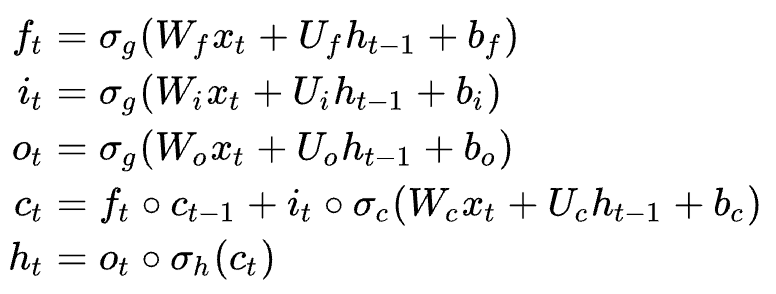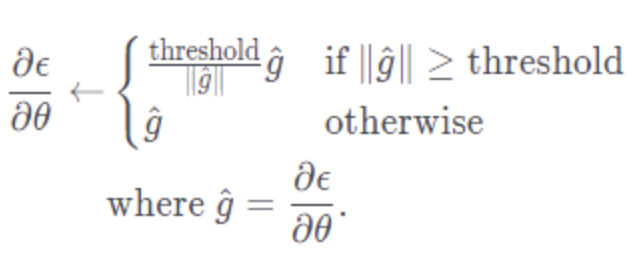자연어 처리분야는 문장 내 단어들이 앞뒤 위치에 따라 서로 영향을 주고받는다. 따라서 단순히 y = f(x)같은 순서의 개념 없이 입력을 넣으면 출력이 나오는 함수의 형태가 아닌, 순차적(sequential)입력으로 입력에 따른 모델의 hidden state가 순차적으로 변하며, 상태에 따라 출력결과가 순차적으로 반환되는 함수가 필요하다.
이런 시간개념이나 순서정보를 사용해 입력을 학습하는 것을 sequential modeling이라 한다. 신경망으로는 RNN 등으로, 신경망 뿐만 아니라 HMM, CRFs(Hidden Markov Model이나 Conditional Random Fields)등의 다양한 방법으로 위의 문제에 접근할 수 있다.
2. RNN
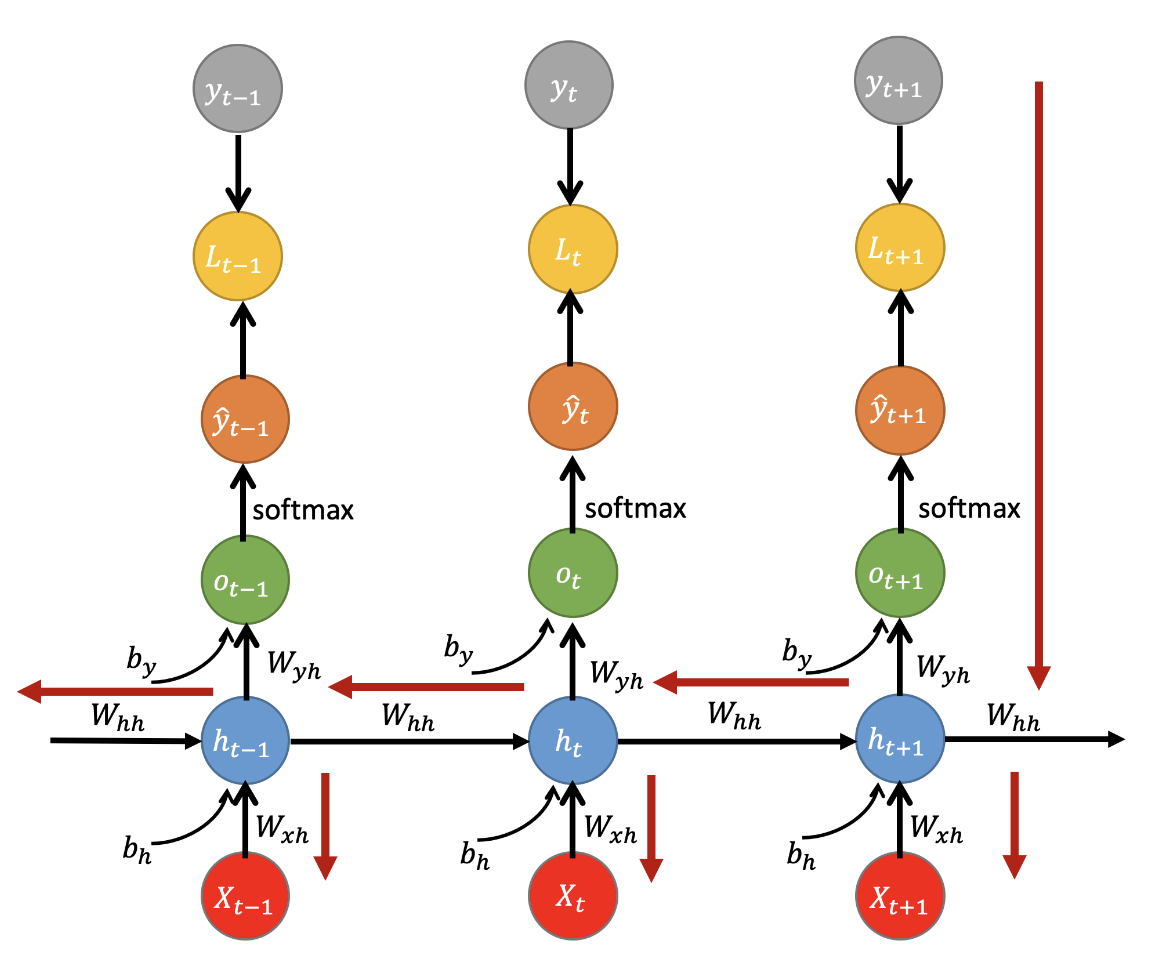
2.1 Feed Forward 기본적인 RNN을 활용한 순전파 계산흐름을 알아보자. 다음 그림은 각 time-step별로 입력 xt와 이전 time-step ht가 RNN으로 들어가 출력 o를 반환한다. 이렇게 도출한 o들을 y_hat으로 삼아서 정답인 y와 비교 후, 손실 L을 계산한다.
이를 수식으로 표현하면 다음과 같다.
