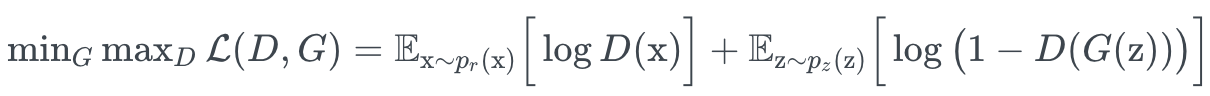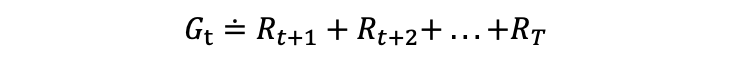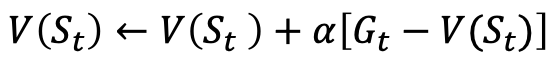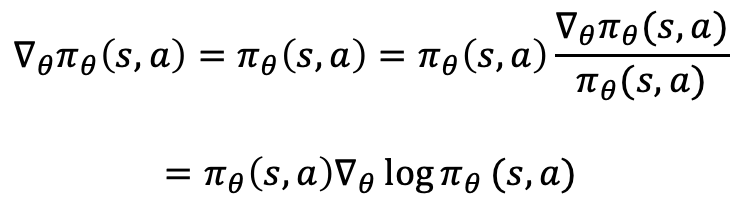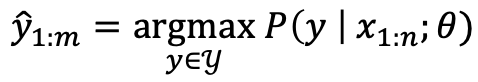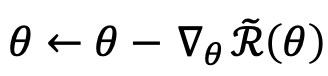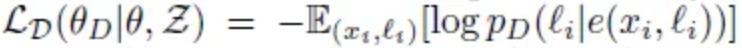Reinforcement Learning의 경우, 매우 방대한 분야이기에 그 방대한 영역의 일부분인 Policy Gradient를 활용해 자연어생성(NLG; Natural Language Generation)의 성능을 끌어올리는 방법을 다뤄볼 것이다.
먼저, Reinforcement Learning이 무엇인지, NLG에 왜 필요한지 차근차근 다뤄볼 것이다.
1. Preview
1.1 GAN (Generative Adversarial Network) 2016년부터 주목받으며 2017년 가장 큰 화제가 되었던 분야이고, 현재 Stable Diffusion 등으로 인해 Vision에서 가장 큰 화제의 분야는 단연코 생성적대신경망(GAN)이다. 이는 변분오토인코더(VAE)와 함께 생성모델학습을 대표하는 방법 중 하나이다. 이렇게 생성된 이미지는 실생활에 중요하지만 trainset을 얻기 힘든 문제들의 해결에 큰 도움을 줄 것이라 기대되고 있다.
위의 그림처럼 GAN은 생성자(Generator)G와 판별자(Discriminator) D라는 2개의 모델을 각기다른 목표를 갖고 "동시에 훈련"시킨다. 두 모델이 균형을 이루면 min/max 게임을 펼치게 되면 최종적으로 G는 훌륭한 이미지를 생성할 수 있게 된다.
1.2GAN을 자연어생성에 적용 한번 GAN을 NLG에 적용해보자. 예를들어, CE를 사용해 바로 학습하기보단 - 실제 corpus에서 나온 문장인지 - seq2seq에서 나온 문장인지 위의 두 경우에 대한 판별자 D를 두어 seq2seq에서 나온 문장이 진짜 문장과 같아지도록 훈련하는 등을 예시로 들 수 있다.
다만, 아쉽게도 이 좋아보이는 아이디어는 바로 적용할 수 없는데,
seq2seq의 결과는 이산확률분포이기 때문이다. 따라서 여기서 sampling이나 argmax로 얻어지는 결과물은 discrete한 값이기에 one-hot벡터로 표현되어야 할 것이다. 하지만 이 과정은 확률적인 과정(stochastic process)으로 기울기를 역전파할 수 없거나 미분 결과값이 0이나 불연속적인 경우가 되기에 D가 맞춘 여부를 역전파를 통해 seq2seq G로 전달될 수 없고, 결과적으로 학습이 불가능하다.
1.3 GAN과 자연어생성 1.1과 1.2에서 말했듯, GAN은 Vision에서는 대성공을 이뤘지만 NLG에서는 적용이 어려운데, 이는 자연어 그 자체의 특징때문이다. ∙ 이미지는 어떤 "연속적"인 값들로 채워진 행렬 ∙ 언어는 불연속적인 값들의 순차적 배열이기에 우린 LM을 통해 latent space에 연속적 변수로 그 값들을 치환해 다룬다. 결국, 외부적으로 언어를 표현하려면 이산확률분포와 변수로 나타내야하고, 분포가 아닌 어떤 sample로 표현하려면 이산확률분포에서 sampling하는 과정이 필요하다.
이런 이유로 D의 loss를 G에 전달할 수 없고, 따라서 적대적신경망방법을 NLG에 적용할 수 없다는 인식이 주를 이루게 되었다. But!!강화학습을 통해 적대적 학습방식을 우회적으로 사용할 수 있게 되었다.
1.4 강화학습 사용이유 어떤 task해결을 위해 CE를 쓸 수 있는 classification이나 continuous변수를 다루는 MSE등으로는 정의할 수 없는 복잡한 목적함수가 많기 때문이다.
즉, 우리는 CE나 MSE로 문제를 해결했지만, 이는 문제를 단순화해 접근했다는 것을 알 수 있다. 이런 문제들을 강화학습을 통해 해결하고, 성능을 극대화할 수 있다.
이를 위해 잘 설계된 보상(reward)을 사용해 더 복잡하고 정교한 문제를 해결할 수 있다.
2. Reinforcement Learning 기초
Reinforcement Learning은 이미 오래전 Machine Learning의 한 종류로 나왔던 방대하고도 유서깊은 학문이기에 이번에 하나의 글로는 다루기 무리가 있다.
따라서 이번시간에 다룰, Policy Gradient에 대한 이해를 위해 필요한 정도만 이해하고 넘어가보려 한다.
Q: 강화학습이란?? A: 어떤 객체가 주어진 환경에서, 상황에 따라 어떻게 행동해야할 지 학습하는 방법 강화학습 동작과정
처음 상태인 St(t=0)을 받고, ∙Agent는 자신의 policy에 따라 action At를 선택한다. ∙Environment는 Agent로부터 선택된 At를 받아 보상 Rt+1과 새롭게 바뀐 상태St+1을 반환한다.
이 과정을 특정조건이 만족될 때까지 반복하며, 환경은 이 시퀀스를 종료한다. 이를 하나의 episode라 한다.
