1.1 전이학습(Transfer Learning) ∙전이학습: 신경망의 일부or전체를 MLE를 통해 train하기 전, 다른 dataset이나 목적함수로 미리 훈련한 후, 본격적인 학습에서는 가중치를 더 쉽게 최적화하는 것이다.
이미 예전부터 Vision분야에서는 ImageNet같은 weight값을 다른 문제에 전이학습을 적용하는 접근방식이 흔하게 사용되었다. 하지만 NLP에서 여러 전이학습 방법들이 제시되면서 점차 주류로 잡아가고 있다.
더 넓은 범위의 목적(objective)을 갖는 Unsupervised Learning문제의 Global-minima는 더 작은 범위의 목적을 갖는 Supervised Learning의 Global-minima를 포함할 가능성이 높다. 따라서 비지도학습을 통해 local-minima를 찾으면, 지도학습에서 더 낮은 지점의 local-minima에 도달 할 가능성이 높다.
즉, random 초기값에서 시작하는 것은 dataset의 noise로 어려울 수 있지만 pretrained_weight에서 최적화를 시작하는 것은 앞선 문제를 다소 해결할 수 있고, 이는 좀 더 높은 성능을 기대할 수 있다.
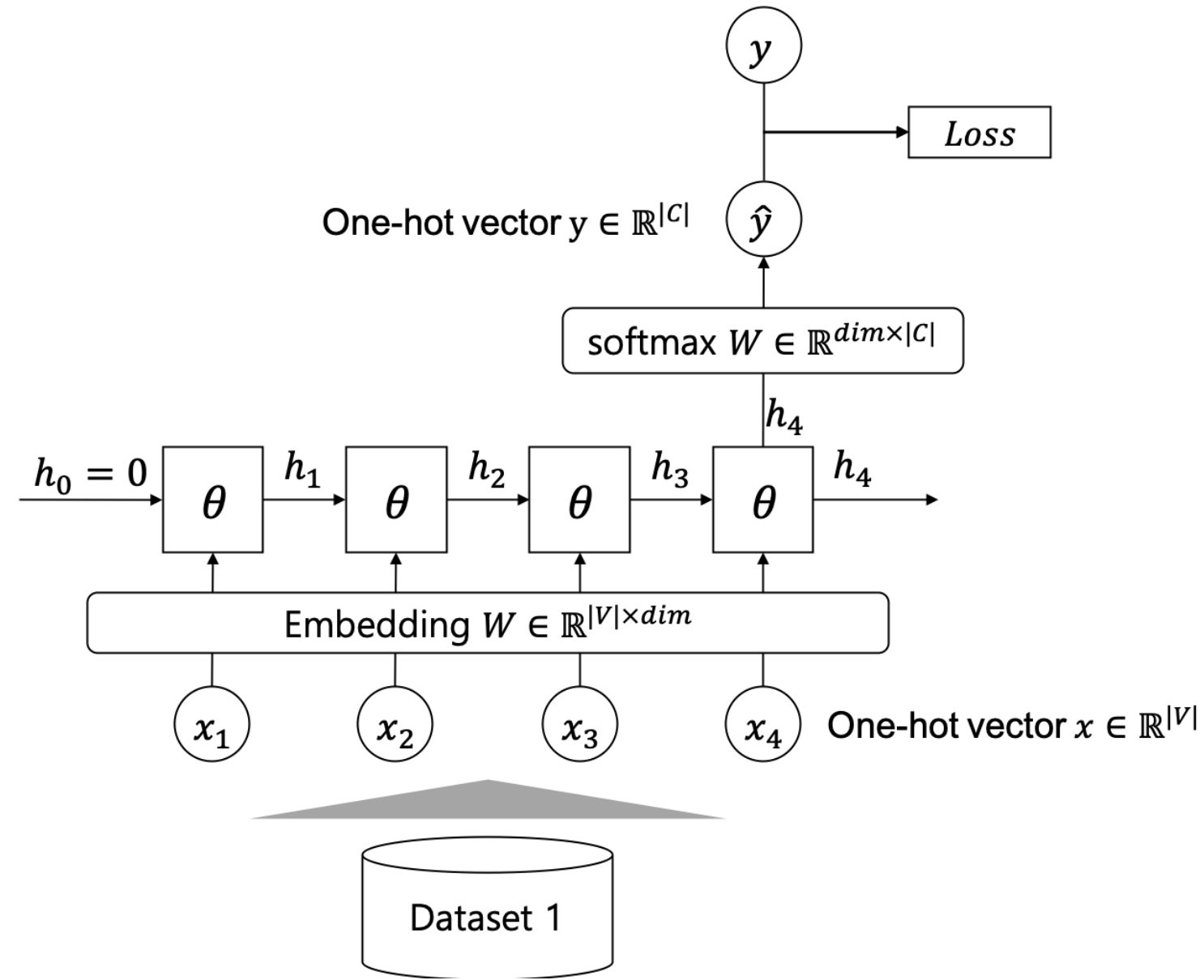
신경망 가중치 초기값으로 사용 ∙ 각 word embedding vector → pretrained word embedding vector로 치환해 사용할 수 있다. 이후 해당 embedding층의 가중치값과 기타 신경망의 random초기화 가중치값에 대해 BP와 최적화 등을 통해 학습을 수행한다.
