 거의 유사하다. 따라서 Bi-Directional LSTM을 사용한다.
class Encoder(nn.Module):
def __init__(self, word_vec_size, hidden_size, n_layers=4, dropout_p=.2):
super(Encoder, self).__init__()
# Be aware of value of 'batch_first' parameter.
# Also, its hidden_size is half of original hidden_size,
# because it is bidirectional.
self.rnn = nn.LSTM(
word_vec_size,
int(hidden_size / 2),
num_layers=n_layers,
dropout=dropout_p,
bidirectional=True,
batch_first=True,
)
def forward(self, emb):
# |emb| = (batch_size, length, word_vec_size)
if isinstance(emb, tuple):
x, lengths = emb
x = pack(x, lengths.tolist(), batch_first=True)
# Below is how pack_padded_sequence works.
# As you can see,
# PackedSequence object has information about mini-batch-wise information,
# not time-step-wise information.
#
# a = [torch.tensor([1,2,3]), torch.tensor([3,4])]
# b = torch.nn.utils.rnn.pad_sequence(a, batch_first=True)
# >>>>
# tensor([[ 1, 2, 3],
# [ 3, 4, 0]])
# torch.nn.utils.rnn.pack_padded_sequence(b, batch_first=True, lengths=[3,2]
# >>>>PackedSequence(data=tensor([ 1, 3, 2, 4, 3]), batch_sizes=tensor([ 2, 2, 1]))
else:
x = emb
y, h = self.rnn(x)
# |y| = (batch_size, length, hidden_size)
# |h[0]| = (num_layers * 2, batch_size, hidden_size / 2)
if isinstance(emb, tuple):
y, _ = unpack(y, batch_first=True)
return y, h
Decoder 클래스 이후 나올 Attention개념을 추가하면, 아래와 같다.
class Decoder(nn.Module):
def __init__(self, word_vec_size, hidden_size, n_layers=4, dropout_p=.2):
super(Decoder, self).__init__()
# Be aware of value of 'batch_first' parameter and 'bidirectional' parameter.
self.rnn = nn.LSTM(
word_vec_size + hidden_size,
hidden_size,
num_layers=n_layers,
dropout=dropout_p,
bidirectional=False,
batch_first=True,
)
def forward(self, emb_t, h_t_1_tilde, h_t_1):
# |emb_t| = (batch_size, 1, word_vec_size)
# |h_t_1_tilde| = (batch_size, 1, hidden_size)
# |h_t_1[0]| = (n_layers, batch_size, hidden_size)
batch_size = emb_t.size(0)
hidden_size = h_t_1[0].size(-1)
if h_t_1_tilde is None:
# If this is the first time-step,
h_t_1_tilde = emb_t.new(batch_size, 1, hidden_size).zero_()
# Input feeding trick.
x = torch.cat([emb_t, h_t_1_tilde], dim=-1)
# Unlike encoder, decoder must take an input for sequentially.
y, h = self.rnn(x, h_t_1)
return y, h
Generator 클래스
class Generator(nn.Module):
def __init__(self, hidden_size, output_size):
super(Generator, self).__init__()
self.output = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
# |x| = (batch_size, length, hidden_size)
y = self.softmax(self.output(x))
# |y| = (batch_size, length, output_size)
# Return log-probability instead of just probability.
return y
Loss Function 'softmax+CE'보다는 'logsoftmax + NLL(음의 로그가능도)'를 사용한다.
# Default weight for loss equals to 1
# But, we don't need to get loss for PAD Token
# Thus, set a weight for PAD to 0
loss_weight = torch.ones(output_size)
loss_weight[data_loader.PAD] = 0.
# Instead of using Cross-Entropy,
# We can use NLL(Negative-Log-Likelihood) loss with log-probability
crit = nn.NLLLoss(weight=loss_weight, reduction='sum', )
따라서 softmax사용대신 logsoftmax함수로 로그확률을 구한다.
def _get_loss(self, y_hat, y, crit=None):
# |y_hat| = (batch_size, length, output_size)
# |y| = (batch_size, length)
crit = self.crit if crit is None else crit
loss = crit(y_hat.contiguous().view(-1, y_hat.size(-1)),
y_contiguous().view(-1)
)
return loss
3. Attention
3.1 Attention의 목표 Query와 비슷한 값을 갖는Key를 찾아 그 값을 얻는 과정. (이때, 그 값을 Value라 한다.)
3.2 Key-Value 함수 ∙ Python의 Dictionary: Key-Value의 쌍으로 이루어진 자료형
Dic = {'A.I':9 , 'computer':5, 'NLP':4}
이와 같이 Key와 Value에 해당하는 값들을 넣고, Key를 통해 Value값에 접근가능하다. 즉, Query가 주어질 때, Key값에따라 Value값에 접근할 수 있다.
def KV(Q):
weights = []
for K in dic.keys():
weights += [is_same(K, Q)]
weight_sum = sum(weights)
for i, w in enumerate(weights):
weights[i] = weights[i] / weight_sum
ans = 0
for weight, V in zip(weights, dic.values()):
ans += weight*V
return ans
def is same(K, Q):
if K == Q:
return 1.