목표: 반복되는 episode에서 agent가 RL을 통해 적절한 행동(보상이 최대가 되도록)을 하도록 훈련시키는 것
2.2 MDP (Markov Decision Process) 여기에 더해 Markov결정과정(MDP)라는 개념을 도입한다. 우린 온 세상의 현재 T=t라는 순간을 하나의 상태(state)로 정의할 수 있다.
가정) 현재상태(present state)가 주어졌을 때, 미래(T>t)는 과거(T<t)로부터 "독립적". 이 가정 하에, 온 세상은 Markov과정 위에서 동작한다 할 수 있다. 이때, 현재상황에서 미래상황으로 바뀔 확률을 P(S' | S)로 표현가능하다.
여기에 MDP는 결정을 내리는 과정(= 행동을 선택하는 과정)이 추가된 것이다. 즉, 현재상황에서 어떤행동을 선택 시, 미래상황으로 바뀔 확률로 P(S' | S, A)이다. 쉽게 설명하자면, 아래 가위바위보게임을 예시로 들 수 있다.
예를들어 사람마다 가위바위보를 내는 패턴이 다르기에 가위바위보 상대방에 따라 전략이 바뀌어야 하므로 ∙ 상대방이 첫 상태 S0를 결정한다. ∙ Agent는 S0에 따라 행동 A0를 선택한다. ∙ 상대방은 상대방의 정책에 따라 가위/바위/보 중 하나를 낸다. ∙ 승패가 결정, 환경으로부터 방금 선택한 행동에 대한 보상 R1을 받는다. ∙ update된 상태 S1을 얻는다.
2.3 Reward 앞서 Agent가 어떤 행동을 했을 때, 환경으로부터 "보상"을 받는다. 이때, 우린 Gt를 어떤 시점으로부터 받는 보상의 누적합이라 정의하자. 따라서 Gt는 아래와 같이 정의된다. 이때 감소율(discount factor) γ(0~1값)를 도입해 수식을 조금 변형할 수 있다. γ의 도입으로 먼 미래의 보상보다 가까운 미래의 보상을 더 중시해 다룰 수 있게 된다.
2.4 Policy Agent는 주어진 상태에서 앞으로 받을 보상의 누적합을 최대로 하도록 행동해야한다. 즉, 눈앞의 작은 작은 손해보다먼미래까지 포함한 보상의 총합이 최대가 되는것이 중요하다. (😂 마치 우리가 시험기간에 놀지못하고 공부하는 것처럼...?)
정책(policy)은 Agent가 상황에 따라 어떻게 행동을 해야할 지, "확률적으로 나타낸 기준"이다. 즉, 같은 상황이 주어졌을 때, 어떤 행동을 선택할지에 대한 확률함수이기에 따라서 우리가 행동하는 과정은 확률적인 프로세스라 볼 수 있다. 이때, 함수를 통해 주어진 행동을 취할 확률값을 아래 함수를 통해 구할 수 있다.
2.5 Value Function (가치함수) 가치함수란 주어진 policy 𝛑 내에 특정 상태 s에서부터 앞으로 얻을 수 있는 보상의 누적총합의 기댓값을 의미한다. 아래 수식과 같이 나타낼 수 있는데, 앞으로 얻을 수 있는 보상의 총합의 기댓값은 기대누적보상(Expected Cumulative Reward)라고도 한다.
행동가치함수 (Q-function ; Q 함수)
행동가치함수(activation-value function ; Q-function)는 주어진 policy 𝛑 아래 상황 s에서 action a를 선택했을 때, 앞으로 얻을 수 있는 보상의 누적합의 기댓값(기대누적보상)을 표현한다.
가치함수가 어떤 s에서 어떤 a를 선택할지와 관계없이 얻을 수 있는 누적보상의 기댓값이라 한다면 Q함수는 어떤 a를 선택하는가에 대한 개념이 추가된 것이다. 즉, 상태와 행동에 따른 기대누적보상을 나타내는 Q함수의 식은 아래와 같다.
2.6 Bellman 방정식 가치함수와 행동가치함수의 정의에 따라 이상적인 가치함수와 이상적인 Q함수를 정의해보고자 한다면...? → Bellman Equation(벨만 방정식)을 다음과 같이 나타낼 수 있다. 좌) Back-Tracking / 우) Dynamic Programming. //. Back-Tracking의 경우, 모든 경우의 수를 전부 탐색해야 한다. DP: 문제를 겹치는 하위 문제(sub-problems)로 분해하고 최적 부분 구조(optimal substructure)를 따르는 방법으로 문제를 해결하는 기술로 큰 문제를 해결하는 것은 작은 하위 문제를 해결하는 것으로 나누어질 수 있습니다. 이 작은 하위 문제들을 해결한 후에는 그 결과를 조합하여 원래 문제를 해결합니다. 중요한 점은 동일한 하위 문제가 여러 번 계산되는 대신, 한 번 계산된 결과를 저장하고 재사용하여 계산 비용을 줄이는 것입니다. 이것이 DP의 핵심 아이디어이며, 겹치는 하위 문제가 있다면 DP를 효과적으로 활용할 수 있다.
Bellman방정식은 동적프로그래밍(DP; Dynamic Programming)알고리즘 문제로 접근가능하다. 즉, 단순히 최단경로를 찾는 문제와 비슷한데, 아래 그림처럼 모든 경우에 대해 탐색을 수행하는 Back-Tracking보다 훨씬 효율적이고 빠르게 문제풀이에 접근할 수 있다.
2.7 Monte Carlo Method 하지만 그렇게 쉽게 문제가 풀리면 강화학습이 필요하진 않았을 것이다. Prob) 대부분의 경우, 위의 2.6의 수식에서 가장 중요한 P(s', r | s, a)부분을 모른다는 점이다. 즉, 어떤 상태→어떤행동→어떤확률로 다른상태 s'과 보상 r'을 받게되는지, "직접 해봐야" 안다는 점이다. ∴ DP가 적용될 수 없는 경우가 대부분이다. 따라서 RL처럼 simulation등의 경험을 통해 Agent를 학습해야한다. 이런 이유로 Monte Carlo Method처럼 sampling을 통해 Bellman의 Expectation Equation을 해결할 수 있다. Prob) 긴 episode에 대해 sampling으로 학습하는 경우이다. 실제 episode가 끝나야 Gt를 구할 수 있기에 episode의 끝까지 기다려야 한다. 다만, 그간 익히 보아온 AlphaGo처럼 굉장히 긴 episode의 경우, 매우 많은 시간과 긴 시간이 필요하게 된다.
