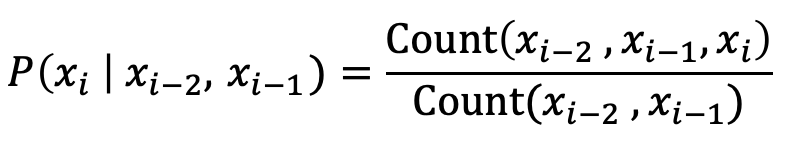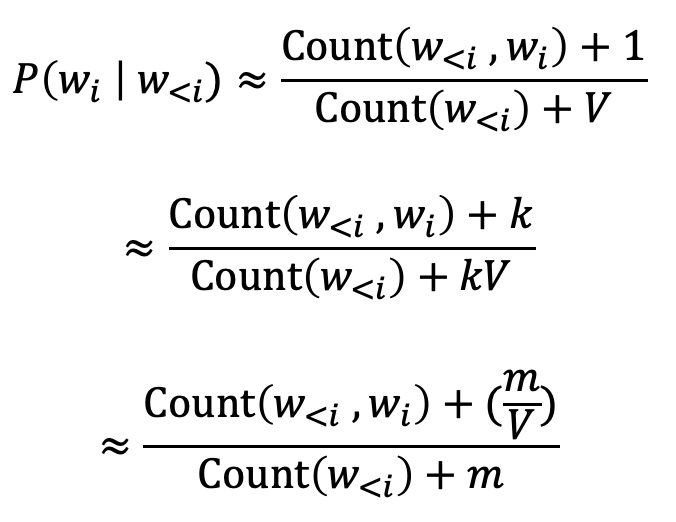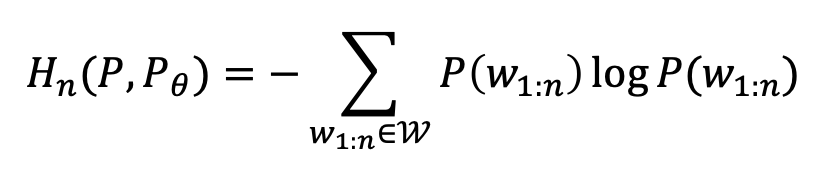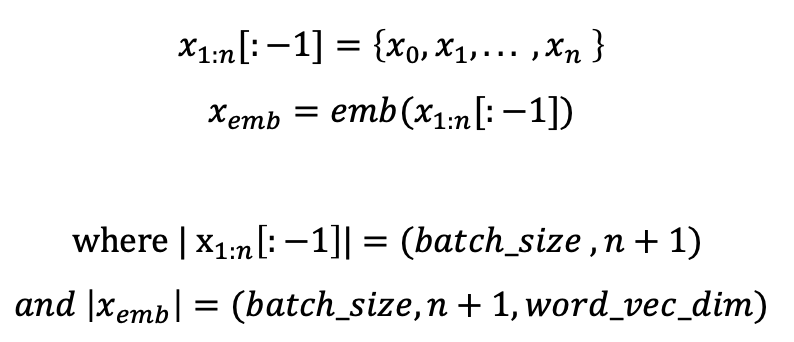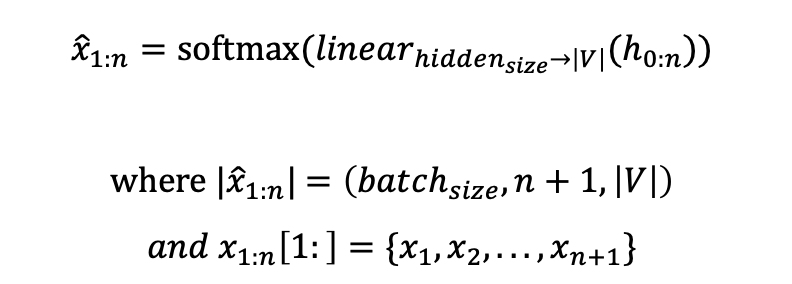1.1 LM (Language Model) 언어모델(LM; Language Model)은 문장의 확률을 나타내는 모델이다. 확률값을 통해 문장 자체의 출현확률, 이전단어들에 대해 다음단어를 예측할 수 있다. 결과적으로 주어진 문장이 얼마나 자연스럽고 유창한지(fluent) 계산할 수 있다.