else:
reutnr .0
3.3 연속적인 Key-Value 벡터 함수 만약 Dic의 Value에 100차원 벡터가 들어가있다면?? 혹은 Query와 Key값 모두 벡터를 다뤄야 한다면?? ❓ 즉, Q, K가 word embedding vector라면?? ❓ 또는, Dic의 K, V값이 서로 같다면??
def KV(Q):
weights = []
for K in dic.keys():
weights += [how_similar(K, Q)] # cosine similarity값을 채운다.
weights = softmax(weights) # 모든 가중치를 구한 후 softmax를 계산(모든 w합크기를 1로 고정)
ans = 0
for w, V in zip(weights, dic.values()):
ans += w*V
return ans
위의 코드에서 ans에는 어떠한 벡터값이 들어간다. ans내부의 벡터들의 코사인 유사도에 따라 벡터값이 정해진다.
즉, 위의 함수는 Q와 비슷한 K값을 찾아 유사도에 따라 Weight를 정하고, 각 K와 V값을 W값만큼 가져와 모두 더하는 것으로 이것이 바로 Attention Mechanism의 핵심 아이디어이다.
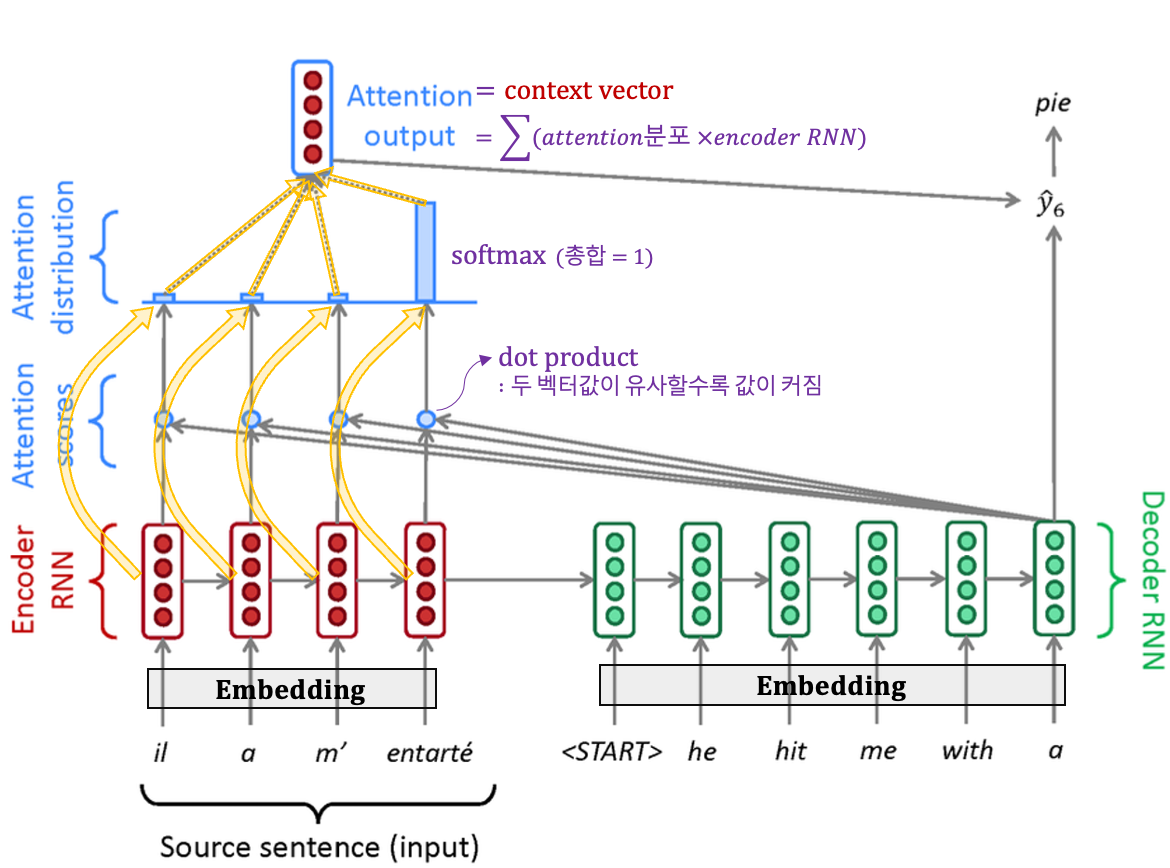
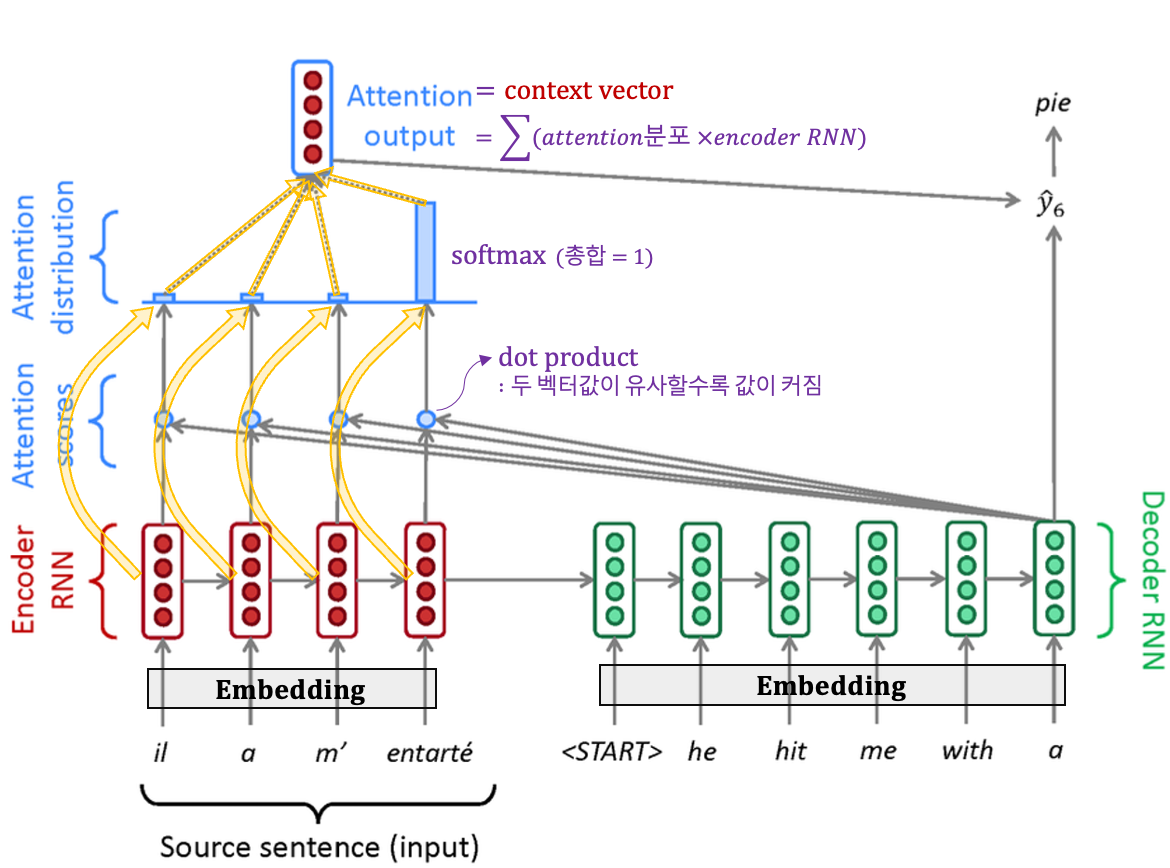
3.4 NMT에서의 Attention 그렇다면, MT에서 Attention Mechanism은 어떻게 작동될까? ∙ K,V: Encoder의 각 time-step별 출력 ∙ Q: 현재 time-step의 Decoder출력