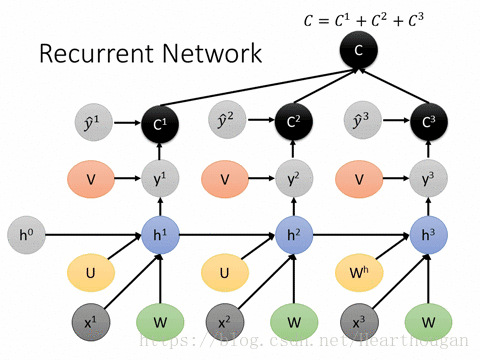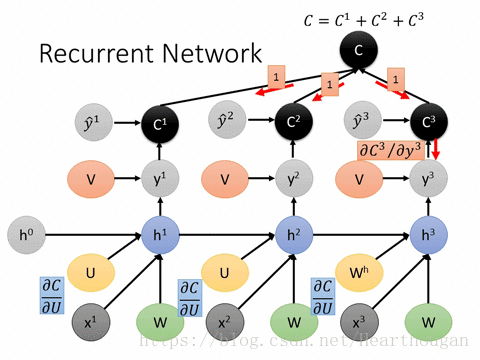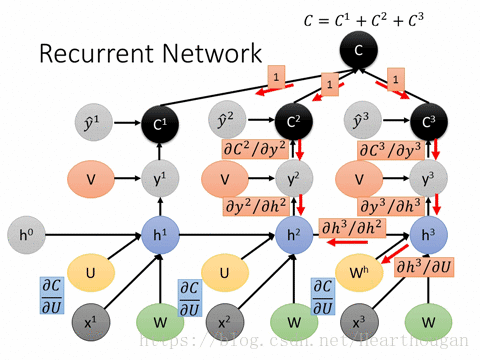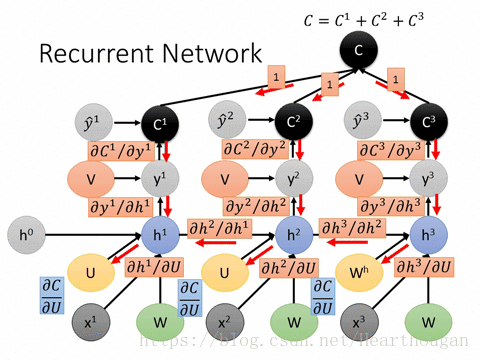
2.2 BPTT (Back Propagation Through Time) 순전파 이후 time-step의 RNN에 사용된 parameter θ는 모든 시간에 공유되어 사용된다. 따라서 앞서 구한 손실 L에 미분을 통해 역전파를 수행하면, 각 time-step별로 뒤로부터 θ의 기울기가 구해지고, 이전 time-step(t-1)θ의 기울기에 더해진다. 즉, t가 0에 가까워질수록 RNN의 parameter θ의 기울기는 각 time-step별 기울기가 더해져 점점 커진다. 아래 그림에서 좌측으로 갈수록 기울기가 더해져 점점커지는 속성을 갖는데, 이 속성을 '시간 축에 대해 수행되는 역전파 방법'이라는 뜻으로 BPTT라 한다.
이런 RNN 역전파의 속성으로 인해, RNN은 마치 time-step 수만큼 layer가 존재하는 것과 같은 상태가 되므로 time-step이 길어질수록 Deep RNN과 유사하게 동작한다.
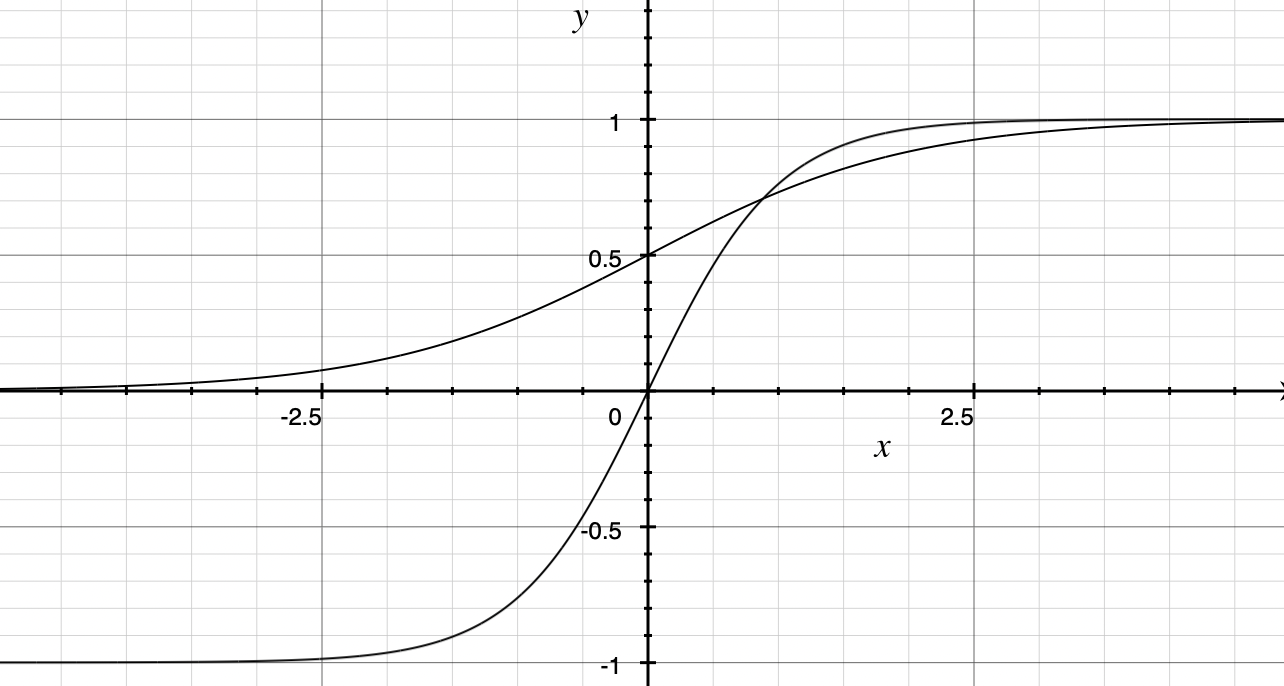
