- ILSVRC14의 classification과 detection에서 최신기량을 보여주는 새로운 심층신경망구조, 일명 "Inception"을 제안한다. - 이 모델의 가장 큰 좋은 특징은 바로 "계산리소스의 이용면에서의 향상"이다. - 계산리소스를 일정하게 유지하면서 depth와 width를 키웠다는 점에서 주목할만하다. - 이런 특성의 최적화를 위해 구조적인 결정은 Hebbian원리와 multi-scale processing의 직관(intuition)에 기초했다.
cf. [Hebbian Principle]
- Hebbian 원리는 뉴런 간의 연결 강도가 시간이 지남에 따라 어떻게 변할 수 있는지를 설명하는 신경 과학의 개념으로 이 원리는 두 개의 뉴런이 함께 활성화될 때 그들 사이의 연결이 강화된다는 생각에 기반을 둔다. 이것은 학습과 기억의 기초가 되는 신경 경로의 형성으로 이어질 수 있다.
- 이 논문에서는 CNN의 성능을 개선하는 데 도움이 되는 "Local Response Normalization"(LRN)이라는 Hebbian 원리의 변칙을 사용하는 방법에 대해 설명한다.
1. 서론 (Introduction)
•지난 3년간 심층신경망의 엄청난 발전으로 classification과 detection에서 극적인 변화가 있었다. 이에 대한 호재(好材)는 단지 hardware의 발전이나 model이 커지거나 dataset의 많아짐의 덕도 있지만, 더 주요한 것은 새로운 생각과 알고리즘, 향상된 신경망구조의 결과라는 것에 있다. 우리의 GoogLeNet은 불과 2년전의 AlexNet보다 실제 사용하는 parameter 12배 적음에도 더 높은 정확도를 갖는다. Object Detection의 가장 큰 이점은 심층신경망 단독이나 더 큰 모델의 활용이 아닌 R-CNN algorithm(Girshick et al)과 같은 심층 구조와 고전적 컴퓨터비전의 시너지에서 얻었다.
• 다른 주목할 특징은 모바일 및 임베디드의 지속으로 알고리즘의 효율성(특히 전력 및 메모리사용)이 중요해진다는 것이다. 우리의 알고리즘에서 두드러지는(noteworthy) 점은 본 논문에서 제시된 심층신경망 구조의 설계(design)로 이어지는 고려사항이 정확도의 숫자에 대한 순수한 고정관(sheer fixation)보다 위의 요소를 포함했다는 점이다. 대부분의 실험에서 모델은 추론단계(inference)에서 15억배 증가한 계산예산에 유지하게 설계되었기에 순수한 학문적호기심으로 끝나지 않는데, 심지어는 대규모 dataset에서도 합리적인 비용으로 실제로 사용가능하다.
•본논문에서는 컴퓨터비전을 위한 효율적 심층신경망구조인 "Inception"에 초점을 맞춘다. ("we need to go deeper"라는 인터넷 밈에서 파생) 이때, "deep"이라는 단어를 2가지 의미로 사용하였다. - "Inception module"의 형태로 새로운 수준의 조직을 도입한다는 의미 - 신경망의 깊이를 증가시킨다는 직접적인 의미
2.Related Work
• LeNet-5에서 시작해서 CNN은 전형적인 표준구조를 갖는데, stacked conv.layer(보통 선택적으로 정규화 및 maxpooling이 따른다.)는 하나 이상의 FC.layer가 뒤따른다. 이 기본적인 설계를 변형하는 것은 image classification 문헌에 널리 퍼져있다. ImageNet같은 대규모 dataset은 layer크기를 늘리는 동시에 overfitting을 해결하기 위해 Dropout과 같은 방법을 사용한다.
•Max-Pooling이 정확한 공간정보의 손실한다는 우려에도 불구하고 conv.layer의 localization, object detection 등 여러 사례에 활용되는데, 영장류의 시각피질의 신경과학모델에서 영감을 받았다. (Hebbian principle) 이때, Inception layer는 많이 반복되며 Inception model의 모든 filter는 학습되는데, GoogLeNet 모델의 경우, 22개의 layer의 심층모델로 이어진다.
• Network-in-Network는 신경망의 표현력을 높이기 위해 제안된 접근법으로 conv.layer에 적용할 때, 이 방법은 일반적인 rectified linear activation이 뒤따르는 추가적인 1x1 conv.layer로 간주된다. 이를 통해 CNN pipline에 쉽게 통합할 수 있었는데, 본 논문의 구조에서 이 접근방식을 많이 사용한다.