2.8 TD 학습 (Temporal Difference Learning) 이때, 시간차학습(TD)방법이 유용하다. TD학습법은 다음수식처럼 episode보상의 누적합 없이도 바로 가치함수를 update할 수 있다.
Q-Learning 만약 올바른 Q함수를 알고있다면, 어떤상황이더라도 항상 기대누적보상을 최대화하는 매우 좋은 선택이 가능하다. 이때, Q함수를 잘 학습하는 것을 Q-Learning이라 한다.
아래수식처럼 target과 현재가치함수(current)의 차이를 줄이면 올바른 Q함수를 학습할 것이다.
DQN (Deep Q-Learning) Q함수를 학습할 때, state공간의 크기와 action공간의 크기가 너무 커 상황과 행동이 희소할 경우, 문제가 생긴다. 훈련과정에서 희소성으로 인해 잘 볼 수 없기 때문이다. 이처럼 상황과 행동이 불연속적인 별개의 값이더라도, Q함수를 근사하면 문제가 발생할 수 있다.
DeepMind는 신경망을 사용해 근사한 Q-Learning을 통해 Atari게임을 훌륭히 플레이하는 강화학습방법을 제시했는데, 이를 DQN(Deep Q-Learning)이라 한다. 신경망을 활용한 Q-Learning 개요
아래 수식처럼 Q함수 부분을 신경망으로 근사해 희소성 문제를 해결했고, 심지어 Atari게임을 사람보다 더 잘 플레이하는 Agent를 학습하기도 했다.
3. Policy based Reinforcement Learning
3.1 Policy Gradient Policy Gradient는 Policy based Reinforcement Learning방식에 속한다. cf) DQN은 가치기반(Value based Reinforcement Learning)방식에 속한다.-ex) DeepMind가 사용한 AlphaGo.
정책기반과 가치기반 강화학습, 두 방식의 차이는 다음과 같다. ∙ 가치기반학습: ANN을 사용해 어떤 행동을 선택 시, 얻을 수 있는 보상을 예측하도록 훈련 ∙ 정책기반학습: ANN의 행동에 대한 보상을 역전파알고리즘을 통해 전달해 학습 ∴ DQN의 경우, 행동의 선택이 확률적(stochastic)으로 나오지 않지만 Policy Gradient는 행동 선택 시, 확률적인 과정을 거친다. Policy Gradient에 대한 수식은 아래와 같다. 이 수식에서 앞의 𝜋는 policy를 의미한다. 즉, 신경망 가중치 θ는 현재상태 s가 주어졌을때, 어떤행동 a를 선택해야하는지에 관한 확률을 반환한다. 우리의 목표는 최초상태(initial state)에서의 기대누적보상을 최대로 하는 정책 θ를 찾는것이고 최소화해야하는 손실과 달리 보상은 최대화해야하므로 기존의 경사하강법대신, 경사상승법(Gradient Ascent)를 사용한다. 이런 경사상승법에 따라 ∇θJ(θ)를 구해 θ를 update해야한다. 이때, d(s)는 Markov Chain의 정적분포(stationary distribution)로써 시작점에 상관없이 전체경로에서 s에 머무르는 시간비율을 의미한다. 이때, 로그미분의 성질을 이용해 아래 수식처럼 ∇θJ(θ)를 구할 수 있다. 이 수식을 해석하자면 다음과 같다. ∙ 매 time-step별 상황 s가 주어질 때, a를 선택할 로그확률의 기울기와 그에따른 보상을 곱한 값의 기댓값이 된다. Policy Gradient Theorem에 따르면 여기서 해당 time-step에 대한 즉각적 보상 r대신, episode 종료까지의 기대누적보상을 사용할 수 있다. 즉, Q함수를 사용할 수 있다는 것인데, 이때 Policy Gradient의 진가가 드러난다.
우린 Policy Gradient 신경망에 대해 미분계산이 필요하지만, "Q함수에 대해서는 미분할 필요가 없다!!" 즉, 미분가능여부를 떠나, 임의의 어떤 함수라도 보상함수로 사용할 수 있는것이다!! 이렇게 어떤 함수든 보상함수로 사용할 수 있게되면서, 기존 Cross-Entropy나 MSE같은 손실함수로 fitting하는 대신, 좀 더 실무에 부합하는 함수(ex. 번역의 경우, BLEU)를 사용해 θ를 훈련시킬 수 있게되었다.
추가적으로 위의 수식에서 기댓값 수식을 Monte Carlo Sampling으로 대체하면 아래처럼 신경망 파라미터 θ를 update할 수 있다.
이 수식을 더 풀어서 설명해보자. ∙ log𝜋θ(at | st) : st가 주어졌을 때, 정책파라미터 θ상의 확률분포에서 sampling되어 선택된 행동이 at일 확률값이다. 해당확률값을 θ에 대해 미분한 값이 ∇θlog𝜋θ(at | st)이다. 따라서 해당 기울기를 통한 경사상승법은 log𝜋θ(at | st)를 최대화함을 의미한다. ∙ 즉, at의 확률을 높이도록 하여 앞으로 동일상태에서 해당행동이 더 자주 선택되게 한다. Gradient ∇θlog𝜋θ(at | st)에 보상을 곱해주었기에 만약 sampling된 해당 행동들이 큰 보상을 받았다면, 학습률 γ에 추가적인 곱셈을 통해 더 큰 step으로 경사상승을 수행할 수 있다.
하지만 음의 보상값을 받게된다면, 경사의 반대방향으로 step을 갖게 값이 곱해질 것이므로 경사하강법을 수행하는 것과 같은 효과가 발생할 것이다. 따라서 해당 sampling된 a들이 앞으로는 잘 나오지 않게 신경망 파라미터 θ가 update될 것이다. 따라서 실제 보상을 최대화하는 행동의 확률을 최대로하는 파라미터 θ를 찾도록 할것이다.
다만, 기존의 경사도는 방향과 크기를 나타낼 수 있었지만, Policy Gradient는 기존 경사도의 방향에 스칼라 크기값을 곱해주므로 실제 보상을 최대화하는 직접적인 방향을 지정할 수 없기에 사실상 훈련이 어렵고 비효율적이라는 단점이 존재한다.