Seq2Seq with Attention원하는 정보를 Attention을 통해 Encoder에서 얻고, 해당 정보를 Decoder의 출력과 이어붙여 tanh를 취한 후 softmax계산을 통해 다음 time-step의 입력이 되는 y_hat을 구한다.
Linear Transformation 신경망 내부의 각 차원들은 latent feature값이기에 정확히 정리할 수 없다. 하지만, 확실한 점은 source언어와 대상언어가 애초에 다르다는 것이다. 따라서, 단순히 벡터내적을 하기보단 소스와 대상간에 연결고리가 필요하다.
따라서, 두 언어가 각각 임베딩된 latent space이 선형관계에 있다 가정하고, 내적연산수행을 위해 선형변환을 해준다. (선형변환을 위한 W값은 가중치로 FF, BP로 학습된다.)
❓왜 Attention이 필요할까?에 대한 질문에서, 이 선형변환을 배우는 것 자체가 Attention이라 표현하는 것은 과하지 않다. (∵ 선형변환과정으로 Decoder의 현재상태에 필요한 Q를 생성, Encoder의 K값들과 비교, 가중합을 하는 것이기 때문) 즉, Attention을 통해 Decoder는 Encoder에 Q를 전달하며, 이때 좋은 값을 전달하는 것은 좋은 결과로 이어지기 때문에 현재 Decoder상태에 필요한 정보가 무엇인지 스스로 판단해 선형변환을 통해 Q를 만드는 것이 매우 중요한 것이다. 또한 선형변환을 위한 가중치 자체도 한계가 있기에 Decoder의 상태 자체가 선형변환이 되어 Q가 좋은 형태가 되도록 RNN이 동작할 것이다.
∙ Attention 클래스: 선형변환을 위한 가중치파라미터를 bias가 없는 선형층으로 대체하였다. 조금 더 자세한 설명은 다음 Section에서 계속 진행한다.