1.2 Hell 난이도, 한국어 ∙ 한국어: 대표적인 교착어 ∙ 영어: 고립어(+ 굴절어) ∙ 중국어: 고립어
교착어의 특징상 단어의 의미나 역할은 어순보다는 단어에 부착되는 어미같은 접사나 조사에 의해 결정된다. 즉, 단어의 어순이 중요하지않고 생략 또한 가능하기에 단어간에 확률계산 시 불리하다.
영어나 기타 라틴어 기반 언어들은 어순이 더 규칙적이기에 한국어에 비해 헷갈릴 가능성이 낮다. 추가적으로 한국어는 교착어의 특징상 접사 및 조사로 단어의 의미∙역할이 결정되기에 아래와 같이 여러 조사가 붙어 수많은 단어로 파생될 수 있다. ex) 학교에, 학교에서, 학교에서도, 학교를, 학교로, 학교가, 학교조차도, . . .
따라서 어미를 분리해주지 않으면 어휘의 수가 기하급수적으로 늘기에 희소성이 높아져 문제해결이 더 어려워질 수 있다.
2.2Markov Assumption corpus에서 word sequence에 대한 확률을 효과적으로 추정하려면 희소성문제를 해결해야한다. 이때, Markov 가정(Markov Assumption)을 도입한다.
Markov 가정이란?? 특정시점의 상태확률은 단지 그 직전 상태에만 의존한다는 논리. 즉, 앞서 출현한 모든 단어를 살펴볼 필요없이, 앞의 k개의 단어(= 바로 직전 상태)만 보고 다음 단어의 출현확률을 구하는 것.
식으로 나타내면 위와 같은데, 이렇게 조건을 간소화해 실제로 구하고자하는 확률을 근사한다. 보통 k는 0~3의 값을 갖는다.(k=2라면, 앞 2개단어를 참조해 다음 단어 xi의 확률을 근사해 나타낸다.)
여기에 Chain Rule을 적용하고 로그확률로 표현하면 아래와 같다. 이렇게 전체 단어를 조합하는 대신, 바로 앞의 일부 조합만 출현빈도를 계산해 확률을 추정하는 방법을 N-gram이라 부른다. (이때, N = k+1)
corpus의 양과 N의 수치는 보통 비례하는데, N이 커질수록 우리가 가진 train corpus에 존재하지 않을 가능성이 높기에 정확한 추정이 어려워진다.
k (N=k+1)
N-gram
명칭
0
1-gram
uni-gram
1
2-gram
bi-gram
2
3-gram
tri-gram
따라서 보통 3-gram을 가장 많이 사용하며, train data가 매우 충분하다면, 4-gram을 사용하기도 한다.(사실 그렇게 큰 효율성은 없음 ) ∵ 4-gram을 사용하면 모델의 성능은 크게 오르지 않지만 단어 조합의 경우의 수는 지수적으로 증가하기 때문
ex) 3-gram ∙ 3-gram의 가정에 따라, 다음과 같이 3개 단어의 출현빈도와 앞 2개의 출현빈도만 구하면 xi의 확률을 근사할 수 있다.
즉, 문장전체의 확률에 비해 Markov가정을 도입하면, 문장의 확률을 근사할 수 있다. 이렇게 되면, train corpus에서 보지못한 문장에 대해서도 확률을 추정할 수 있다.
2.3Generalization train data에 없는 unseen sample의 예측능력 (= 일반화 능력)에 성능이 좌우된다. N-gram역시 Markov가정의 도입으로 희소성에 대처하는 일반화능력을 어느정도 갖는다.
더욱 일반화 능력을 향상시킬 수 있는 방법들을 살펴보도록 하자.