2.3 Gradient Vanishing 앞서 설명했듯, BPTT로인해 RNN은 역전파 시 마치 time-step만큼의 계층이 있는것과 비슷한 속성을 갖는다. 하지만 앞의 RNN 수식을 보면 활성화함수로 tanh함수가 사용된다. tanh의 양 끝 기울기가 -1과 1로 수렴(기울기는 0에 근접)한다. 따라서 tanh 양 끝의 값을 반환하는 층의 경우, 기울기가 0에 가까워진다. 이렇게되면 그 다음으로 미분값을 전달받은 층은 제대로된 미분값(기울기)을 전달받을 수 없게 된다. y>0: sigmoid함수, -1~1: tanh함수 추가적으로 tanh와 sigmoid의 도함수는 모두 기울기 값이 1보다 작거나 같으므로 ❗️층을 거칠수록 기울기의 크기는 작아질 수 밖에 없다!! → gradient vanishing
tanh'(0)=1 , sigmoid'(0)=0.5 값을 갖는다.
따라서 RNN같이 time-step이 많거나 여러층을 갖는 MLP의 경우, 이런 기울기소실문제가 쉽게 발생한다. 다만 MLP에서ReLU와 Skip-Connection의 등장으로 너무 큰 문제가 되는 것은 아니다.
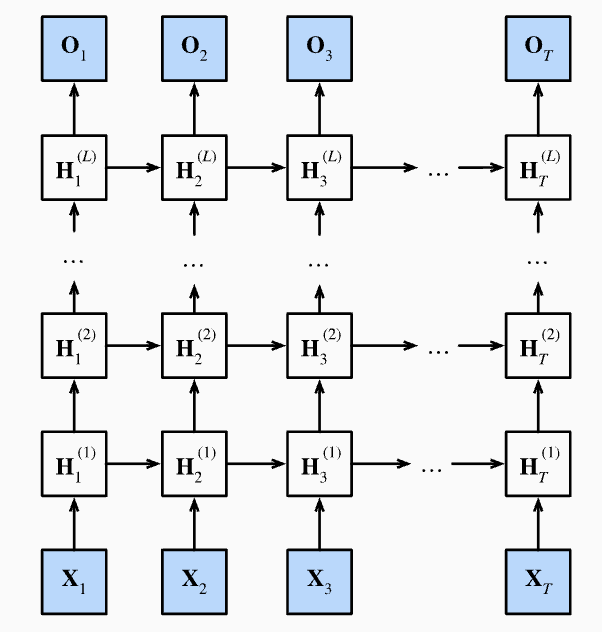