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.linear = nn.Linear(hidden_size, hidden_size, bias=False)
self.softmax = nn.Softmax(dim = -1)
def forward(self, h_src, h_t_target, mask=None):
# |h_src| = (batch_size, length, hidden_size)
# |h_t_target| = (batch_size, 1, hidden_size)
# |mask| = (batch_size, length)
Q = self.linear(h_t_target.squeeze(1)).unsqueeze(-1)
# |Q| = (batch_size, hidden_size, 1)
weight = torch.bmm(h_src, Q).squeeze(-1)
# |weight| = (batch_size, length)
if mask is not None:
# Set each weight as -inf, if the mask value equals to 1.
# Since the softmax operation makes -inf to 0,
# masked weights would be set to 0 after softmax operation.
# Thus, if the sample is shorter than other samples in mini-batch,
# the weight for empty time-step would be set to 0.
weight.masked_fill_(mask.unsqueeze(1), -float('inf'))
weight = self.softmax(weight)
context_vector = torch.bmm(weight, h_src)
# |context_vector| = (batch_size, 1, hidden_size)
return context_vector
∙ |x| = (batch_size, m, k) ∙ |y| = (batch_size, h, m) | torch.bmm(x, y) | = (batch_size, n, m)
4. Input Feeding
각 time-step의 decoder출력값과 attention결과값을 이어붙인 후 Generator Module에서 softmax를 취해 확률분포를 구한다. 이후 해당 확률분포에서 argmax를 수행해 y_hat을 sampling한다. 다만, 분포에서 sampling하는 과정에서보다 더 많은 정보가 손실된다.
따라서 softmax이전값도 같이 넣어주는 편이 정보손실없이 더 좋은 효과를 얻는다., y와 달리 concat층의 출력은 y가 embedding층에서 dense벡터로 변환되고 난 후 임베딩 벡터와 이어붙여 Decoder RNN에 입력으로 주어지는 과정을 input feeding이라 한다.
4.1 단점 이 방식은 train속도저하의 단점이 존재하는데, input feeding이전방식에서는 훈련 시 decoder 또한 encoder처럼 모든 time-step을 한번에 계산한다. 하지만 input feeding으로인해 decoder RNN입력으로 이전 time-step의 결과가 필요하게 되어 순차적으로 time-step별로 계산해야한다.
다만, 이 단점은 추론단계에서 어차피 decoder는 input feeding이 아니더라도 time-step별 병렬처리가 아닌 순차적 계산이 필요하기에 추론 시 input feeding으로 인한 속도 저하는 거의 없다; 따라서 이 단점이 크게 부각되지는 않는다.
5.1 AR(Auto Regressive) 속성 seq2seq의 train과 inference의 근본적인 차이는 AR속성으로 발생한다.
자기회귀(AR): 과거 자신의 값을 참조해 현재의 값을 추론하는 특징 이를 아래 수식에서도 확인할 수 있다.
다만, 과거의 결과값에따라 문장이나 시퀀스의 구성이 바뀔뿐만아니라 예측문장시퀀스의 길이도 바뀔 수 있고, 과거에 잘못된 예측을 했을 때, 더 큰 잘못된 예측을 할 가능성을 야기하기도 한다.
학습과정에서는 이미 정답을 알고있고 현재모델의 예측값과 정답과의 차이를 통해 학습하기에 자기회귀(AR)속성을 유지한 채 훈련할 수는 없다.
따라서 Teacher Forcing이라 불리는 방법을 통해 훈련을 진행한다.
5.2 Teacher Forcing 훈련방법 Teacher Forcing은 훈련 시 decoder의 입력으로 이전 time-step의 decoder 출력값이 아닌, 정답 Y가 들어간다는 점이다. 하지만 추론 시, 정답 Y를 모르기에 이전 time-step에서 계산되어 나온 y_hat값을 decoder의 입력으로 사용한다. 이렇게 입력을 넣어주는 훈련방법을 teacher forcing이라 한다.
이점: 초기 훈련 단계에서 안정적인 학습을 돕고, 모델이 초기에 어떤 것을 생성해야 하는지에 대한 강력한 신호를 제공한다. 모델이 정답 레이블을 보고 학습하므로 기울기소실 문제를 완화하여 그래디언트가 더 잘 흐를 수 있습니다.
cf) LM의 Teacher Forcing [훈련 과정] 모델을 훈련할 때, 각 시점에서 이전 시점의 모델 출력이 아닌 실제 정답 레이블을 입력으로 제공한다. 즉, 이전 시점의 출력이 아닌 "선생님(teacher)" 역할의 정답 데이터를 사용한다.
[테스트(추론) 과정] 모델이 훈련을 마친 후에는 이전 출력을 입력으로 사용하여 시퀀스를 생성한다. 이때 이전 시점의 출력을 "자기 회귀적으로(autoregressively)" 사용한다.
6. Searching Algorithm(Inference). &. Beam Search
X가 주어졌을 때, Y_hat을 추론하는 방법에 대해 이야기 해보자.
이런 과정을 추론 또는 탐색(search)이라 부르는데, 탐색알고리즘에 기반하기 때문이다.
즉, 우리가 원하는 단어들 사이 최고의 확률을 갖는 경로(path)를 찾는 과정이다.
6.1 sampling 가장 정확한 방법은 time-step별 y_hat을 고를 때, 마지막 softmax층에서의 확률분포대로 sampling하는 것이다. 그 후 time-step에서 그 선택(y_hat)을 기반으로 그 다음 y_hat을 또 다시 sampling해 최종적으로 EOS가 나올때 까지 sampling하는 것이다.