∙이때, 각 단어에 해당하는 word embedding vector는 위의 그림에서처럼 embedding층의 가중치의 해당 행(row)을 대체하여 초기값으로 설정할 수 있다.
신경망 가중치 초기값으로 고정 이 방법은 embedding층의 가중치는 최적화대상에서 제외된다. embedding층을 제외한 신경망의 다른 가중치들만 학습하게 한다.
따라서 아래와 같이 optimizer를 설정할 수 있다.
# 기존
optimizer = optim.Adam(model.parameters())
# embedding층 제외 나머지 param 학습
optimizer = optim.Adam(model.softmax_layer.parameters() + model.rnn.parameters())
마찬가지로 0번 dataset을 통해 pretrained word embedding vector를 embedding층에 적용했으나, 이후 훈련에서 embedding층을 제외한 빨간점선안쪽부분의 신경망만 MLE를 통해 update가 된다.
신경망 가중치 초기값으로 사용 .&. Slow training 마지막으로 embedding층의 가중치를 최적화에서 제외하는 대신, 천천히 학습시키는 방법이다. 다만 이때, 또다른 Learning Rate가 hyper-parameter로 추가된다.
이전 방법들처럼 embedding층을 초기화했으나, 이번에는 2개의 다른 학습률을 사용, embedding층은 빨간 점선부분과 달리 천천히 update되게 한다.
2.2 pretrain된 word embedding vector를 사용하지 않는 이유 다만 이전에 말했듯, 이런 방식의 전이학습은 그다지 큰 효과를 거둘 수 없다.
[문맥반영못하는 기존 word embedding 알고리즘] word2vec의 Skip-Gram이나 GloVe는 성공적으로 단어를 latent space에 embedding했지만, 이 알고리즘들은 문장에 함께 출현한 단어들(co-occurence words)을 예측하는데 기반한다. 따라서 embedding 정보(feature)가 매우 한정적이다.
우리가 실제수행하려는 문제해결을 위한 목적함수와 위의 알고리즘의 목적함수는 상당히 상이할 것이고, 우리에게 필요한 정보를 반영하기는 어려울 것이다.
추가적으로 기존 word embedding 알고리즘들의 결과는 context를 고려한 단어의 의미를 embedding하기엔 지나치게 단순한데, 같은 단어라 할지라도 문장의 문맥에 따라 그 의미가 확연히 달라진다. 또한, 문장 내 단어의 위치에 따라서 쓰임새 및 의미도 달라진다. 이런 정보들이 embedding층의 상위층에서 제대로 추출 및 반영되더라도 word embedding 시 고려되어 입력으로 주어지는 것에 비해 불리하다.
[신경망 입력층의 가중치에만 적용] 위의 적용방법의 설명에서 보았듯, 대부분의 기존 적용방법들은 embedding층에 국한된다. embedding층의 가중치만 한정해 본다면 Global minima에 더 가까울지라도, 신경망 전체 가중치를 고려한다면 최적화에 유리할지는 알 수 없다.
따라서 "신경망 전체에 대해 사전훈련하는 방법"을 사용하는 편이 더 낫다.
2.3 NLP에서 pretrain의 효과 Vision에서 ImageNet을 이용해 pretrain하는 것처럼 NLP에서도 수많은 문장을 수집해 학습한 신경망으로 다른 문제에 성공적으로 적용하고 성능을 개선하는 방법이 마련되었다.