2.4 Deep RNN 기본적으로 time-step별 RNN이 동작한다. 다만, 아래처럼 하나의 time-step내에서 여러층의 RNN을 쌓을 수도 있다. 당연히 층별로 parameter θ를 공유하지 않고 따로 갖는다. 하나의 층만 갖는 기존 RNN의 경우, hidden state와 출력값이 같은 값이었다. 여러 층이 쌓여 이뤄진 RNN의 경우, 각 time-step의 RNN 전체 출력값은 맨 위층 hidden state가 된다. 출력텐서의 크기의 경우 다음과 같다. ∙ 단일 RNN: |h1:n| = (batch_size, n, hidden_size) ∙ Deep RNN: |ht| = (#layers, batch_size, hidden_size)
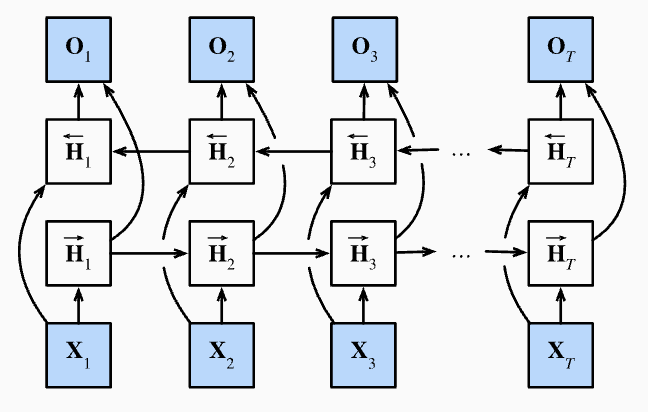
2.5 Bidirectional RNN 이제 RNN의 방향에 관해 이야기해보자. 양방양 RNN을 사용하면 기존 정방향에 역방향까지 추가되어 마지막 time-step에서부터 거꾸로 역방향(reverse direction)으로 입력받아 진행한다. 당연히 정방향과 역방향의 parameter θ는 공유되지 않는다.
결과적으로, output은 과거와 미래 모두에 의존할 수 있게 되는 것이다.
출력텐서의 크기의 경우 다음과 같다. ∙ |ht| = (#direction × #layers, batch_size, hidden_size)
2.6 NLP 적용사례