다만, 이런 방식은 같은 입력에 대해 매번 다른 출력결과물이 나올 수 있어 지양하는편이다.
6.2 Greedy Search Algorithm 활용 DFS, BFS, DP 등 수많은 탐색기법이 존재하지만 Greedy Search Algorithm을 기반으로 탐색을 구현해보자. 즉, 모든 time-step에 대한 softmax확률값들 중 가장 확률값이 큰 인덱스를 뽑아 그 time-step의 y_hat을 사용하는 것이다.
즉, 각 출력 예측 시 각 step에서 가장 가능성 높은 단어를 선택해 매우 빠른 탐색이 가능하다.
단점 1.) Decision을 되돌릴 수 없게 될 수 있고 단점 2.) 최종출력이 최적화된 결과에서 멀어질 수 있다. (∵ <END>token 생성전까지 decoding을 진행하기 때문)
Pytorch 예제
def search(self, src, is_greedy=True, max_length=255):
if isinstance(src, tuple):
x, x_length = src
mask = self.generate_mask(x, x_length)
else:
x, x_length = src, None
mask = None
batch_size = x.size(0)
# Same procedure as teacher forcing.
emb_src = self.emb_src(x)
h_src, h_0_tgt = self.encoder((emb_src, x_length))
decoder_hidden = self.fast_merge_encoder_hiddens(h_0_tgt)
# Fill a vector, which has 'batch_size' dimension, with BOS value.
y = x.new(batch_size, 1).zero_() + data_loader.BOS
is_decoding = x.new_ones(batch_size, 1).bool()
h_t_tilde, y_hats, indice = None, [], []
# Repeat a loop while sum of 'is_decoding' flag is bigger than 0,
# or current time-step is smaller than maximum length.
while is_decoding.sum() > 0 and len(indice) < max_length:
# Unlike training procedure,
# take the last time-step's output during the inference.
emb_t = self.emb_dec(y)
# |emb_t| = (batch_size, 1, word_vec_size)
decoder_output, decoder_hidden = self.decoder(emb_t,
h_t_tilde,
decoder_hidden)
context_vector = self.attn(h_src, decoder_output, mask)
h_t_tilde = self.tanh(self.concat(torch.cat([decoder_output,
context_vector
], dim=-1)))
y_hat = self.generator(h_t_tilde)
# |y_hat| = (batch_size, 1, output_size)
y_hats += [y_hat]
if is_greedy:
y = y_hat.argmax(dim=-1)
# |y| = (batch_size, 1)
else:
# Take a random sampling based on the multinoulli distribution.
y = torch.multinomial(y_hat.exp().view(batch_size, -1), 1)
# |y| = (batch_size, 1)
# Put PAD if the sample is done.
y = y.masked_fill_(~is_decoding, data_loader.PAD)
# Update is_decoding if there is EOS token.
is_decoding = is_decoding * torch.ne(y, data_loader.EOS)
# |is_decoding| = (batch_size, 1)
indice += [y]
y_hats = torch.cat(y_hats, dim=1)
indice = torch.cat(indice, dim=1)
# |y_hat| = (batch_size, length, output_size)
# |indice| = (batch_size, length)
return y_hats, indice
6.3 Beam Search Greedy Algorithm은 매우 쉽고 간단하지만, 최적(optimal)해는 보장하지 않는다. 따라서 약간의 trick을 가미하는데, k개의 후보를 더 추적하는 것이다. 이때, k를 beam_size라 한다.
Beam_size k에 대해 step이 진행되면서 k개의 가짓수에 대해 k를 유지, 최종 후보군에서 확률이 가장 높은 것을 선택한다. 다른 time-step에서 <END>token 생성이 가능하며 하나의 가설(hypothesis)에서 <END>가 나오면 종료하고, 다른 가설분기를 계속 탐색한다. 즉, 단어가 순차적 생성되어 동시사건확률 고려 및 생성할 때마다 log값이 더해져 더해지는 음수값이 많아져 작은값이 되는, 일종의 Normalize하는 과정을 한번 더 거칠 수 있게 된다.
∙ small k - greedy와 거의 비슷하다.(= ungrammatic, unnatural, nonsensical, incorrect)
∙ Large k - k가 커질수록 greedy문제는 줄지만 계산비용이 커진다. - BLEU_Score가 떨어지는 문제가 발생한다. (∵ too-short translation)
따라서 보통 Beam_size를 10 이하로 사용한다.