Smoothing & Discounting 출현 횟수를 단순히 확률값으로 추정한다면...? train corpus에 출현하지 않는 단어 corpus에 대처능력이 저하된다. 즉, unseen word sequence라고해서 확률을 0으로 추정해버리게 된다. ∴ 출현빈도값(word frequency)이나 확률값을 더욱 다듬어(smoothing)줘야 한다. 가장 간단한 방법은 모든 word sequence의 출현빈도에 1을 더하는 것이다. 이를 수식으로 나타내면 아래와 같다. 이 방법은 매우 간단하고 직관적이지만, LM처럼 희소성 문제가 클 경우 사용은 비적절하다. 이와 관련해 Naïve Bayes 등을 활용하는 내용을 전에 다뤘다.(https://chan4im.tistory.com/199#n2)
Kneser-Ney Discounting Smoothing의 희소성문제 해결을 위해 KN(Kneser-Ney) Discounting을 제안한다.
❗️핵심 아이디어 ∙ 단어 w가 다른 단어 v의 뒤에 출현 시, 얼마나 다양한 단어 뒤에서 출현하는지(= 즉, v가 얼마나 다양한 지)를 알아내는 것 ∙ 다양한 단어 뒤에 나타나는 단어일수록 unseen word sequence로 나타날 가능성이 높다는 것이다.
KN Discounting은 Scorecontinuation을 다음과 같이 모델링하는데, 즉, w와 함께 나타난 v들의 집합인 {v:Count(v,w)>0}의 크기가 클수록 Scorecontinuation은 클 것이라 가정한다. 수식은 아래와 같다. 위의 수식을 아래와 같은 과정으로 진행해보자. w와 함께 나타난 v들의 집합 {v : Count(v:w)>0}의 크기를 전체 단어 집합으로부터 sampling한 w'∈W일때 v, w'가 함께 나타난 집합{v:Count(v,w')>0}의 크기합으로 나눈다. 수식은 아래와 같다. 이렇게 우린 bi-gram을 위한 PKN을 아래 수식처럼 정의할 수 있다. 이때, d는 상수로 보통 0.75의 값을 갖는다. 이처럼 KN Discounting은 간단한 직관에서 출발해 복잡한 수식을 갖는다. 여기서 약간의 수정을 가미한, Modified-KN Discounting이 보편적인 방법이다. cf) 언어모델툴킷(SRILM)에 구현되어있는 기능을 통해 쉽게 사용할 수 있다.
Interpolation 다수의 LM사이의 선형결합(interpolation)을 통해 LM을 일반화해보자. LM의 interpolation이란, 2개의 서로다른 LM을 선형적으로 일정비율(λ)로 섞어주는 것이다.
특정 영역에 특화된 LM구축 시, interpolation은 굉장히 유용한데, 특정영역의 작은 corpus로 만든 LM과 섞음으로써 특정영역에 특화된 LM을 강화할 수 있다. 예를 들어 의료분야음성인식이나 기계번역시스템 구축을 가정해보자. 기존의 일반 영역 corpus를 통해 생성한 LM이라면 의료용어표현이 낯설 수 있다. 반대로 특화영역의 corpus만 사용해 LM을 생성한다면, generalization능력이 지나치게 떨어질 수 있다.
∙ 일반 영역 - P(진정제 | 준비,된) = 0.00001 - P(사나이 | 준비,된) = 0.01
결국 일반적인 의미와는 다른 뜻의 단어가 나올수도 있고, 일반적인 대화에서는 희소한 word sequence가 훨씬 자주 등장할 수도 있다. 또한, 특화영역의 corpus에는 일반적인 word sequence가 매우 부족할 것이다. 이런 문제점들을 해결하기 위해 각 영역의 corpus로 생성한 LM을 섞어주어 해당영역에 특화할 수 있다.
Back-Off 너무 길거나 복잡한 word sequence는실제 train corpus에서 굉장히 희소하다. 따라서 Markov 가정을 통해 일반화가 가능하며, Back-Off방식은 한단계 더 나아간 방식이다.