3.2 MLE v.s Policy Gradient 다음 예시로 최대가능도추정(MLE)과의 비교를 통해 Policy Gradient를 더 이해해보자.
∙ n개의 sequence로 이뤄진 data를 입력받아 ∙ m개의 sequence로 이뤄진 data를 출력하는 함수를 근사시키는 것이 목표
그렇다면 sequence x1:n과 y1:m은 B라는 dataset에 존재한다. 목표) 실제함수 f: x→y를 근사하는 신경망 parameter θ를 찾는것이므로 이제 해당 함수를 근사하기 위해 parameter θ를 학습해야한다. θ는 아래와 같이 MLE로 얻을 수 있다. Dataset B의 관계를 잘 설명하는 θ를 얻기위해, 목적함수를 아래와 같이 정의한다. 아래 수식은 Cross-Entropy 를 목적함수로 정의한 것이다. 목표) 손실함수의 값을 최소화 하는 것. 앞에서 정의한 목적함수를 최소화 해야하므로 Optimizer를 통해 근사할 수 있다. (아래 수식은 Optimizer로 Gradient Descent를 사용하였다.)
해당 수식에서 학습률 γ를 통해 update의 크기를 조절한다.
다음 수식은 Policy Gradient에 기반해 누적기대보상을 최대로하는 경사상승법 수식이다.
이 수식에서도 이전 MLE의 경사하강법 수식처럼 γ의 추가로 Q𝛑θ(st, at)가 기울기 앞에 붙어 학습률역할을 하는 것을 볼 수 있다. 따라서 보상의 크기에 따라 해당 행동을 더욱 강화하거나 반대 방향으로 부정할 수 있게 되는 것이다. 즉, 결과에 따라 동적으로 학습률을 알맞게 조절해준다고 이해할 수 있다.
Sampling 확률을 최대화하는 방향으로 경사도를 구하는 Policy Gradient
3.3 Baseline을 고려한 Reinforce 알고리즘 앞에서 설명한 Policy Gradient를 수행할 때, 보상이 양수인 경우 어떻게 동작할까?
ex) 시험이 0~100점사이 분포할 때, 정규분포에 의해 대부분 평균근처에 점수가 분포할 것이다. 따라서 대부분의 학생들은 양의 보상을 받는다. 그렇게되면, 앞의 기존 policy gradient는 항상 양의 보상을 받아 Agent(학생)에게 해당 policy를 더욱 독려할 것이다. But!평균점수가 50점일 때, 10점은 상대적으로 매우 나쁜점수이므로 기존 정책의 반대방향으로 학습하게된다.
즉, 주어진 상황에 마땅한 보상이 있기에 우린 이를 바탕으로 현재 policy가 얼마나 훌륭한지 평가를 할 수 있다. 이를 아래 수식처럼 policy gradient수식으로 표현할 수 있다.
이처럼 Reinforce 알고리즘은 baseline을 고려해 좀 더 안정적 강화학습수행이 가능하다.
4. Natural Language Generation에 Reinforcement Learning 적용
강화학습은 마르코프 결정 과정(MDP) 상에서 정의되고 동작한다.
여러 Decision Action → 여러 상황을 이동(transition)하며 episode가 구성 → 선택된 행동과 상태에 따라 보상이 주어진다.
이것이 누적되고 에피소드가 종료되면 누적보상을 얻을 수 있습니다.
이런 과정은 NLP에서 text classification보다는 sequential data를 예측해야 하는 자연어 생성(NLG)에 적용된다.
∙ 이제까지 생성된 word sequence = current state(현재상황)
∙ 이제까지 생성된 단어를 기반 → 새롭게 선택하는 단어가 행동이 될 것
∴ 하나의 문장을 생성하는 과정(= (BOS)~(EOS)까지 선택하는 과정)이 하나의 Episode가 된다.
∙episode를 반복해 문장생성경험을 축적 → 실제 정답과의 비교 → 기대누적보상을 최대화하도록 θ를 훈련
NMT에 RL을 적용한다면...?
NMT에 RL을 구체적으로 대입해보자.
∙ 현재 상태 = 주어진 src문장과 이전까지 생성(번역)된 단어들의 시퀀스
∙행동을 선택하는 것 = 현재 상태에 기반하여 새로운 단어를 선택하는 것.
∙현재 time-step의 행동을 선택 시 → 다음 time-step의 상태는 소스 문장과 이전까지 생성된 단어들의 시퀀스에 현재 time-step에 선택된 단어가 추가되어 정해진다.
❗️중요한 점
행동을 선택한 후, 환경으로부터 즉각적인 보상을 받지는 않으며,
모든 단어의 선택이 끝나고 최종적으로 EOS를 선택해 디코딩이 종료되어 에피소드가 끝나면,
비로소 BLEU 점수를 계산하여 누적 보상을 받을 수 있다는 것
즉, 종료 시 받는 보상값 = 에피소드 누적보상(cumulative reward) 값
강화학습을 통해 모델을 훈련 시, 훈련의 도입부부터 강화학습만 적용하기에는 그 훈련방식이 비효율적이고 어려움이 크므로,
보통 기존의 MLE를 통해 어느 정도 학습이 된 신경망θ에 강화학습을 적용한다.
즉, 강화학습은 탐험(exploration)을 통해 더 나은 정책의 가능성을 찾아내고 착취(exploitation)를 통해 그 정책을 발전시켜 나갑니다.
4.1 NLG에서 강화학습의 특징 앞에서 RL의 Policy based Learning인 Policy Gradient방식에 대해 간단히 알아봤다. Policy Gradient의 경우, 위에서 설명한 내용 이외에도 발전된 방법들이 많다. ex) Actor Critic, A3C, ... ∙ Actor Critic: 정책망 θ이외에도 가중치망 W를 따로 두어 episode종료까지 기다리지 않고 TD학습법으로 학습한다. ∙ A3C(Asunchronous Advantage Actor Critic): Actor Critic에서 더욱 발전 및 기존 단점을 보완
다만, NLP의 RL은 이런 다양한 방법들을 굳이 사용할 필요없이 간단한 Reinforce알고리즘을 사용해도 큰 문제가 없는데, 이는 NLP분야의 특징 덕분으로 강화학습을 자연어처리에 적용 시, 아래와 같은 특징이 존재한다.