다만 우리의 구조설정에서는 1x1 convolution은 이중적인 목적을 갖는다. - 가장 중요한 목적: 신경망의 크기를 제한하는 계산병목현상(computational bottleneck)의 제거를 위한 차원축소모듈(dimension reduction module). → 성능의 저하 없이 depth, width를 늘릴 수 있음 (∵ 1x1 convolution은 더 큰 convolution에 비해 상대적으로 적은 수의 parameter를 포함하기 때문에 계산에 효율적.) - 부가적인 목적: 신경망의 표현력을 높임
• Object Detection을 위한 가장 최신 접근법은 Girshick 등(et al)이 제안한 R-CNN이다. R-CNN은 전반적인 object detection을 2가지의 하위문제로 나눈다. - category에 구애받지않는 방식으로 잠재적 물체제안을 위한 색상 및 super-pixe의 일관성 같은 저수준의 단서를 먼저 활용한다. - 그 후 CNN classification을 활용해 물의 해당 위치 및 category를 식별한다.
이러한 2단계 접근방식은 저수준의 단서를 갖는 boundaing box segmentation의 정확성 및 최첨단 CNN의 매우 강력한 classifciation 능력을 활용한다. 이때, bounding box의 더 나은 제안 및 classification을 위한 앙상블 접근법과 같은 2단계 모두에서 향상된 기능을 얻어내었다.
3. Motivation and High Level Considerations
- 심층 신경망의 성능을 향상시키는 가장 간단한 방법은 크기를 늘리는 것이다. (이때, 신경망의 깊이(depth), 폭(depth의 unit수)의 증가 또한 모두 포함된다.) 다만 이 해결법은 2가지의 주요 단점이 존재한다.
① 더 큰 크기는 보통 parameter가 많음을 의미하며, 이는 training set이 제한된 경우, overfitting 발생가능성을 높인다. 특히, 아래 그림처럼 더 자세한 구분을 위해 인간이 필요한 경우, 고품질의 training set을 만들기 힘들기에 주요병목현상(major bottleneck)이 될 수 있다.
② 신경망 크기가 균일하게 증가하는 또 다른 단점은 계산 자원의 사용이 극적으로 증가한다는 것이다. 예를 들어 deep vision network에서 2개의 conv.layer의 연결의 경우, filter 수가 균일하게 증가하면 계산이 제곱으로 증가한다. 만약, 추가된 용량이 가중치가 0에 가까울 때처럼 비효율적으로 사용되면 많은 계산자원이 낭비된다.
- 이런 두 문제의 해결에 대한 근본적 방법은 궁극적으로 conv.layer 내부에서fully-connected한 구조에서 덜 연결된 구조로 이동하는 것이다. Dataset의 확률분포(probability distribution)가 크고 매우 희박한 심층신경망의 경우, 마지막층의 activation과 상관관계가 높은 출력을 갖는 clustering neurons의 상관통계를 분석해 최적의 신경망 topology를 층별로 구성할 수 있다고 하는데, 비록 엄밀한 수학적증명이 매우 강한 조건을 요구하지만, 위의 글은 잘 알려진 Hebbian principle와 공명한다는 사실이다. 즉, 근본적 아이디어가 덜 엄밀한 조건에서도 실제로 잘 적용할 수 있다는 점을 시사한다 할 수 있다.
- 부정적인 면에서는 오늘날의 computing infra.는 불균일한 희소자료구조에 대한 수치적계산과 관련해 매우 비효율적이라는 사실이다. 산술연산수가 100배(100x) 줄어든다해도 lookups과 cache 손실의 overhead가 너무나도 지배적이기에 희소행렬(sparse matrices)로의 전환은 효과가 없을 것이다. 또한, 균일하지 않은 희소모델(sparse model)은 더 정교한 공학 및 계산인프라가 필요하다. 현재 대부분의 vision지향 기계학습방식은 convolution을 사용한다는 장점만으로 공간영역의 희소성(sparsity in the spatial domain)을 활용한다. 하지만, convolution은 이전층의 patch의 밀집된 연결모음으로 구성되는데, ConvNet은 전통적으로 특징맵에서 무작위 및 희소연결(random and sparse connection tables)을 사용해 비대칭적으로 학습을 향상시켰다. 이런 추세는 병렬컴퓨팅을 더욱 잘 최적화하기 위해 전체연결로 다시 변경되었는데, 이를 통해 구조의 균일성 및 많은 filter와 더 큰 batch size는 효율적인 dense computation을 사용할 수 있게 하였다.