[NLP분야에서의 Transfer-Learning 분류]
NLP에서의 pretrain은 다른 분야의 pretrain보다 유리한 점을 몇가지 갖는다. ① 일반 문장들에 대해 단순 LM훈련하는 것만으로도 매우 큰 전이학습으로 인한 성능향상이 가능 ② 특히, 수집에 비용이 들어가는 parallel corpus, labeled text와 달리 일반적 문장들의 수집은 매우 쉽고 값싸다. 즉, 기존 dataset수집에 비해 일반 corpus수집은 거의 비용이 들지 않기에 매우 큰 성과를 위험부담없이 얻을 수 있다.
3. ELMo
3.1 ELMo (Embedding from Language Model) ELMo논문에서는 앞서 제기한 기존 pretrain훈련방식의 문제점을 해결하는 방법을 제시했다.
∙ 입력으로 주어진 문장을 단방향 LSTM(Uni-Directional LSTM)에 넣고, 정방향과 역방향 LM을 각각 훈련한다. 이때, LM은 AR(자기회귀)모델이다.(= 양방향 LSTM으로 훈련불가)
이때, LSTM은 여러 층으로 구성이 가능하며, 각 층이 주어진 문장 내의 token수만큼 정방향과 역방향에 대해 훈련된다. 각 time-step의 입력과 출력에 따른 내부 LSTM의 정방향 및 역방향 hidden_state
❗️embedding층과 softmax층은 정방향과 역방향에 대해 공유되며, 이전층의 각 방향별 출력값이 같은 방향의 다음 층으로 전달된다.
이때, 정방향과 역방향 LSTM은 따로 구성되지만 LSTM의 입력을 위한 embedding층과 출력을 받아 단어를 예측하는 softmax층의 경우, weight_parameter를 공유한다.
이를 통해 word_embedding_vector는 물론, LSTM의 층별 hidden_state를 time-step별로 얻을 수 있고 이들에 대한 가중합을 구해 해당 단어나 토큰에 대한 문장 내에서의 embedding representation인 ELMoktask를 구할 수 있다.
ELMoktask는 각 time-step별 L개의 LSTM_hidden state들을 가중치 sjtask에 따라 가중합을 구한다. 이때, j=0일 때, 단어의 embedding vector를 가리키며 j > 0일 때, 정방향과 역방향의 LSTM의 hidden_state인 hj,kLM ; hk,jLM가 연계되어 구성된다. 이 ELMoktask(= representation)들은 풀고자하는 문제에 따라 달라지기에 task라 표현한다.
이렇게 얻어진 ELMo표현은 실제 문제수행을 위한 신경망의 입력벡터에 연계되어 사용된다. 이때, ELMo표현을 위한 신경망가중치파라미터는 update되지 않는다.
ELMo는 이런 방법들로 전이학습을 수행함으로써 SQuAD(Stanford Question Answering Dataset)와 같은 고난도 종합독해(Reading Comprehension)문제에서 SRL(Semantic Role Labeling), NER(Named Entity Recognition)등의 NLP처리문제까지 큰 성능개선을 이룩했다.
4. BERT (Bidirectional Encoder Representations from Transformer)
ELMo에 이어 해당년도인 2018년 말에 출시된 BERT논문은 매우 뛰어나 현재도 많이 사용 및 응용이 가장 많이되는 모델이다.
하지만, BERT는 Masked LM기법으로 LM훈련을 단순히 다음 단어를 훈련하는 기존방식에서 벗어나 "입력으로 들어가는 단어 token 일부를 masking, 모델이 문맥을 통해 원래 단어를 예측해 빈칸을 채우는 형태의 문제로 바꿈"으로써 Bi-Directional Encoding을 적용할 수 있게 하였다.
[MASK] token을 임의의 단어와 치환(보통 masking시, 15% 단어만 masking.)한 후, 신경망이 기존 단어를 맞추게 학습하는데 이는 마치 Denoising Auto-Encoder와 비슷한 맥락으로 원리를 이해할 수 잇따.
다만 MLM은 학습수렴속도가 늦어지는 문제가 발생하지만, 훨씬 더 큰 성능의 개선을 이룩하기에 현재도 유용히 사용된다.
4.2 NSP (Next Sentence Prediction) 사실 질의응답과 같은 문제는 입력으로 여러개의 문장이 주어진다. 이 여러 문장사이의 관계가 매우 중요하기에 단순 LM으로는 문장간의 관계를 모델링하기 어렵다. 이때, BERT는 문장의 쌍을 입력으로 삼아 사전훈련을 수행하여 사후 fine-tuning단계에서 여러 문장이 입력으로 주어지는 문제에 효과적 대처가 가능하다.