1. 선택 가능한 매우 많은 행동(action) at가 존재 ∙ 보통 다음 단어를 선택하는 것 = 행동을 선택하는 것 ∙ 선택 가능한 행동의 집합의 크기 = 어휘 사전의 크기 ∴ 그 집합의 크기는 보통 몇 만 개가 되기 마련. 2. 매우 많은 상태 (state)가 존재 단어를 선택하는 것이 행동이었다면, ∙ 이제까지 선택된 단어들의 시퀀스 = 상태 ∙ 여러 time-step을 거쳐 수많은 행동(단어)이 선택되었다면 가능한 상태의 경우의 수는 매우 커질 것. 3.따라서 매우 많은 행동을 선택하고, 매우 많은 상태를 훈련 과정에서 모두 겪는 것은 거의 불가능하다고 볼 수 있다. ∙ 결국 추론 과정에서 unseen sample을 만나는 것은 매우 당연할 것이다. ∙ 이런 희소성 문제는 큰 골칫거리가 될 수 있지만 DNN으로 이 문제를 해결 할 수 있다. 4.강화학습을 자연어 처리에 적용할 때 쉬운 점도 있다. ∙ 대부분 하나의 문장 생성 = 하나의 에피소드 (이때, 문장의 길이는 보통 100 단어 미만) → 다른 분야의 강화학습보다 훨씬 쉽다는 이점을 갖는다.
ex) DeepMind의 AlphaGo, Starcraft의 경우, 하나의 에피소드가 끝나기까지 매우 긴 시간이 든다. → 에피소드 내에서 선택된 행동들이 정책을 업데이트하려면 매우 긴 에피소드가 끝나기를 기다려야 한다. → 뿐만 아니라, 10분 전에 선택했던 행동이 해당 게임의 승패에 얼마나 큰 영향을 미쳤는지 알아내기란 매우 어려운 일이 될 것이다. ❗️이때 자연어 생성 분야가 다른 분야에 비해 에피소드가 짧다는 것은 매우 큰 이점으로 작용하여 정책망을 훨씬 더 쉽게 훈련 시킬 수 있다. 5.대신, 문장 단위의 에피소드를 가지는 강화학습에서는 보통 에피소드 중간에 보상을 얻기 어렵다. ex) 번역의 경우, 각 time-step마다 단어를 선택할 때 즉각적인 보상을 얻지 못하고, 번역이 모두 끝난 이후 완성된 문장과 정답 문장을 비교하여 BLEU 점수를 누적 보상으로 사용한다. 마찬가지로 에피소드가 매우 길다면 이것은 매우 큰 문제가 되었겠지만, 다행히도 문장 단위의 에피소드에서는 큰 문제가 되지 않습니다
4.2 RL 적용의 장점
Teacher Forcing을 이용한 문제해결 seq2seq같은 AR속성의 모델훈련 시, teacher forcing 방법을 사용한다. 이 방법은 train과 inference방식의 차이가 발생, 실제 추론방식과 다르게 문제를 훈련해야한다.
❗️하지만, RL을 통해 실제 추론형태와 같이 sampling으로 모델을 학습 → "train과 inference"의 차이가 없어졌다.
더 정확한 목적함수의 사용 BLEU는 PPL에 비해 더 나은 번역품질을 반영한다. [Gain_NLP_07] 다만, 이런 metric들은 미분을 통해 훈현하기 불가능한 경우가 대부분이어서 신경망 훈련에 사용이 어렵다.
❗️하지만, RL의 Policy Gradient를 응용해 보상함수에 대해 미분을 계산할 필요가 없어지면서 정확한 Metric 사용이 가능했다.
5. RL을 활용한 Supervised Learning
BLEU를 훈련과정의 목적함수로 사용한다면 더 좋은 결과를 얻을 수 있을텐데...
마찬가지로 다른 NLG문제에 대해서도 비슷한 접근을 할 수 있으면 좋을텐데...
5.1 MRT (Minimum Risk Training) 위의 바람에서 출발하여 위험최소화 훈련[MRT; Minimum Risk Training]논문이 제안되었다. 당시 저자는 Policy Gradient를 직접적으로 사용하지 않았으나 유사한 수식이 유도되었다는 점에서 매우 인상적이다.
기존의 최대가능도추정(MLE)방식은 위와같은 손실함수를 사용해 |S|개의 입출력에 대한 손실값을 구하고, 이를 최소화하는 θ를 찾는 것이 목표였다. 하지만, 이 논문에서는 risk를 아래와 같이 정의하고, 이를 최소화하는 학습방식인 MRT를 제안했다. 위의 수식에서 y(x(s))는 search scape(탐색공간)의 전체 집합이다. 이는 S번째 x(s)가 주어졌을 때 가능한 정답집합을 의미한다.
또한, Δ(y, y(s))는 입력 파라미터 θ가 주어졌을 때, sampling한 y와 실제 정답 y(s)의 차이(= error)값을 의미한다.
즉, 이 수식에 따르면 risk R은 주어진 입력과 현재 파라미터 상에서 얻은 y를 통해 현재 모델함수를 구하고, 동시에 이를 사용해 Risk의 기대값을 구한다 볼 수 있다.
이렇게 정의된 Risk를 최소화하는 것이 목표이다.
반대로 risk대신 보상으로 생각하면, 보상을 최대화하는 것이 목표이다. 결국, risk를 최소화할 때 경사하강법, 보상을 최대화할 때는 경사상승법을 사용하기에 수식을 분해하면 결국 온전히 동일한 내용임을 알 수 있다. 따라서 실제 구현 시, Δ(y, y(s))사용을 위한 보상함수 BLEU에 -1을 곱해 Risk함수로 만든다.
다만 주어진 입력에 대해 가능한 정답에 관한 전체공간을 탐색할 수 없기에 전체탐색공간에 sampling한 sub-space에서 sampling하는 것을 택한다.
그 후 위의 수식에서 θ에 대해 미분을 수행한다.
이제, 미분을 통해 얻은 MRT의 최종 수식을 해석해보자. 최종적으로는 수식에서 기대값부분을 Monte Carlo Sampling을 통해 제거할 수 있다. 아래수식은 Policy Gradient의 Reinforce알고리즘 수식으로 앞의 MRT수식과 비교하여 참고해보자.
[MRT의 Reinforce알고리즘 수식]
MRT는 강화학습으로써의 접근을 전혀하지 않고, 수식적으로 Policy Gradient의 Reinforce알고리즘 수식을 도출해내어 성능을 끌어올린다는 점에서 매우 인상깊은 방법임을 알 수 있다.