아래 수식을 보면, 특정 N-gram의 확률을 N보다 더 작은 sequence에 대해 확률을 구해 interpolation을 진행한다. 예를 들어 3-gram의 확률에 대해 2-gram, 1-gram의 확률을 interpolation을 할 때, 이를 수식으로 나타내면 다음과 같이 N보다 더 작은 sequence의 확률을 활용함으로써 더 높은 smoothing&generalization 효과를 얻을 수 있다.
2.4Conclusion N-gram방식은 출현빈도를 통해 확률을 근사하기에 매우 쉽고 간편하다.
Prob) 다만 단점 또한 명확한데, train corpus에 등장하지 않는 단어 corpus의 경우, 확률을 정확히 알 수 없다.
Sol) 따라서 Markov 가정을 통해 단어 조합에 필요한 조건을 간소화할 수 있고 더 나아가 Smoothing, Back-Off 등으로 단점을 보완하였다.
하지만 여전히 근본적 해결책은 아니며, 현재 DNN의 도입은 음성인식, 기계번역에 사용되는 LM에 큰 빛을 가져다 주었다. DNN시대에서도 여전히 N-gram방식은 강력하게 사용될 수 있는데, 문장을 생성하는 것이 아닌, 주어진 문장의 유창성(fluency)을 채점하는 문제라면, 굳이 복잡한 DNN이 아니더라도 N-gram방식이 여전히 좋은 성능을 낼 수 있다. (DNN이 얻는 사소한 이득은 매우 귀찮고 어려운 일이 될 것.)
3. LM - Metrics
3.1 PPL (Perplexity) LM의 평가척도인 perplexity(PPL)을 측정하는 정량평가(extrinsic evaluation) 방법이다. PPL은 문장의 길이를 반영, 확률값을 정규화한 값이다.
문장의 확률값이 분모에 있기에 확률값이 높을수록 PPL은 작아진다. 따라서 PPL값이 작을수록, N-gram의 N이 클수록 더 좋은 모델이다.
3.2 PPL의 해석 출현확률이 n개라면, 매 time-step으로 가능한 경우의 수가 n인 PPL로 PPL은 일종의 n개의 branch의 수(뻗어나가는 수)를 의미하기도 한다.
ex) 20,000개의 vocabulary라면, PPL은 20,000이다. (단, 단어출현확률이 모두 같을때)
하지만만약 3-gram기반 LM으로 측정한 PPL이 30이 나왔다면 평균적으로 30개의 후보단어 중에 헷갈리고 있다는 것으로 다음 단어 예측 시, 30개의 후보군중 고르는 경우로 알 수 있다.
3.3 PPL과 Entropy의 관계 앞서 언급했듯, 정보량의 평균을 의미하는 Entropy의 경우, ∙ 정보량이 낮으면 확률분포는 sharp한 모양이고 ∙ 정보량이 높으면 확률분포는 flat한 모양이 된다. 먼저 실제 LM의 분포 P(x)나 출현가능문장들의 집합 W에서 길이 n의 문장 w1:n을 sampling 시, 우리의 LM분포 Pθ(x)의 entropy를 나타낸 수식은 아래와 같다.
여기서 몬테카를로(Monte Carlo) sampling을 통해 위의 수식을 근사시킬 수 있다.
앞서와 같이 entropy H식을 근사시킬 수 있지만, 사실 문장은 sequential data이기에 entropy rate라는 개념을 사용하면 아래처럼 단어당 평균 entropy로 나타낼 수 있다. 마찬가지로 Monte Carlo sampling을 적용할 수 있다.
이 수식을 조금만 더 바꾸면, 아래와 같다.
여기에 PPL 수식을 생각해보면 앞서 Cross-Entropy로부터 도출한 수식과 비슷한 형태임을 알 수 있다.
최종적으로 PPL과 CE의 관계는 아래와 같다.
∴ MLE를 통해 parameter θ 학습 시, CE로 얻는 손실값에 exp를 취함으로써 PPL을 얻을 수 있다.