- 이는 다음의 중간단계에 대한 희망이 있는지에 대한 의문을 제기한다. 이론에서 제안된 것처럼 filter에서조차도 여분의 희소성을 활용하지만 고밀도의 행렬계산을 활용해 현재 하드웨어를 활용하는 구조이다. 희소행렬계산에 대한 방대한자료는 희소행렬을 비교적 고밀도의 submatrices로 clustering하는 것이 희소행렬곱에 대한 최첨단성능을 제공한다는것을 시사한다.
- Inception구조는 vision신경망에서 암시하는 희소구조(sparse structure)를 근사화하고 고밀도로 쉽게사용가능한 구성요소에 의해 가정된 결과를 다루는 정교한신경망 topology구성 알고리즘의 가상출력을 평가하기위한 첫 저자의 사례연구로 시작되었다. 매우 이론적인 방법이었음에도 불구하고 정확한 topology의 선택에 대해 2번 반복 후 이득을 볼 수 있었는데, learning-rate, hyper-parameter 및 개선된 training 방법론(methodology)을 추가하여 결과적으로 Inception구조가 기본 신경망으로서의 localization 및 object detection의 맥락에서 특히낭 유용하다는 것을 알았다. 흥미로운 점은 대부분의 기존구조의 선택에 대한 철저한 의문을 제기하였고 test에도 불구하고 적어도 locally optimal이라는 점이다.
- 제안된 구조가 컴퓨터비전의 성공적 사례가 되었지만, 컴퓨터비전의 구축을 이끈 guiding 원리에 기여할 지는 의문이다. 예를 들어, 아래에 설명된 원칙에 기초한 자동화 툴이 vision신경망에 대해 유사하지만 더 나은 topology를 찾을 수 있는지 확인하려면 훨씬 더 철저한 분석과 검증이 필요하다. 가장 설득력있는 증거는 자동화된 시스템이 동일한 알고리즘을 사용하나 매우 다르게 보이는 global 구조를 사용해 다른 영역에서 유사한 이득을 얻는 network topology를 생성하는 경우인데, 적어도 Inception구조의 초기성공은 이 방향으로의 흥미로운 작업에 대한 확고한 motivation을 제공한다.
4.Architectural Details
[Inception구조의 주요 아이디어., main idea for inception architecture] - 기반: convolution의 optimal local sparse structure가 어떻게 근사화되고 쉽게사용가능한 조밀한 구성요소로 커버되는지를 찾기 위한 것. - translation 불변성(invariance)를 가정하는 것은 우리가 신경망의 conv.block을 구축한다는 의미이다. - 따라서 우리가 필요한 것은 최적의 국소구조(optimal local construction)를 찾고 공간적으로 반복하는 것이다.
cf) sparse structure: 고수준의 정확도를 유지하면서 계산적으로도 효율적이기 위해 설계된 신경망구조 이 논문에서는 높은 정확도를 위해 효율적인 합성곱연산과 희소성의 조합을 사용하도록 신경망이 설계된 방식을 설명한다.
- Arora et al.은 layer-by-layer 구조를 제안한다. (layer-by-layer구조는 하나가 마지막 layer의 통계적 상호관련성과 그들을 높은 연관성으로 군집(cluster)하는 것이다.) 이 군집들 형태는 다음층의 unit과 이전층의 unit간의 연결이 되어있다.
- 우린 이전층의 각 unit이 input image의 일부영역이고, 이런 unit은 filter bank로 그룹화된다 가정한다. 입력층과 가까운 하위층일 수록 상호연관된 unit은 국소영역(local region)에 집중 될 것이다. 이는 즉, 많은 cluster들이 단일영역에 집중되고 다음층에서 1x1 conv.layer로 커버될 수 있음을 의미한다.
- 하지만, 더 큰 patch에 대한 합성곱으로 커버되는 더 적은 수의 공간적으로 분산된 군집(spatially spread out clusters)이 있을 것이며, 더욱 큰 영역에 대한 patch수 감소가 있을 수 있다.
- 이런 patch할당문제를 피하기 위해서, 현재 Inception구조는 filter 크기를 1x1, 3x3, 5x5로 강요하고 있다. 다만, 이런 결정은 필요성이라기 보다는 편리성이라는 점에 더욱 기반을 두고 있다. 이는 Inception구조가 다음층의 입력을 형성하는 단일출력벡터에 연결된 output filter bank와 함께 모든 계층의 조합방식이라는 것을 의미한다. 게다가, pooling은 최신 ConvNet에서 성공을 위해서는 필수적인데, 이는 각 단계에 대안적인 병렬풀링(parallel pooling)을 하는 것이 추가적인 이득을 주는 효과라는 것을 제안한다.