2.7 정리 NLP에서 거의 대부분의 입출력형태는 모두 불연속적인 값을 갖는다. 즉, regression보다는 classification에 가깝다. 따라서 Cross-Entropy Loss function을 사용해 신경망을 train한다.
이처럼 RNN은 가변길이의 입력을 받아 출력으로 가변길이를 반환하는 모델이다. 하지만 가장 기본적인 Vanilla-RNN은 time-step이 길어질수록 앞의 data기억이 어렵다.
3. LSTM (Long Short Term Memory)
3.1 LSTM ∙ RNN은 가변길이의 sequential data형태 입력에 잘 작동하지만 그 길이가 길어질수록 앞서입력된 data를 까먹는 치명적인 단점이 존재한다. 이를 보완하고자 LSTM이 도입되었다. (여전히 긴 길이의 data에 대해 기억하지는 못함, 보완만 함)
LSTM은 기존 RNN의 은닉상태 이외에 별도의 cell state를 갖게하여 기억력을 증강한다. 추가적으로 여러 gate를 둬 forget, output 등을 효과적으로 제어한다. 그 결과, 긴 길이의 data에 대해서도 효율적으로 대처할 수 있게 되었다.
다만, 구조적으로 더욱 복잡해져서 더 많아진 parameter 학습을 위해 더 많은 data를 이용해 훈련해야한다. 아래는 LSTM의 수식이다.
각 gate의 sigmoid(σ)가 붙어 0~1값으로 gate를 얼마나 열고 닫을지를 결정한다.