4. SRILM을 활용한 N-gram 실습
SRILM은 음성인식∙segmentation∙MT(기계번역) 등에 사용되는 n-gram 모델을 쉽게 구축하고 적용하능한 Tool-kit이다.
4.2 Dataset 준비 이전 전처리 장에서 다뤘던 것처럼 분절이 완료된 파일을 데이터로 사용한다. 이후 파일을 train data와 test data로 나눈다.
4.3 기본 사용법 SRILM에서 사용되는 프로그램들의 주요인자 설명
∙ ngram-count : LM 훈련
∙ vocab : lexicon file_name
∙ text : training corpus file_name
∙ order : n-gram count
∙ write : output count file_name
∙ unk : mark OOV as
∙ kndiscountn : Use Kneser -Ney discounting for N-grams of oerder n
∙ ngram : LM 활용
∙ ppl : calculate perplexity for test file name
∙ order : n-gram count
∙ lm : LM file_name
LM 만들기 ex) kndiscount를 사용한 상태에서 3-gram을 훈련, LM과 LM을 구성하는 vocabulary를 출력하는 과정
문장 생성하기 N-gram모듈을 사용해 만들어진 LM을 활용해 문장을 생성해보자. 문장 생성 이후 전처리(https://chan4im.tistory.com/195)에서 설명했듯, 분절을 복원해줘야 한다. 이때, 아래 예시는 Linux의 pipeline을 연계해 sed를 통한 정규표현식을 사용해 분적을 복원한다.
$ ngram -lm <input_lm_fn> -gen <n_sentence_to_generate> | sed "s/ // g" | sed "s/__//g" | sed "s/_//g" | sed "s/^\s//g"
interpolation 이후 성능평가 시, 경우에 따라 성능향상을 경험할 수 있으며 λ를 튜닝함으로써 성능향상 폭을 더 높일 수 있다.
5. NNLM