NSP는 "2개의 문장을 주고 이 문장들이 이어진 문장인지 맞추도록 학습, 문장마다 문장끝에 [SEP]라는 token을 붙여 문장을 구분하는 방법"이다. 아래 그림과 같이 문장순서를 나타내는 정보를 추가로 embedding, 기존의 word embedding 및 position embedding의 합에 더해준다. [CLS]라는 특별 token을 추가로 도입해 현재 분류작업이 진행중임을 알리고, [SEP]라는 특별 token을 추가로 도입해 문장사이 경계를 신경망에 알려준다.
corpus에서 실제 앞뒤 두 문장을 추출해 학습하기도하고 임의의 관계없는 두 문장을 추출해 학습하기도 한다. 예를들어 아래와 같다. [CLS] the man went to [MASK] stor [SEP] he bought a gallon [MASK] milk [SEP] [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight less birds [SEP]
4.3 문장 쌍 분류문제 대표적인 NLP Metric인 GLUE(General Langauge Understanding)는 다양한 자연어 이해문제에 대한 성능평가를 제공한다. 예를들어, QNLI test(Question Natural Language Inference)는 SQuAD에서 추출되어 변형된 문제들로 입력으로 주어진 질문과 이어지는 문장이 올바른 Q-A관계인지 맞추는 이진분류문제이다.
이런 분류문제에 적용하기 위해 transformer encoder의 가장 첫 time-step 입력은 [CLS]라는 특별 token을 입력으로 받는다. 해당 time-step의 출력벡터에 softmax층을 추가해 Fine-tuning을 함으로써 주어진 문제에 대한 분류신경망을 얻을 수 있다.
[CLS]에 해당하는 transformer encoder의 출력벡터를 C ∈ ℝH라 하자. (이때, H는 vector의 차원이다.) 이때, softmax층의 가중치파라미터 W ∈ ℝK×H를 추가한다. (이때, K는 후보클래스의 개수이다.) 이제, 각 클래스에 속할 확률분포 P ∈ ℝK를 구해보자.
[특징기반 전이학습방법인 ELMo와 가장 큰 차이점] 해당 문제에 대한 train dataset에 MLE를 수행하면서, 새롭게 추가된 W뿐만아니라 기존 BERT의 가중치까지 한꺼번에 학습시키는 것.
4.4 단일문장 분류문제 Text Classification이 가장 대표적인 이 유형에 속하는 문제이다. 마찬가지로 [CLS]토큰의 transformer출력에 대해 softmax층을 추가해 Fine-tuning으로 신경망을 훈련한다. 인터넷 등으로 수집한 corpus에 대해 LM을 훈련한 결과를 통해 task에 대한 dataset만으로 얻어낼 수 있는 성능을 훨씬 상회하는 성능을 발휘할 수 있게 되었다. 것처럼 분절이 완료된 파일을 데이터로 사용한다. 이후
4.5 질의응답 문제 BERT는 마찬가지로 종합독해문제에도 매우 강력한 성능을 발휘했다. SQuAD에서도 훌륭한 결과를 얻었고, 한국어 dataset인 KorSQuAD에서도 매우 뛰어난 성능을 거뒀다.
SQuAD와 같은 문제는 질문과 문장이 주어졌을 때, 문장 내에서 질문에 해당하는 답을 예측하도록 학습한다. 따라서 정답단어나 구절이 위치한 time-step의 시작과 끝을 출력학 반환한다. 즉, 여럭 time-step의 입력을 받아 여러 time-step의 출력값을 내도록 한다.
SQuAD문제는 BERT를 이용한 주류가 대부분을 차지하였으며(KorSQuAD), 이미 해당 task에서 사람의 능력치를 뛰어넘었다.
4.6 단일문장 Tagging문제 이외에도 BERT는 NER, SRL같은 문장 내 정보 tagging문제 등에도 적용되어 뛰어난 성능을 발휘한다. 하나의 고정된 architecture에서 단순히 수많은 corpus를 훈련한 결과로 NLP전반에 걸쳐 뛰어난 성능을 거두었는데, 이 경우, 입력으로 들어온 각 단어나 토큰에 대한 tagging정보 등을 출력으로 반환하도록 추가적 훈련을 진행한다.