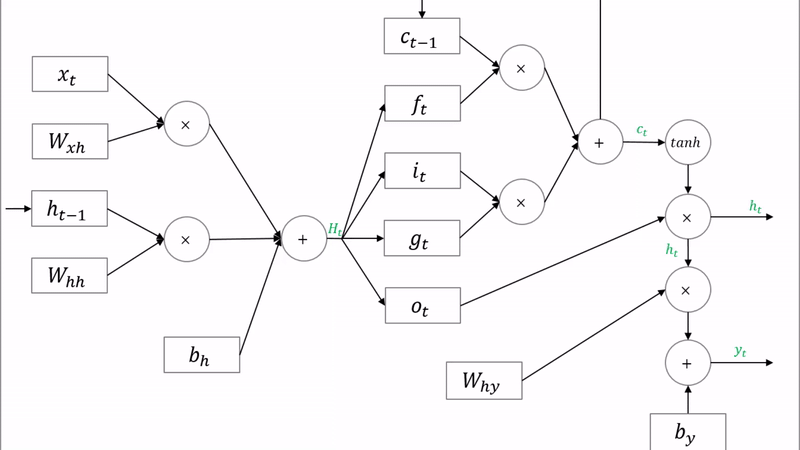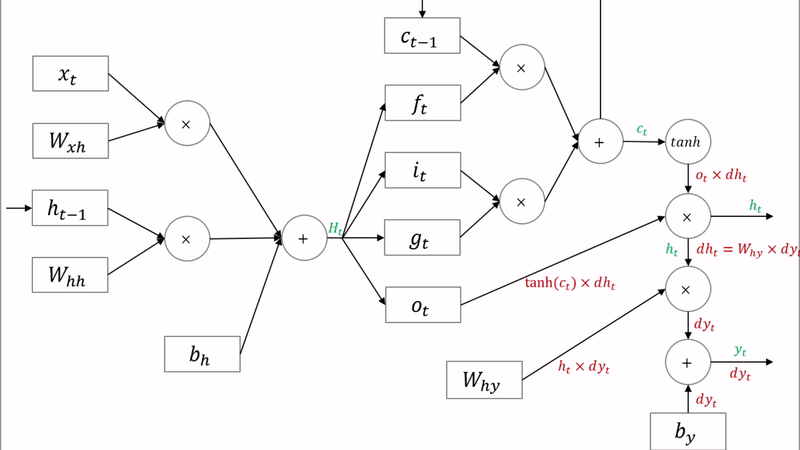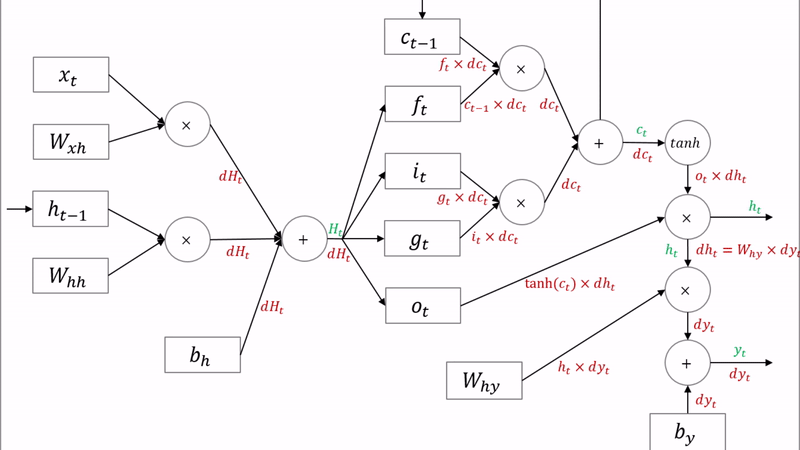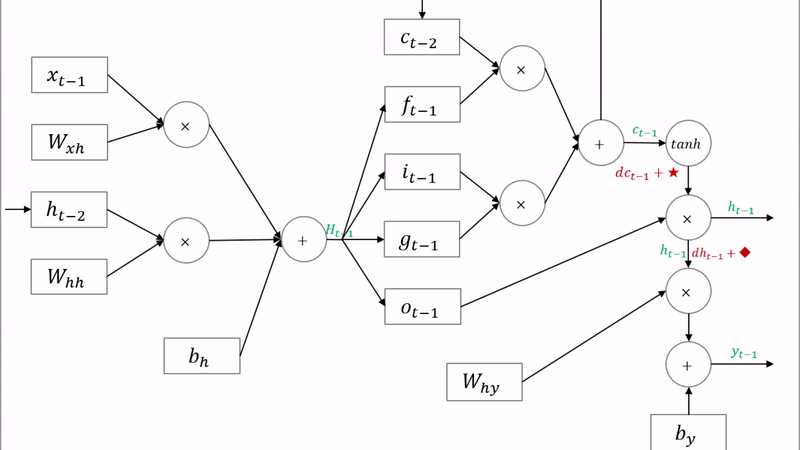
3.2 LSTM의 역전파
4. GRU (Gated Recurrent Unit)
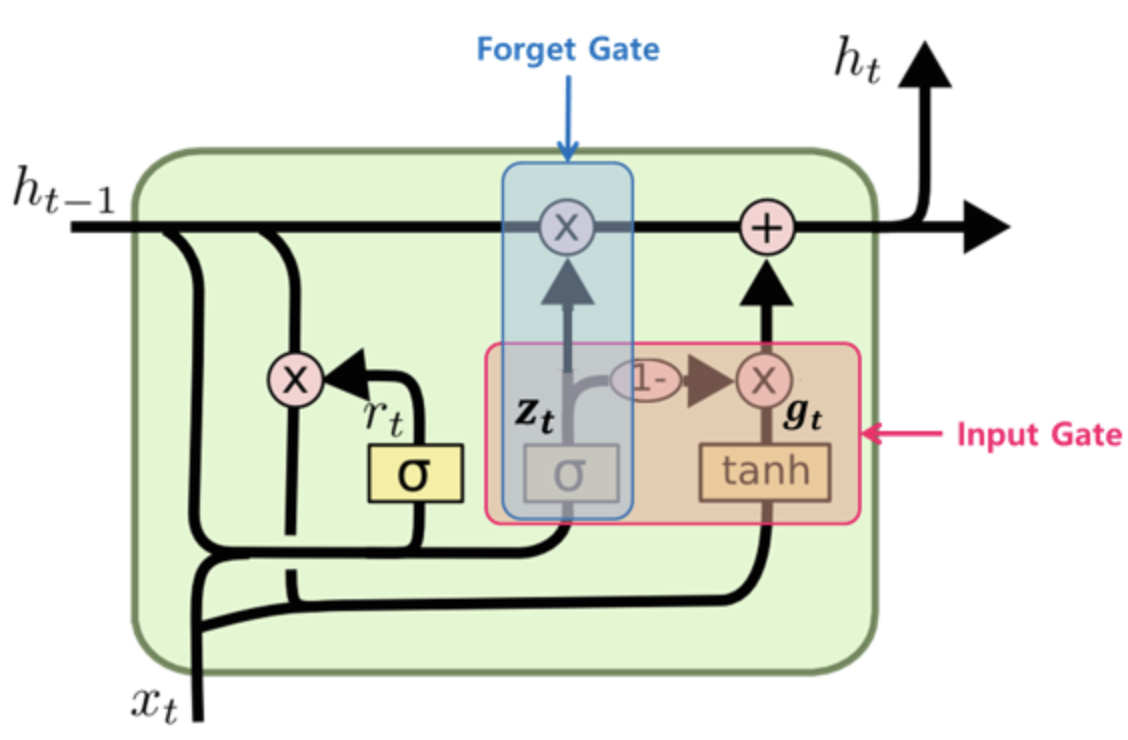
4.1 GRU GRU는 LSTM의 간소화 버전으로 기존에 비해 더 간단하지만 성능이 비슷한 것이 특징이다. σ로 구성된 rt(reset gate)와 zt(update gate)가 존재한다. σ로 여전히 data의 흐름을 열고 닫아 제어할 수 있으며, 기존 LSTM대비 gate의 숫자는 줄고 따라서 gate에 딸려있는 parameter 수도 그만큼 줄어든다. GRU의 수식은 아래와 같다. GRU는 LSTM보다 몸집이 작긴하지만 LSTM이 현저히 사용빈도가 더 높은데, 성능차이보다는 LSTM과 GRU의 학습률, hidden_size등의 hyper-parameter가 다르기에 사용모델에따라 parameter setting을 다시 찾아내야 한다.