- 이런 "Inception Module"이 서로 겹쳐쌓이기에 출력상관통계(output correlation statistics)는 아래처럼 다양하다. 더 높은 추상화특징이 더 높은층에 의해 포착된다. 이로 인해 더 높은 추상화특징의 공간집중도는 감소할 것이다. 이는 우리가 더 높은층으로 갈수록 3x3과 5x5 convolution 비율이 증가할 것임을 시사한다.
- "Inception Module"의 가장 큰 문제(적어도 단순(naive)한 형태에서)는 적은 수의 5x5 convolution들도 많은 수의 filter가 있는 conv.layer에서 매우 비용이 많이든다는 점이다. 이 문제는 pooling unit을 추가하면 더욱 두드러지는데, output filter수는 이전단계의 filter수와 같다. 즉, pooling.layer output. &. conv.layer output 간의 병합(merge)은 단계간의 output 수를 불가피하게 증가시킨다.
- 이 구조는 최적의 희소구조(optimal sparse structure)를 포함한다. 다만, 매우 비효율적인 수행으로 몇단계가 안지나 computational blowup(폭발)로 이어질 수 있다. 이는 Inception Module에 대한 2번째 아이디어를 이끌어 주었다.
[Inception Module에 대한 2번째 아이디어] - 2번째 아이디어로 이어진 이유는 그렇지 않으면 계산요구량이 많이 증가하기에 차원축소(dimension reduction) 및 차원투영(dimension projection)를 현명하게 적용했는데, 이는 embedding의 성공에 기반했다. 저차원임베딩에서도 상대적으로 큰 image patch에 대해 많은 정보를 포함될 수 있기 때문이다.
- 하지만, 임베딩은 조밀하고 압축된 형태로 정보를 나타낸다. (압축된 정보는 모델링하기 어렵다.) 우린 대부분의 상황에서 희박한 표현력을 유지하고, 신호를 일관적으로 집계해야할 때 압축하고 싶다. 이말인 즉슨, 1x1 convolution은 expensive한 3x3, 5x5 convolution의 이전에서의 reduction을 계산하는데 사용한다는 것이다. 게다가 reduction의 사용은 2가지 목적을 갖는 ReLU의 사용도 포함된다.
[일반적인 Inception 신경망] - grid해상도를 절반으로 줄이기 위해 이따금씩 MaxPooling(with stride=2)이 서로 적층된 inception module로 구성된 신경망이다.
training시 효율적인 memory사용을 위한 기술의 이유로, 다음과 같은 방식을 사용하고자한다. - higher layer: Inception module 사용. - lower layer: 전형적인 convolution방식 이는 너무 엄격하게 필수다!라고는 하지 않으며, 단순히 현재구현된 일부 인프라적 비효율성을 반영하는 것이다.
[Inception 구조의 주요이점] ① 제어되지않는 계산복잡성의 폭발없이, 각 단계에서 unit수를 크게 늘릴 수 있다는 것이다. - 차원축소의 ubiquitous(어디에서나)적 사용은 마지막단계에서 input filter를 다음층으로 차폐(shielding)할 수 있게한다. - 또한 큰 patch로 convolving하기 전에 차원을 줄인다.
② 이 설계방식의 또다른 실용적측면은 시각정보가 다양한규모에서 진행 및 집합하여 동시에 다른 규모로부터의 추상적특징에 대한 직관을 할당한다는 것이다.
5.GoogLeNet
- Yann LeCuns의 LeNet-5 신경망에 대한 경의를 표해 GoogLeNet이라는 이름을 지었는데, ILSVRC14에 제출하는데 사용된 Inception구조의 특정화신을 GoogLeNet을 사용해 언급하였다.