Pytorch 예제
#@profile
def batch_beam_search(
self,
src,
beam_size=5,
max_length=255,
n_best=1,
length_penalty=.2
):
mask, x_length = None, None
if isinstance(src, tuple):
x, x_length = src
mask = self.generate_mask(x, x_length)
# |mask| = (batch_size, length)
else:
x = src
batch_size = x.size(0)
emb_src = self.emb_src(x)
h_src, h_0_tgt = self.encoder((emb_src, x_length))
# |h_src| = (batch_size, length, hidden_size)
h_0_tgt = self.fast_merge_encoder_hiddens(h_0_tgt)
# initialize 'SingleBeamSearchBoard' as many as batch_size
boards = [SingleBeamSearchBoard(
h_src.device,
{
'hidden_state': {
'init_status': h_0_tgt[0][:, i, :].unsqueeze(1),
'batch_dim_index': 1,
}, # |hidden_state| = (n_layers, batch_size, hidden_size)
'cell_state': {
'init_status': h_0_tgt[1][:, i, :].unsqueeze(1),
'batch_dim_index': 1,
}, # |cell_state| = (n_layers, batch_size, hidden_size)
'h_t_1_tilde': {
'init_status': None,
'batch_dim_index': 0,
}, # |h_t_1_tilde| = (batch_size, 1, hidden_size)
},
beam_size=beam_size,
max_length=max_length,
) for i in range(batch_size)]
is_done = [board.is_done() for board in boards]
length = 0
# Run loop while sum of 'is_done' is smaller than batch_size,
# or length is still smaller than max_length.
while sum(is_done) < batch_size and length <= max_length:
# current_batch_size = sum(is_done) * beam_size
# Initialize fabricated variables.
# As far as batch-beam-search is running,
# temporary batch-size for fabricated mini-batch is
# 'beam_size'-times bigger than original batch_size.
fab_input, fab_hidden, fab_cell, fab_h_t_tilde = [], [], [], []
fab_h_src, fab_mask = [], []
# Build fabricated mini-batch in non-parallel way.
# This may cause a bottle-neck.
for i, board in enumerate(boards):
# Batchify if the inference for the sample is still not finished.
if board.is_done() == 0:
y_hat_i, prev_status = board.get_batch()
hidden_i = prev_status['hidden_state']
cell_i = prev_status['cell_state']
h_t_tilde_i = prev_status['h_t_1_tilde']
fab_input += [y_hat_i]
fab_hidden += [hidden_i]
fab_cell += [cell_i]
fab_h_src += [h_src[i, :, :]] * beam_size
fab_mask += [mask[i, :]] * beam_size
if h_t_tilde_i is not None:
fab_h_t_tilde += [h_t_tilde_i]
else:
fab_h_t_tilde = None
# Now, concatenate list of tensors.
fab_input = torch.cat(fab_input, dim=0)
fab_hidden = torch.cat(fab_hidden, dim=1)
fab_cell = torch.cat(fab_cell, dim=1)
fab_h_src = torch.stack(fab_h_src)
fab_mask = torch.stack(fab_mask)
if fab_h_t_tilde is not None:
fab_h_t_tilde = torch.cat(fab_h_t_tilde, dim=0)
# |fab_input| = (current_batch_size, 1)
# |fab_hidden| = (n_layers, current_batch_size, hidden_size)
# |fab_cell| = (n_layers, current_batch_size, hidden_size)
# |fab_h_src| = (current_batch_size, length, hidden_size)
# |fab_mask| = (current_batch_size, length)
# |fab_h_t_tilde| = (current_batch_size, 1, hidden_size)
emb_t = self.emb_dec(fab_input)
# |emb_t| = (current_batch_size, 1, word_vec_size)
fab_decoder_output, (fab_hidden, fab_cell) = self.decoder(emb_t,
fab_h_t_tilde,
(fab_hidden, fab_cell))
# |fab_decoder_output| = (current_batch_size, 1, hidden_size)
context_vector = self.attn(fab_h_src, fab_decoder_output, fab_mask)
# |context_vector| = (current_batch_size, 1, hidden_size)
fab_h_t_tilde = self.tanh(self.concat(torch.cat([fab_decoder_output,
context_vector
], dim=-1)))
# |fab_h_t_tilde| = (current_batch_size, 1, hidden_size)
y_hat = self.generator(fab_h_t_tilde)
# |y_hat| = (current_batch_size, 1, output_size)
# separate the result for each sample.
# fab_hidden[:, begin:end, :] = (n_layers, beam_size, hidden_size)
# fab_cell[:, begin:end, :] = (n_layers, beam_size, hidden_size)
# fab_h_t_tilde[begin:end] = (beam_size, 1, hidden_size)
cnt = 0
for board in boards:
if board.is_done() == 0:
# Decide a range of each sample.
begin = cnt * beam_size
end = begin + beam_size
# pick k-best results for each sample.
board.collect_result(
y_hat[begin:end],
{
'hidden_state': fab_hidden[:, begin:end, :],
'cell_state' : fab_cell[:, begin:end, :],
'h_t_1_tilde' : fab_h_t_tilde[begin:end],
},
)
cnt += 1
is_done = [board.is_done() for board in boards]
length += 1
# pick n-best hypothesis.
batch_sentences, batch_probs = [], []
# Collect the results.
for i, board in enumerate(boards):
sentences, probs = board.get_n_best(n_best, length_penalty=length_penalty)
batch_sentences += [sentences]
batch_probs += [probs]
return batch_sentences, batch_probs
7.1 정성적 평가 (Intrinsic Evaluation) 보통 사람이 번역된 문장을 채점하는 형태 이때, 사람의 선입견이 반영될 수 있기에 보통 blind test와 같은 방식을 고수한다. 가장 정확할 수는 있지만 자원과 시간이 많이 든다는 단점이 존재한다.