5. GPT-2
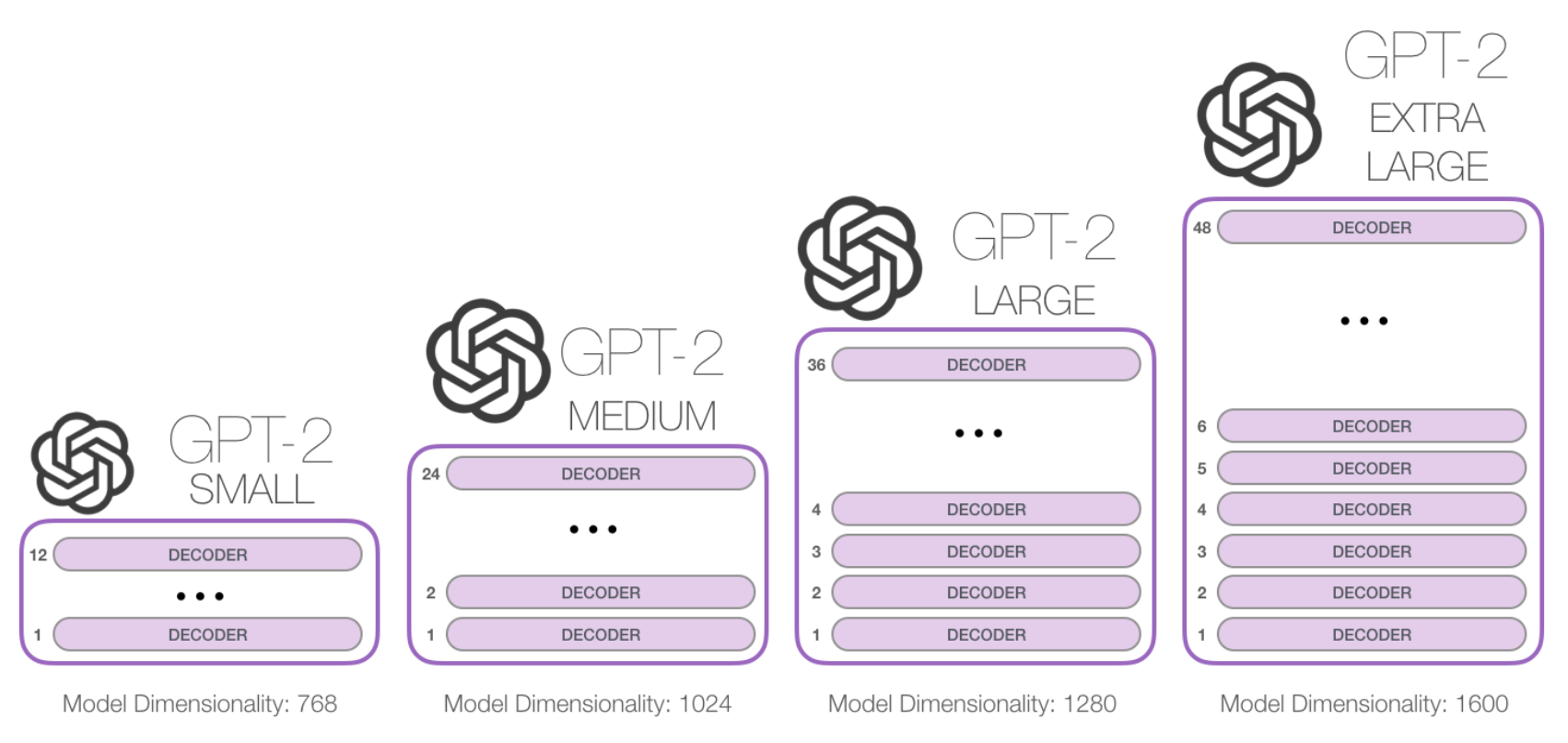
5.1 Architecture GPT-2논문에서도 BERT와 같이 Transformer Decoder구조를 활용, LM을 비지도학습으로 사전학습 후 추가적인 지도학습으로 성능향상을 얻는다. GPT-2이전, GPT-1논문이 발표되었었는데, 사실 GPT-1과의 차이점은 Decoder를 더 크게 사용하고, 몇가지 수정사항만 제외하면 거의 없다. GPT-2는 기존의 Transformer에서 활용된 MHA블록을 굉장히 넓고 깊게 쌓아 parameter개수를 크게 늘려 수용력을 극대화 했는데, 이는 역전파의 전달을 용이하게 하는 skip-connection과 같은 방법으로 인해 가능하다.