5.1 희소성 해결하기 N-gram기반 LM은 간편하지만 기존 corpus train data에 해당 N-gram이 없거나 존재하지 않는 단어의 조합에는 출현 빈도를 계산할 수 없어서 확률을 구할 수 없고 확률간 비교를 할 수 없는 등 상당히 generalization에 취약하다는 것을 알 수 있다.
N-gram 기반 LM의 약점을 보완하기 위해 NNLM이 나오게 되었는데, NNLM(Neural Network Language Model)은 word embedding을 사용해 단어차원축소를 통해 corpus와 유사한 dense vector를 학습하고, 더 높은 유사도를 갖게 하여 generalization 성능을 높임으로써 희소성해소(WSD)가 가능하다.
NNLM은 다양한 형태를 갖지만 가장 효율적이고 흔한형태인 RNN계열의 LSTM을 활용한 RNNLM방식에 대해 알아보자.
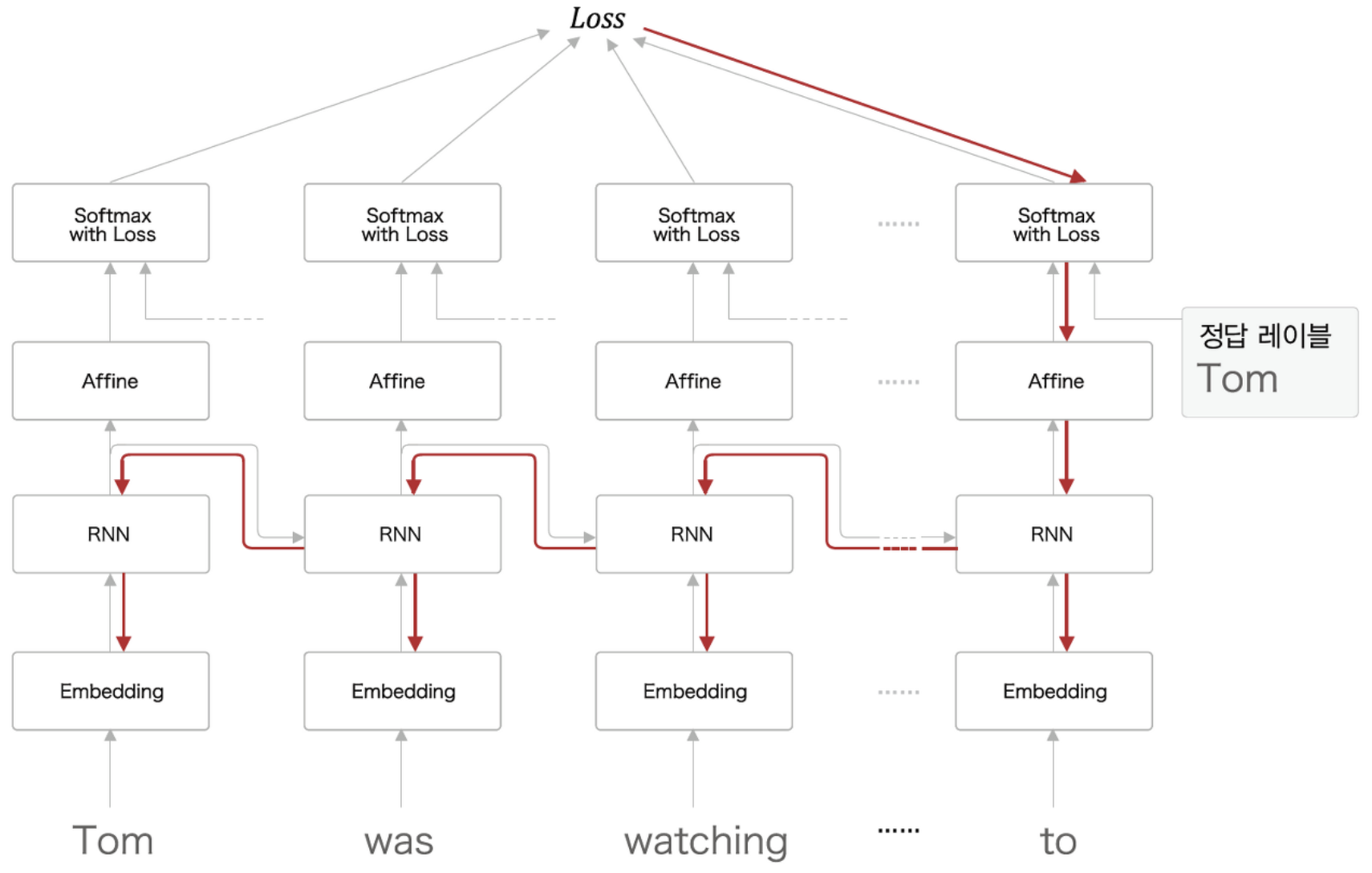
5.2 RNNLM (RNN Language Model) 기존의 LM은 각각의 단어를 불연속적 데이터로 취급해서 word sequence(단어조합)의 길이가 길어지면희소성문제로 어려움을 겪었다. 따라서 Markov가정을 통해 n-1이전까지의 단어만 주로 조건부로 사용해 확률을 근사시켰다.
하지만 RNNLM은 word embedding을 통해 dense vector를 생성하고 이를 통해 희소성문제를 해소하여 문장의 첫 단어부터 해당 단어 직전의 단어까지 모두 조건부에 넣어 확률을 근사시킬 수 있다. 여기에 로그를 넣을 수도 있는데, π를 ∑로 바꾸고 양변에 로그를 취하면 된다.
5.3 구현 수식 및 설명
이때, 입력문장의 시작과 끝에는 x0와 xn+1이 추가되어 BOS와 EOS를 나타낸다. 수식을 과정별로 설명해보면, 아래와 같다.
∙ 먼저 문장 x1:n[:-1]를 입력으로 받는다. ∙ 이후 각 time-step별 토큰 xi로 임베딩 계층 emb에 넣는다. ∙ 그 후 정해진 차원의 word embedding vector를 얻는다. ❗️주의점) EOS를 떼고 embedding layer에 input으로 넣어야한다.