이후 구글의 번역시스템을 알아볼 때, 구글에서 정성적 평가를 통해 얻은 점수에 대해 알아볼 것이다.
7.2 정량적 평가 (Extrinsic Evaluation) 위에서 언급한 정성적 평가의 단점으로 인해 보통 자동화된 정량평가를 주로 사용한다. 이때, 최대한 비슷한 일관성을 갖는 평가를 해야하며, 언어적 특징이 반영된 평가방법이라면 더더욱 좋을 것이다.
PPL (Perplexity) NMT도 기본적으로 매 time-step마다 최고확률을 갖는 단어를 선택(classification)하는 작업이기에 Cross Entropy를 기본적인 Loss Function으로 사용한다. NMT또한 조건부 언어모델이기에 PPL를 통한 성능측정이 가능하다.
결과적으로 Cross-Entropy에 exp를 취한 PPL을 평가지표로 활용가능하다. (PPL이 낮을수록, N-gram의 N이 클수록 좋은 모델 ; https://chan4im.tistory.com/200#n3) CE와 직결되어 간편함이 있다는 장점이 있지만, 실제 번역기 성능과 완벽한 비례관계에 있다 할 수는 없다.
각 time-step별 실제 정답에 해당하는 단어의 확률만 채점하기 때문이다. 하지만 언어는 같은 의미의 문장들이라도 어순이 바뀔수도 있고, 비슷한 의미의 단어로 치환될 수도 있기에 완전히 잘못된 번역이더라도 Loss값이 낮을수도 있다.
따라서 실제 번역문의 품질과 CE사이에는 괴리가 존재한다. (특히나 Teacher Forcing방식이 더해지기에 더더욱 괴리가 존재한다.)
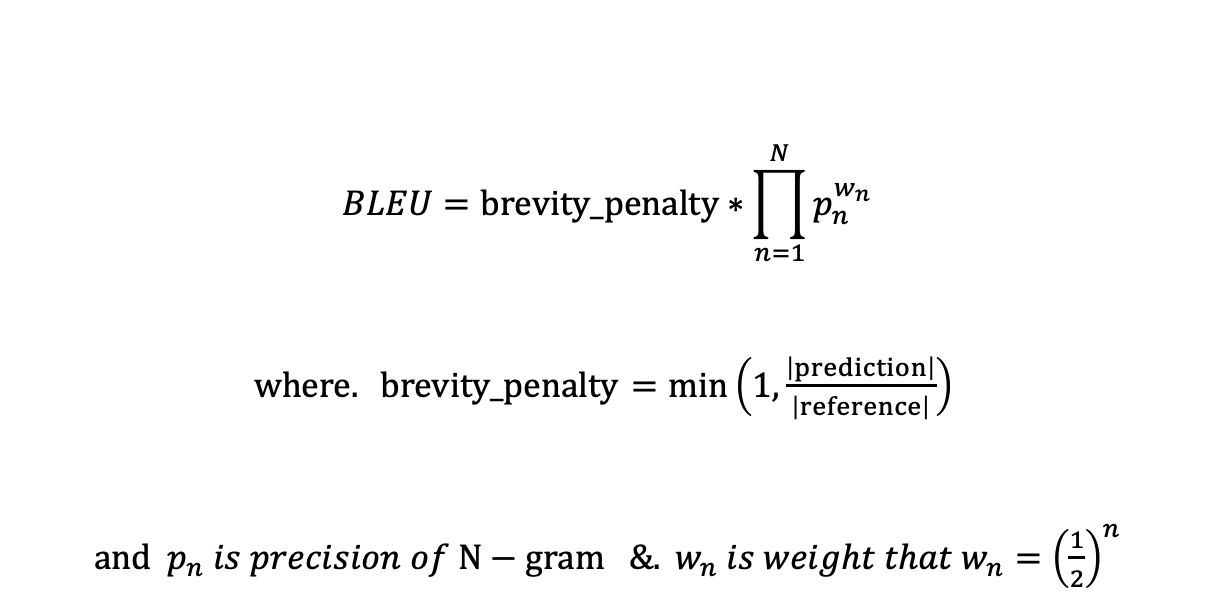
BLEU (Bi-Lingual Evaluation Understudy) 위에서 말한 PPL에서 CE의 괴리를 줄이기 위해 여러 방법들이 제시되었는데, 가장 대표적인 BLEU에 대해 알아보고자 한다. BLEU Score는 정답과 예측문장간에 일치하는 N-gram 개수의 비율의 기하평균에 따라 점수를 매긴다. 즉, 각 N-gram별 precision의 평균을 백분율로 나타내는 것이고 짧은문장에대한 페널티(brevity_penalty)는 예측된 번역문이 정답문장보다 짧을경우, 점수가 좋아지는 것을 방지하기 위한 것이다. BLEU Score가 높을수록 좋은 모델임을 의미한다.