[Policy Gradient의 Reinforce알고리즘 수식]
Pytorch NMT_with_MRT 예제코드
구현과정
1. 주어진 입력문장에대해 정책 𝜃를 이용해 번역문장 sampling
2. sampling문장과 정답문장사이 BLEU를 계산, -1을 곱해 Risk로 변환
3. log확률분포전체에 Risk를 곱함
4. 각 sample과 time-step별 구해진 NLL값의 합에 -1을 곱해줌(=PLL)
5. 로그확률값의 합에 𝜃로 미분을 수행, BP로 신경망 𝜃전체 기울기가 구해짐
6. 이미 Risk를 확률분포에 곱했기에, 바로 이 기울기로 BP를 수행, 최적화
from nltk.translate.gleu_score import sentence_gleu
from nltk.translate.bleu_score import sentence_bleu
from nltk.translate.bleu_score import SmoothingFunction
import numpy as np
import torch
from torch import optim
from torch.nn import functional as F
import torch.nn.utils as torch_utils
from ignite.engine import Engine
from ignite.engine import Events
from ignite.metrics import RunningAverage
from ignite.contrib.handlers.tqdm_logger import ProgressBar
import simple_nmt.data_loader as data_loader
from simple_nmt.trainer import MaximumLikelihoodEstimationEngine
from simple_nmt.utils import get_grad_norm, get_parameter_norm
VERBOSE_SILENT = 0
VERBOSE_EPOCH_WISE = 1
VERBOSE_BATCH_WISE = 2
class MinimumRiskTrainingEngine(MaximumLikelihoodEstimationEngine):
@staticmethod
def _get_reward(y_hat, y, n_gram=6, method='gleu'):
# This method gets the reward based on the sampling result and reference sentence.
# For now, we uses GLEU in NLTK, but you can used your own well-defined reward function.
# In addition, GLEU is variation of BLEU, and it is more fit to reinforcement learning.
sf = SmoothingFunction()
score_func = {
'gleu': lambda ref, hyp: sentence_gleu([ref], hyp, max_len=n_gram),
'bleu1': lambda ref, hyp: sentence_bleu([ref], hyp,
weights=[1./n_gram] * n_gram,
smoothing_function=sf.method1),
'bleu2': lambda ref, hyp: sentence_bleu([ref], hyp,
weights=[1./n_gram] * n_gram,
smoothing_function=sf.method2),
'bleu4': lambda ref, hyp: sentence_bleu([ref], hyp,
weights=[1./n_gram] * n_gram,
smoothing_function=sf.method4),
}[method]
# Since we don't calculate reward score exactly as same as multi-bleu.perl,
# (especialy we do have different tokenization,) I recommend to set n_gram to 6.
# |y| = (batch_size, length1)
# |y_hat| = (batch_size, length2)
with torch.no_grad():
scores = []
for b in range(y.size(0)):
ref, hyp = [], []
for t in range(y.size(-1)):
ref += [str(int(y[b, t]))]
if y[b, t] == data_loader.EOS:
break
for t in range(y_hat.size(-1)):
hyp += [str(int(y_hat[b, t]))]
if y_hat[b, t] == data_loader.EOS:
break
# Below lines are slower than naive for loops in above.
# ref = y[b].masked_select(y[b] != data_loader.PAD).tolist()
# hyp = y_hat[b].masked_select(y_hat[b] != data_loader.PAD).tolist()
scores += [score_func(ref, hyp) * 100.]
scores = torch.FloatTensor(scores).to(y.device)
# |scores| = (batch_size)
return scores
@staticmethod
def _get_loss(y_hat, indice, reward=1):
# |indice| = (batch_size, length)
# |y_hat| = (batch_size, length, output_size)
# |reward| = (batch_size,)
batch_size = indice.size(0)
output_size = y_hat.size(-1)
'''
# Memory inefficient but more readable version
mask = indice == data_loader.PAD
# |mask| = (batch_size, length)
indice = F.one_hot(indice, num_classes=output_size).float()
# |indice| = (batch_size, length, output_size)
log_prob = (y_hat * indice).sum(dim=-1)
# |log_prob| = (batch_size, length)
log_prob.masked_fill_(mask, 0)
log_prob = log_prob.sum(dim=-1)
# |log_prob| = (batch_size, )
'''
# Memory efficient version
log_prob = -F.nll_loss(
y_hat.view(-1, output_size),
indice.view(-1),
ignore_index=data_loader.PAD,
reduction='none'
).view(batch_size, -1).sum(dim=-1)
loss = (log_prob * -reward).sum()
# Following two equations are eventually same.
# \theta = \theta - risk * \nabla_\theta \log{P}
# \theta = \theta - -reward * \nabla_\theta \log{P}
# where risk = -reward.
return loss
@staticmethod
def train(engine, mini_batch):
# You have to reset the gradients of all model parameters
# before to take another step in gradient descent.
engine.model.train()
if engine.state.iteration % engine.config.iteration_per_update == 1 or \
engine.config.iteration_per_update == 1:
if engine.state.iteration > 1:
engine.optimizer.zero_grad()
device = next(engine.model.parameters()).device
mini_batch.src = (mini_batch.src[0].to(device), mini_batch.src[1])
mini_batch.tgt = (mini_batch.tgt[0].to(device), mini_batch.tgt[1])
# Raw target variable has both BOS and EOS token.
# The output of sequence-to-sequence does not have BOS token.
# Thus, remove BOS token for reference.
x, y = mini_batch.src, mini_batch.tgt[0][:, 1:]
# |x| = (batch_size, length)
# |y| = (batch_size, length)
# Take sampling process because set False for is_greedy.
y_hat, indice = engine.model.search(
x,
is_greedy=False,
max_length=engine.config.max_length
)
with torch.no_grad():
# Based on the result of sampling, get reward.
actor_reward = MinimumRiskTrainingEngine._get_reward(
indice,
y,
n_gram=engine.config.rl_n_gram,
method=engine.config.rl_reward,
)
# |y_hat| = (batch_size, length, output_size)
# |indice| = (batch_size, length)
# |actor_reward| = (batch_size)
# Take samples as many as n_samples, and get average rewards for them.
# I figured out that n_samples = 1 would be enough.
baseline = []
for _ in range(engine.config.rl_n_samples):
_, sampled_indice = engine.model.search(
x,
is_greedy=False,
max_length=engine.config.max_length,
)
baseline += [
MinimumRiskTrainingEngine._get_reward(
sampled_indice,
y,
n_gram=engine.config.rl_n_gram,
method=engine.config.rl_reward,
)
]
baseline = torch.stack(baseline).mean(dim=0)