❗️BOS (Beginning of Sentence): BOS는 문장의 시작을 나타내는 특별한 토큰 또는 심볼로 주로 Seq2Seq모델과 같은 모델에서 입력 시퀀스의 시작을 표시하는 데 사용된다. ex) 기계 번역 모델에서 번역할 문장의 시작을 BOS 토큰으로 표시하여 모델에게 문장을 시작하라고 알려줄 수 있습니다.
❗️EOS (End of Sentence): EOS는 문장의 끝을 나타내는 특별한 토큰 또는 심볼로 주로 Seq2Seq 모델과 같은 모델에서 출력 시퀀스의 끝을 나타내는 데 사용됩니다. ex) 기계 번역 모델이 번역을 마쳤을 때 EOS 토큰을 생성하여 출력 시퀀스가 끝났음을 나타냅니다.
RNN은 해당 word_embedding_vector를 입력으로 받고 RNN의 hidden_state_size인 hidden_size의 vector를 반환한다. 이때, pytorch를 통해 문장의 모든 time-step을 한번에 병렬로 계산할 수 있다.
여기 tensor에 linear layer와 softmax를 적용해 각 단어에 대한 확률분포인 (x_hat)_i+1를 구한다. 여기서 LSTM을 사용해 RNN을 대체할 수 있다.
test dataset에 대해 PPL을 최소화하는 것이 목표이므로 Cross Entropy Loss를 사용해 optimizing을 진행한다. 이때, 주의할 점은 입력과 반대로 BOS를 제거한 정답인 x1:n[1:]와 비교한다는 것이다.
Pytorch 구현예제
import torch
import torch.nn as nn
import data_loader
class LanguageModel(nn.Module):
def __init__(self,
vocab_size,
word_vec_dim=512,
hidden_size=512,
n_layers=4,
dropout_p=.2,
max_length=255
):
self.vocab_size = vocab_size
self.word_vec_dim = word_vec_dim
self.hidden_size = hidden_size
self.n_layers = n_layers
self.dropout_p = dropout_p
self.max_length = max_length
super(LanguageModel, self).__init__()
self.emb = nn.Embedding(vocab_size,
word_vec_dim,
padding_idx=data_loader.PAD
)
self.rnn = nn.LSTM(word_vec_dim,
hidden_size,
n_layers,
batch_first=True,
dropout=dropout_p
)
self.out = nn.Linear(hidden_size, vocab_size, bias=True)
self.log_softmax = nn.LogSoftmax(dim=2)
def forward(self, x):
# |x| = (batch_size, length)
x = self.emb(x)
# |x| = (batch_size, length, word_vec_dim)
x, (h, c) = self.rnn(x)
# |x| = (batch_size, length, hidden_size)
x = self.out(x)
# |x| = (batch_size, length, vocab_size)
y_hat = self.log_softmax(x)
return y_hat
def search(self, batch_size=64, max_length=255):
x = torch.LongTensor(batch_size, 1).to(next(self.parameters()).device).zero_() + data_loader.BOS
# |x| = (batch_size, 1)
is_undone = x.new_ones(batch_size, 1).float()
y_hats, indice = [], []
h, c = None, None
while is_undone.sum() > 0 and len(indice) < max_length:
x = self.emb(x)
# |emb_t| = (batch_size, 1, word_vec_dim)
x, (h, c) = self.rnn(x, (h, c)) if h is not None and c is not None else self.rnn(x)
# |x| = (batch_size, 1, hidden_size)
y_hat = self.log_softmax(x)
# |y_hat| = (batch_size, 1, output_size)
y_hats += [y_hat]
# y = torch.topk(y_hat, 1, dim = -1)[1].squeeze(-1)
y = torch.multinomial(y_hat.exp().view(batch_size, -1), 1)
y = y.masked_fill_((1. - is_undone).byte(), data_loader.PAD)
is_undone = is_undone * torch.ne(y, data_loader.EOS).float()
# |y| = (batch_size, 1)
# |is_undone| = (batch_size, 1)
indice += [y]
x = y
y_hats = torch.cat(y_hats, dim=1)
indice = torch.cat(indice, dim=-1)
# |y_hat| = (batch_size, length, output_size)
# |indice| = (batch_size, length)
return y_hats, indice
5.4 Conclusion NNLM은 word_embedding_vector를 사용해 희소성문제해결에 큰 효과를 본다. 결과적으로 train dataset에 없는 단어조합에도 훌륭한 대처가 가능하다.
다만, N-gram에 비해 더 많은 cost가 필요하다.