5. Gradient Clipping
5.1 Gradient Clipping RNN은 BPTT(Back Propagation Through Time)을 통해 시간역행으로 기울기를 구한다. 매 time step마다 RNN의 parameter에 기울기가 더해지므로 출력의 길이에따라 기울기크기가 달라진다. 즉, 길이가 길수록 자칫 기울기의 크기인 norm이 너무 커지는, gradient exploding문제가 야기될 수 있다.
❗️기울기의 크기가 너무 커질 때, 가장 쉬운 대처법: 학습률을 아주 작게 설정 다만, 훈련속도가 매우 느려질 수 있다는 단점이 존재하며 local optima에 빠질 수 있음 즉, 길이가 가변이기에 학습률을 매번 알맞게 최적의 값을 찾는 것은 무척 어렵기에 이때, Gradient Clipping이 큰 위력을 발휘한다.
Gradient Clipping은 parameter θ의 norm(보통 L2 norm)를 구하고 이 norm의 크기를 제한하는 방법이다. 즉, gradient vector는 유지, 크기를 학습에 영향주지 않는 만큼 줄이는 것이다.
수식을 보면, 기울기 norm이 정해진 최대값(threshold)보다 크다면 최대값보다 큰 만큼의 비율로 나눠준다. 결과적으로 항상 기울기는 threshold보다 작아지게 되며, 이는 학습의 발산을 방지하고 기울기의 방향자체를 바꾸지 않고 유지시켜 parameter θ가 학습해야하는 방향성을 잃지 않게 해준다.
즉, 손실함수를 최소화하기 위한 기울기의 방향은 유지하고, 크기만 조절하기에 학습률을 1과 같이 큰 값으로도 학습에 사용가능하다. 다만, Adam과 같은 동적 학습률을 갖는 optimizer는 사용할 필요성이 없고 SGD와 같은 경우 적용하는 편이 좋다.
아래와 같이 pytorch에서 Gradient Clipping기능을 사용할 수 있다.
import torch.optim as optim
import torch.nn.utils as torch_utils
learning_rate = 1.
max_norm = 5
optimizier = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=0.01)
# 기울기폭발을 피하기 위해 gradient clipping을 도입
torch_utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
마치며...
이번시간에는 RNN을 활용한 순서정보를 가진 순차데이터, 시계열데이터를 학습하는 방법을 익혔다. 기존의 신경망과 달리 RNN은 이전 time step의 자기자신을 참조해 현재 자신의 state를 결정한다. 따라서 time step마다 RNN의 신경망가중치는 공유되지만 기울기소실, 장기기억 등의 문제로 긴 순차데이터처리에 어려움을 겪는다. LSTM과 GRU의 경우, 이런 RNN의 단점을 보완해 여러 gate를 열고 닫아(by sigmoid) 정보의 흐름을 조절함으로써 장기기억력에 더 나은 성능을 보여준다. RNN의 역전파알고리즘인 BPTT는 시간에 대해서도 이뤄지는데, time-step이 많은 data일수록 time-step별 기울기가 더해져 최종기울기가 커진다. 기울기가 클 때, 너무 큰 학습률을 사용하면 해당 학습은 발산할 가능성이 높다.
따라서 기울기가 정해진 임계치보다 커지지 않도록하는 Gradient Clipping을 통해 방향은 유지, 크기만 감소시켜 학습률 1과 같은 매우 큰 값도 학습에 사용할 수 있게 해준다.