# |baseline| = (n_samples, batch_size) --> (batch_size)
# Now, we have relatively expected cumulative reward.
# Which score can be drawn from actor_reward subtracted by baseline.
reward = actor_reward - baseline
# |reward| = (batch_size)
# calculate gradients with back-propagation
loss = MinimumRiskTrainingEngine._get_loss(
y_hat,
indice,
reward=reward
)
backward_target = loss.div(y.size(0)).div(engine.config.iteration_per_update)
backward_target.backward()
p_norm = float(get_parameter_norm(engine.model.parameters()))
g_norm = float(get_grad_norm(engine.model.parameters()))
if engine.state.iteration % engine.config.iteration_per_update == 0 and \
engine.state.iteration > 0:
# In orther to avoid gradient exploding, we apply gradient clipping.
torch_utils.clip_grad_norm_(
engine.model.parameters(),
engine.config.max_grad_norm,
)
# Take a step of gradient descent.
engine.optimizer.step()
return {
'actor': float(actor_reward.mean()),
'baseline': float(baseline.mean()),
'reward': float(reward.mean()),
'|param|': p_norm if not np.isnan(p_norm) and not np.isinf(p_norm) else 0.,
'|g_param|': g_norm if not np.isnan(g_norm) and not np.isinf(g_norm) else 0.,
}
@staticmethod
def validate(engine, mini_batch):
engine.model.eval()
with torch.no_grad():
device = next(engine.model.parameters()).device
mini_batch.src = (mini_batch.src[0].to(device), mini_batch.src[1])
mini_batch.tgt = (mini_batch.tgt[0].to(device), mini_batch.tgt[1])
x, y = mini_batch.src, mini_batch.tgt[0][:, 1:]
# |x| = (batch_size, length)
# |y| = (batch_size, length)
# feed-forward
y_hat, indice = engine.model.search(
x,
is_greedy=True,
max_length=engine.config.max_length,
)
# |y_hat| = (batch_size, length, output_size)
# |indice| = (batch_size, length)
reward = MinimumRiskTrainingEngine._get_reward(
indice,
y,
n_gram=engine.config.rl_n_gram,
method=engine.config.rl_reward,
)
return {
'BLEU': float(reward.mean()),
}
@staticmethod
def attach(
train_engine,
validation_engine,
training_metric_names = ['actor', 'baseline', 'reward', '|param|', '|g_param|'],
validation_metric_names = ['BLEU', ],
verbose=VERBOSE_BATCH_WISE
):
# Attaching would be repaeted for serveral metrics.
# Thus, we can reduce the repeated codes by using this function.
def attach_running_average(engine, metric_name):
RunningAverage(output_transform=lambda x: x[metric_name]).attach(
engine,
metric_name,
)
for metric_name in training_metric_names:
attach_running_average(train_engine, metric_name)
if verbose >= VERBOSE_BATCH_WISE:
pbar = ProgressBar(bar_format=None, ncols=120)
pbar.attach(train_engine, training_metric_names)
if verbose >= VERBOSE_EPOCH_WISE:
@train_engine.on(Events.EPOCH_COMPLETED)
def print_train_logs(engine):
avg_p_norm = engine.state.metrics['|param|']
avg_g_norm = engine.state.metrics['|g_param|']
avg_reward = engine.state.metrics['actor']
print('Epoch {} - |param|={:.2e} |g_param|={:.2e} BLEU={:.2f}'.format(
engine.state.epoch,
avg_p_norm,
avg_g_norm,
avg_reward,
))
for metric_name in validation_metric_names:
attach_running_average(validation_engine, metric_name)
if verbose >= VERBOSE_BATCH_WISE:
pbar = ProgressBar(bar_format=None, ncols=120)
pbar.attach(validation_engine, validation_metric_names)
if verbose >= VERBOSE_EPOCH_WISE:
@validation_engine.on(Events.EPOCH_COMPLETED)
def print_valid_logs(engine):
avg_bleu = engine.state.metrics['BLEU']
print('Validation - BLEU={:.2f} best_BLEU={:.2f}'.format(
avg_bleu,
-engine.best_loss,
))
@staticmethod
def resume_training(engine, resume_epoch):
resume_epoch = max(1, resume_epoch - engine.config.n_epochs)
engine.state.iteration = (resume_epoch - 1) * len(engine.state.dataloader)
engine.state.epoch = (resume_epoch - 1)
@staticmethod
def check_best(engine):
loss = -float(engine.state.metrics['BLEU'])
if loss <= engine.best_loss:
engine.best_loss = loss
@staticmethod
def save_model(engine, train_engine, config, src_vocab, tgt_vocab):
avg_train_bleu = train_engine.state.metrics['actor']
avg_valid_bleu = engine.state.metrics['BLEU']
# Set a filename for model of last epoch.
# We need to put every information to filename, as much as possible.
model_fn = config.model_fn.split('.')
model_fn = model_fn[:-1] + ['mrt',
'%02d' % train_engine.state.epoch,
'%.2f-%.2f' % (avg_train_bleu,
avg_valid_bleu),
] + [model_fn[-1]]
model_fn = '.'.join(model_fn)
# Unlike other tasks, we need to save current model, not best model.
torch.save(
{
'model': engine.model.state_dict(),
'opt': train_engine.optimizer.state_dict(),
'config': config,
'src_vocab': src_vocab,
'tgt_vocab': tgt_vocab,
}, model_fn
)
6. RL을 활용한 Unsupervised Learning
지도학습방식은 높은 정확도를 자랑한다. 다만, labeled data가 필요해 data확보나 cost가 높다.
비지도학습방식은 data확보에 대한 cost가 낮기에 더 좋은 대안이 될 수 있다.
(물론, 지도학습에 비해 성능이나 효율이 떨어질 가능성은 높음)
이런 점에서 parallel corpus에 비해 monolinugal corpus를 확보하기 쉽다는 NLP의 특성상, 좋은 대안이 될 수 있다.
소량의 parallel corpus와 다량의 monolingual corpus를 결합 → 더 나은 성능을 확보할 수 있을 것이다.
6.1 Unsupervised를 통한 NMT 이번에 소개할 논문은 오직 monolingual corpus만을 사용해 번역기를 제작하는 방법을 제안했다. [Guillaume Lampl;2018] 따라서 진정한 비지도학습을 통한 NMT라 볼 수 있다.