6. Language Model의 활용
Language Model을 단독으로 사용하는 경우는 매우 드물다.
다만, NLP에서 가장 기본이라 할 수 있는 LM은 매우 중요하며, 현재 DNN을 활용해 더욱 발전하고 있다.
LM은 자연어생성의 가장 기본이되는 모델이므로 활용도는 떨어질 지언정 중요성과 역할이 미치는 영향은 부인할 수 없을 것이다.
대표적 활용분야는 아래와 같다.
6.1 Speech Recognition 컴퓨터의 경우, 음소별 분류의 성능은 이미 사람보다 뛰어나다. 하지만 사람과 달리 주변 문맥정보를 활용하는 능력(= 일명 '눈치')이 없기에 주제가 전환되는 등의 상황에서 음성 인식률이 떨어지는 경우가 상당히 있다. 이때, 좋은 LM을 학습해 사용하면 음성인식의 정확도를 높일 수 있다.
아래 수식은 음성인식의 수식을 대략적으로 나타낸 것으로 음성신호 X가 주어졌을 때, 확률을 최대로 하는 문장 Y_hat을 구하는 것이 목표이다.
여기에 Bayes 정리로 수식을 전개하면, 밑변 P(X)를 날려버릴 수 있다.
∙P(X|Y) : Speech Model (= 해당 음향 signal이 나타날 확률) ∙P(Y) : Language Model (= 문장의 확률)
6.2 Machine Translation 기계번역의 경우, 언어모델이 번역시스템을 구성할 때, 중요한 역할을 한다. 기존의 통계기반 기계번역(SMT)에서는 음성인식과 유사하게 LM이 번역모델과 결합해 자연스러운 문장을 만들도록 동작한다.
6.3OCR (광학 문자 인식) 광학문자인식(OCR)를 만들 때도 LM이 사용된다. 사진에서 추출해 글자를 인식할 때, 각 글자간 확률을 정의하면 더 높은 성능을 낼 수 있다. 따라서 OCR에서도 언어모델의 도움을 받아 글자나 글씨를 인식한다.
6.4 기타 Generative Model 음성인식, MT, OCR 역시 주어진 정보를 바탕으로 문장을 생성해내는 일종의 자연어 생성이라 볼 수 있다. 기계학습의 결과물로써 문장을 만들어내는 작업은 모두 자연어 생성문제의 카테고리라 볼 수 있다.
마치며...
이번시간에는 주어진 문장을 확률적(stochastic)으로 모델링하는 방법(LM)을 알아보았다. NLP에서 문장예측의 필요성은 DNN이전부터 있어왔기에, N-gram 등의 방법으로 많은 곳에 활용되었다.
다만, N-gram과 같은 방식들은 여전히 단어를 불연속적인 존재로 취급하기에 희소성문제를 해결하지 못해 generalization에서 많은 어려움을 겪었다.
이를 위해 Markov가정, Smoothing, Didcounting으로 N-gram의 단점을 보완하고자 했지만 N-gram은 근본적으로 출현빈도에 기반하기에 완벽한 해결책이 될 수는 없었다. 하지만 DNN의 도입으로 LM을 시도하면 Generalization이 가능하다. DNN은 비선형적 차원축소에 매우 뛰어난 성능을 갖기에, 희소단어조합에도 효과적 차원축소를 통해 뛰어난 성능을 낼 수 있다. 따라서 inference time에서 처음보는 sequence data가 주어지더라도 기존에 비해 기존 학습을 기반으로 훌륭한 예측이 가능하다.