또한, 실제 성능측정 시, BLEU를 직접구현하기보단 SMT Framework인 MOSES에 포함된 multi-bleu.perl을 주로 사용한다.
METEOR (Metric for Evaluation of Translation with Explicit ORdering) METEOR는 NMT 및 NLP생성 작업에서 사용되는 자동 평가지표 중 하나이다. METEOR는 번역 품질을 측정하고 참조(reference) 번역과 생성된 번역 간의 유사성을 판단한다. METEOR는 BLEU와 유사한 목적을 가지고 있지만 몇 가지 중요한 차이점이 있다.
Main 주안점) BLEU로부터 파생된 방법으로 BLEU의 불완전함을 보완하고 더 나은 지표를 설계하고자 BLEU와의 가장 큰 차이점으로 precision만 고려하는 BLEU와는 달리 - recall도 함께 고려했다는 것이다. - 추가적으로 다른 가중치를 적용한 이 둘의 조화평균을 성능 계산에 활용하고, - 오답에 대해 별도의 penalty를 부과하는 방식을 채택하거나, - 여러 단어나 구 등을 정답으로 처리하는 등 BLEU를 보완하고자 했다. METEOR의 주요 특징과 작동 방식은 다음과 같다:
∙ 항목 정확도 (Precision): METEOR는 단어나 구절 수준의 일치를 측정한다. 번역 후보와 참조 번역 간의 공통된 토큰 (단어 또는 구절) 수를 계산한다. 이것은 "항목 정확도" 또는 "Precision"으로 알려져 있습니다. 수식은 아래와 같다.
∙ 기하 평균 F1 점수: METEOR는 정확도와 리콜(recall) 간의 균형을 측정하기 위해 정확도와 리콜의 조화 평균인 F1 점수를 계산합니다. 이것은 번역 후보의 정확성과 참조 번역과의 유사성을 모두 고려합니다. 수식은 아래와 같다.
penalty의 경우, 아래와 같이 계산되며
최종적인 METEOR Score는 아래와 같다.
∙ 번역 후보와 참조 번역 사이의 어휘와 구조적 변화: METEOR은 단어의 순서와 구조적 변경을 포함한 다양한 어휘와 문법적인 변화를 고려합니다. 이것은 단어 순서를 보다 강조하는 특징이 있으며, 번역 후보와 참조 번역 간의 공통 어휘 및 구조를 비교합니다.
∙ 어휘, 구절 정렬 및 동의어 처리: METEOR은 어휘의 동의어 처리를 수행하며, 구절 정렬과 유사성을 계산하는 데 사용됩니다.
METEOR의 결과는 0과 1 사이의 점수로 나타납니다. 높은 METEOR 점수는 번역이 참조 번역과 유사하다는 것을 나타내며, 높은 번역 품질을 의미합니다. METEOR는 주로 번역 품질 평가를 위해 사용되며, 다양한 자연어 처리 작업에서도 적용될 수 있습니다.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) ROUGE는 NLP에서 사용되는 자동 평가지표 중 하나로, 텍스트 생성 및 자동 요약 작업에서 많이 사용된다. ROUGE는 생성된 텍스트 또는 요약과 기준(reference) 텍스트 간의 유사성을 측정하고 평가하는 데 사용된다. ROUGE는 5개의 평가 지표가 있다. - ROUGE-N - ROUGE-L - ROUGE-W - ROUGE-S - ROUGE-SU
∙ ROUGE-N (ROUGE-Ngram) ROUGE-N 메트릭은 N-gram (연속된 n개의 단어 또는 문자) 일치를 측정한다. 일반적으로 ROUGE-1, ROUGE-2, ROUGE-3 등과 같이 지정된 n-gram 길이를 나타낸다.
즉, ROUGE-N은 예측한 요약문과 실제 요약문간의 N-gram의 Recall값으로 쉽게 나타내면 아래와 같다.
‣ ROUGE-1: 1-gram (unigram) = 단어 단위의 일치를 계산 ‣ ROUGE-2: 2-gram (bigram) 단위의 일치를 계산 ‣ ROUGE-3: 3-gram (trigram) 단위의 일치를 계산 ROUGE-N은 유사성을 측정하고 단어 순서를 고려하지 않는다.
ex) ROUGE-1 ∙실제 요약문 uni-gram: 'Korea', 'won', 'the', 'world', 'cup' ∙예측 요약문 uni-gram: 'Korea', 'won', 'the', 'soccer', 'world', 'cup', 'final' 예측 요약문과 실제 요약문 사이에 겹치는 uni-gram 수는 5이고, 실제 요약문의 uni-gram수도 5이므로 ∙ROUGE-1 = 5/5 = 1
ex) ROUGE-2 ∙실제 요약문 bi-gram: 'Korea won', 'won the', 'the world', 'world cup' ∙예측 요약문 bi-gram: 'Korea won', 'won the', 'the soccer', 'soccer world', 'world cup', 'cup final' 예측 요약문과 실제 요약문 사이에 겹치는 bi-gram 수는 3이고, 실제 요약문의 bi-gram수는 4이므로 ∙ROUGE-2 = 3/4 = 0.75