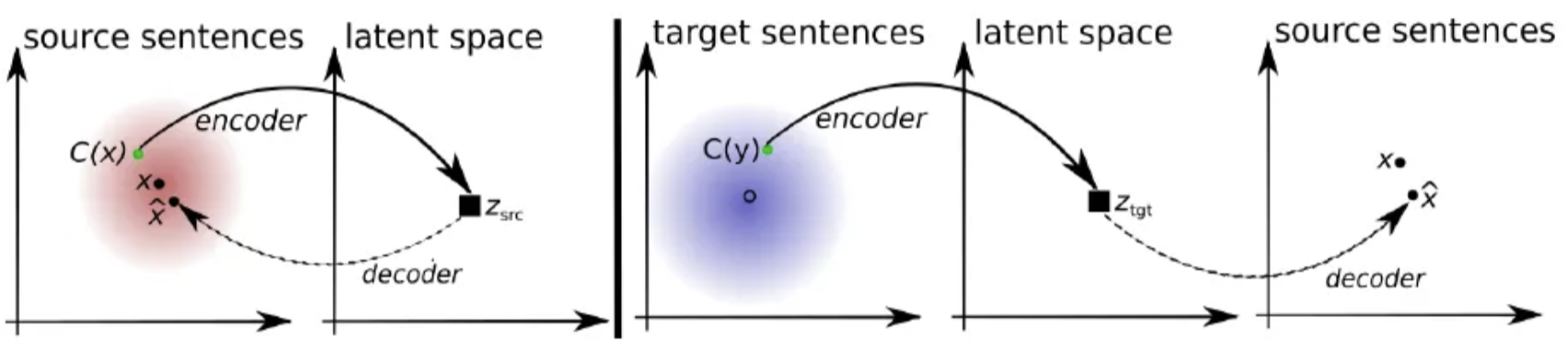
[핵심 idea] ∙ 언어에 상관없이 같은 의미의 문장일 경우, Encoder가 같은 값으로 embedding할 수 있도록 훈련하는 것. 이를 위해 GAN이 도입되었다!! →❓어? 분명 GAN을 NLP에서 못쓴다고 앞서 얘기했던 것 같은데...?? ❗️encoder의 출력값이 연속적 값이기에 GAN을 적용할 수 있었다. [Encoder] 언어에 상관없이 동일한 내용의 문장에 대해 같은 값의 벡터로 encoding하도록 훈련 ∙ 이를 위해 판별자 D(encoding된 문장의 언어를 맞추는 역할)가 필요하고 ∙ D를 속이도록 Encoder는 학습된다.
[Decoder] encoder의 출력값을 갖고 Decoder를 통해 기존 문장으로 잘 돌아오도록 함
즉, Encoder와 Decoder를 언어에 따라 다르게 사용하지 않고 언어에 상관없이 1개씩의 Encoder, Decoder를 사용한다.
결과적으로 손실함수는 아래 3가지 부분으로 구성된다.
손실함수의 3가지 구성
De-noising Auto-Encoder seq2seq도 일종의 Auto-Encoder의 일종이라 볼 수 있다. AE는 굉장히 쉬운 문제에 속한다.
따라서 AE에서 단순히 복사작업을 지시하는대신, noise를 섞어준 src문장에서 De-noising을 하면서 입력값을 출력에서 복원(reconstruction)하도록 훈련해야하는데, 이를 "De-noising AutoEncoder"라 부르며 아래와 같이 표현된다.
이 수식에서 x_hat은 입력문장 x를 noise_model C를 통해 noise를 더하고 같은 언어 ℓ로 encoding과 decoding을 수행하는 것을 의미한다. Δ(x_hat, x)는 MRT에서와 같이 원문과 복원된 문장과의 차이를 의미한다. noise_model C(x)는 임의로 문장 내 단어들을 드롭하거나 순서를 섞어주는 일을 한다.
Cross Domain training ❓Cross Domain훈련이란 사전번역을 통해 사전훈련한 저성능의 번역모델 M에서 언어 ℓ2의 noise가 추가되어 번역된 문장 y를 다시 언어 ℓ1 src 문장으로 원상복구하는 작업을 학습하는 것이다.
Adversarial Learning Encoder가 언어와 상관없이 항상 같은 분포로 latent space에 문장벡터를 embedding하는지 감시하는 판별자 D가 추가되어 적대적 학습을 진행한다. ∙ D는 latent variable z의 기존 언어를 예측하도록 훈련된다. ∙ xi , ℓi는 같은 언어(language pair)를 의미한다. 따라서 GAN처럼 Encoder는 판별자 D를 속일 수 있도록 훈련되어야 한다.
이때, j = - (i - 1) 값을 갖는다.
최종 목적함수 위의 3가지 목적함수를 결합하면 최종 목적함수를 얻을 수 있다. 각 λ를 통해 손실함수 상에서 비율을 조절, 최적의 parameter θ를 찾는다. 논문에서는 오직 monolingual corpus만 존재할 때, NMT를 만드는 방식에 대해 다룬다. parallel corpus가 없는 상황에서도 NMT를 만들 수 있따는 점에서 매우 고무적이다.
다만, 이 방법 자체만으론 실제필드에서 활용하기 어려운데, 실무에서는 번역기구축 시 parallel corpus가 없는 경우는 드물고, 없다 하더라도 monolingual corpus만으로 번역기를 구축해 낮은 성능의 번역기를 확보하기 보단, 비용을 들여 parallel corpus를 직접 구축하고, parallel corpus와 다수의 monolingual corpus를 합쳐 NMT를 구축하는 방향으로 진행하는 것이 낫기 때문이다.
마치며...
이번시간에는 Reinforcement Learning에 대해 알아보고, 이를 이용해 자연어 생성문제(NLG)를 해결하는 방법을 다루었다. 다양한 RL 알고리즘을 사용해 NLG문제의 성능을 높일 수 있는데, 특히 Policy Gradient를 사용해 NLG에 적용하는 방법을 설명했다.
Policy Gradient방법을 NLG에 적용해 얻는 이점은 크게 2가지인다. ① teacher-forcing(AR속성으로 인해 실제추론방식과 다르게 훈련)방법에서 탈피해 실제 추론방식과 같은 sampling을 통해 문장생성능력 향상
② 더 정확한 목적함수를 훈련이 가능하다. - 기존 PPL: 번역품질, NLG품질을 정확히 반영X - 따라서 BLEU 등의 metric을 사용 - 하지만 BLEU 등의 metric은 미분을 할 수 없음. ∴ PPL과 동일한 Cross-Entropy를 활용해 신경망을 훈련해야만 했다.
다만, Policy Gradient 또한 단점이 존재한다. ① sampling기반 훈련이기에 많은 iteration이 필요. 따라서 Cost가 높아 더 비효율적 학습이 진행된다.
② 보상함수는 방향이 없는 스칼라값을 반환한다. 따라서 보상함수를 최대화하는 방향을 정확히 알 수 없다.
이는 기존 MLE방식에서 손실함수를 신경망 파라미터 θ에 대해 미분해 얻은 기울기로 손실함수자체를 최소화하는 방향으로 update하는 것과 차이가 존재한다. 결국, 이 또한 기존 MLE방식보다 훨씬 비효율적 학습으로 이어지게 되는 것이다.