다만, 논문에 따르면 이렇게 큰 모델구조를 활용했음에도 여전히 LM-비지도 사전학습에 사용된 dataset에 대해 underfitting이 될 만큼 큰 dataset을 사용했음을 알 수 있다.
5.2 pretrained Dataset 예시 ∙ 기존의 다양하지 않은 도메인들 ex) 뉴스기사, Wikipedia, 소설 등의 corpus
∙ WebText: 직접 crawling을 통해 최대한 많은 corpus를 모은 dataset
5.3 전처리 및 LM-Unsupervised pretraining 이 논문에서는 수집된 웹페이지로부터 텍스트들을 추출하기 위해 'Dragnet'과 'Newspaper'라는 라이브러리를 활용했다. 결과적으로 총 800만개의 문서로 구성된 40GB에 이르는 dataset을 수집하는 결과를 얻었고 이를 활용해 LM을 pretrain시켜 최고성능 LM을 얻을 수 있었다.
이후 subword과정에서 BPE만을 활용하며, 이때 BPE train과정에서 merge가 같은 wordset 내에서만 일어나게 제약을 둠으로써 BPE 분절의 성능을 단순한 방법으로 극대화 하였다. 이때, subword의 효율을 높이기 위해 같은 그룹의 character끼리만 merge과정을 수행한다.
ex) "입니다."와 같은 마침표(.)가 알파벳이나 한글과 붙어 나타난다면, 마침표와 앞서 나타난 문자들은 다른 그룹에 속하기 때문에 빈도가 아무리 높더라도 BPE 훈련 및 적용과정에서 결합이 수행되지 않는다. (= 여전히 떨어져 있는 상태가 될 것)
따라서 BPE를 통해 GPT-2는 추가적인 큰 노력없이 준수한 성능의 전처리 결과를 얻을 수 있었다.
5.4 실험 결과 GPT-2는 매우 방대한 양의 crawling data를 구축하고, transformer모델의 구조를 매우 깊고 넓게 가져갔다. 이를 통해 GPT-2는 매우 그럴싸한 느낌이 들 정도로 수준높은 LM임을 자랑한다.
위의 표는 GPT-2의 각 dataset에 대한 PPL(perplexity)성능으로 표에서 알 수 있듯, 대부분의 datsaset에서 S.O.T.A를 보여줬다. 특히나 LAMBADA datatset의 경우, parameter수가 늘어날수록 매우 큰 폭의 PPL의 감소를 확인할 수 있다.
Conclusion GPT-2는 매우 방대한 양의 corpus를 수집해 training과정에 사용한 것이 큰 특징이다. 덕분에 매우 깊고 넓은 모델구조를 가지며 훌륭한 LM을 갖는다. 즉, 비지도학습에서 좀 더 Global-minima에 접근가능하다. → 추가적 지도학습으로 다른 문제들에서도 큰 성능향상을 가질 수 있게 되었다.
마치며...
이번시간에는 전이학습(transfer learning)을 활용해 NLP성능을 끌어올리는 방법을 알아보았다. 기존의 word2vec과 같은 사전훈련법과 달리 이번에 소개한 ∙ELMo처럼 "문맥을 반영한 word embedding vector"를 구하거나 ∙BERT처럼 "신경망 전체에 대해 사전학습된 가중치"를 제공한다. 특히 기존 Vision분야에서는 이미 ImageNet을 pretrain_weight_parameter로 두고 다른 dataset의 training에 사용을 진행해 왔었다. 이 효과를 NLP에서도 얻을 수 있게 되었기에 BERT는 매우 효과적이다. (by MLM. &. NSP) BERT는 손쉽게 수집가능한 일반적인 문장들을 바탕으로 양방향 언어모델을 학습한 후, 이를 다른 문제해결에 사용한다.
기계번역과 같이 parallel corpus가 필요하거나 text classification과 같이 labeling된 corpus가 필요한 경우 제한적으로 dataset을 수집해야한다.
하지만 전이학습을 통해 훨씬 더 많은 양의 corpus로부터 문장의 특징을 추출하는 방법을 신경망이 배울 수 있게 되는 것이다. BERT의 활용은 질의응답문제에 대해 사람보다 뛰어난 해결능력을 갖는 신경망을 손쉽게 얻을 수 있었다.