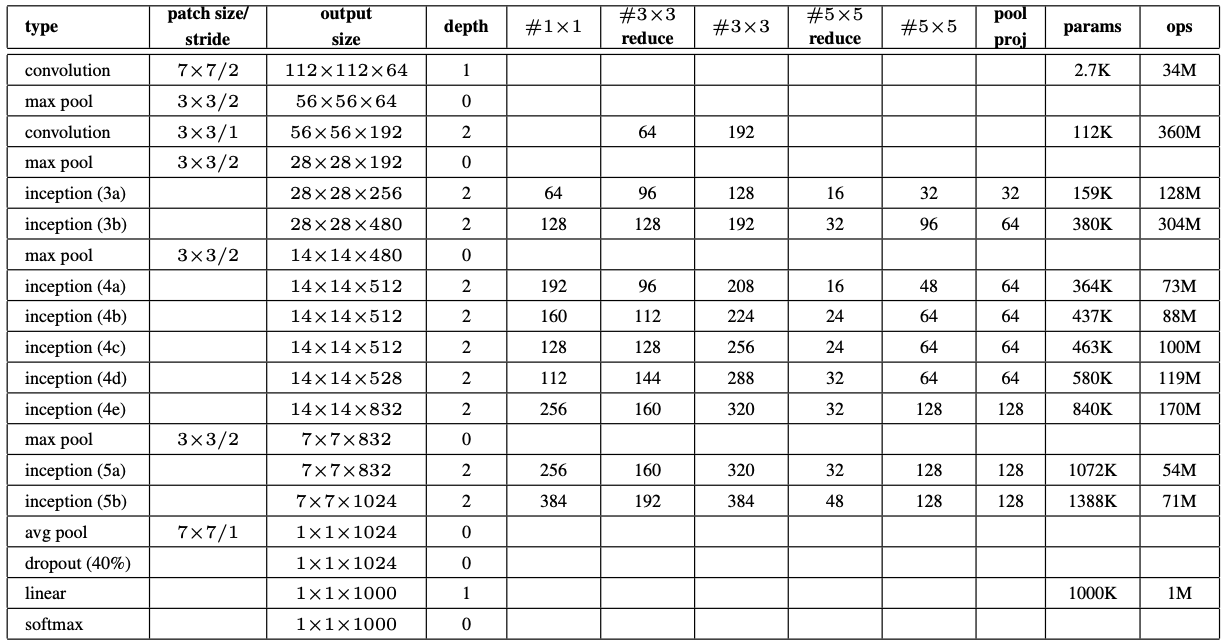
- 또한, 더 깊고 넓은 Inception신경망을 사용했을 때, 품질은 떨어져도 앙상블을 곁들이면 결과가 약간 개선되었다. 실험결과, 정확한 구조의 파라미터의 영향이 상대적으로 작음을 보여주었기에 신경망의 세부사항을 생략한다. 우린 앙상블 7개모델 중 6개에 대해 정확히 동일한 topology(다른 샘플링방법으로 훈련됨)가 사용되었다. 가장 성공적인 특정 GoogLeNet은 시연의 목적으로 위의 표1에 설명되어있다. [Inception Module의 내부구조] - 모든 convolution은 ReLU의 activation을 사용한다. - 신경망에서 수용필드(receptive field)의 크기는 평균감법(mean subtraction)으로 224x224의 RGB channel을 취한다. - "#3x3 reduce" 와 "#5x5 reduce"는 3x3 및 5x5 convolution이전에 사용된축소층(reduction layer)에서의 1x1 filter수를 나타낸다. - Pool proj column에 내장된 MaxPooling 이후의 translation layer에서 1x1 filter의 수를 볼 수 있다. 이런 모든 reduction/projection layer는 ReLU를 사용하며 총 22개의 parameter가 있는 층으로 구성되어 있다. (전체는 풀링포함 27층)
cf) [Projection layer] - 입력 데이터의 차원을 맞춰 다양한 크기의 필터에 대해 연산을 수행할 수 있도록 하는 역할을 하는입력 데이터의 차원을 조정하는 일반적인 convolutional layer이다. 일반적으로 pooling layer는 데이터의 공간적 크기를 줄이기 위해 사용되며, Inception module에서도 pooling layer가 사용될 수 있지만, projection layer와는 별개로 동시에 사용될 수 있다. 예를 들어, 5x5 필터를 적용할 때 입력 데이터의 깊이가 192이고, 출력 특징 맵의 깊이를 32로 설정한다면, 1x1 컨볼루션 연산을 수행하는 projection layer를 사용하여 입력 데이터의 깊이를 32로 줄일 수 있다. 이렇게 차원을 맞춘 입력 데이터를 다양한 크기의 필터에 대해 컨볼루션 연산을 수행하면서 다양한 종류의 특징 맵을 추출한다.
- 분류기(classifier) 이전 Average Pooling의 사용은 [Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. CoRR, abs/1312.4400, 2013.]를 기반으로 한다. 다만, 우리의 구현은 추가적인 linear layer를 사용한다는 점에서 다르다. 이를 통해 다른 label set에 대한 신경망을 쉽게 적용하고 미세조정할 수 있다.
FC.layer에서 Average Pooling으로 이동하면, 상위 1개의 정확도가 약 0.6% 향상된다. Dropout의 사용은 하지만, FC.layer를 제거함에도필수적인 것으로 나타났다.
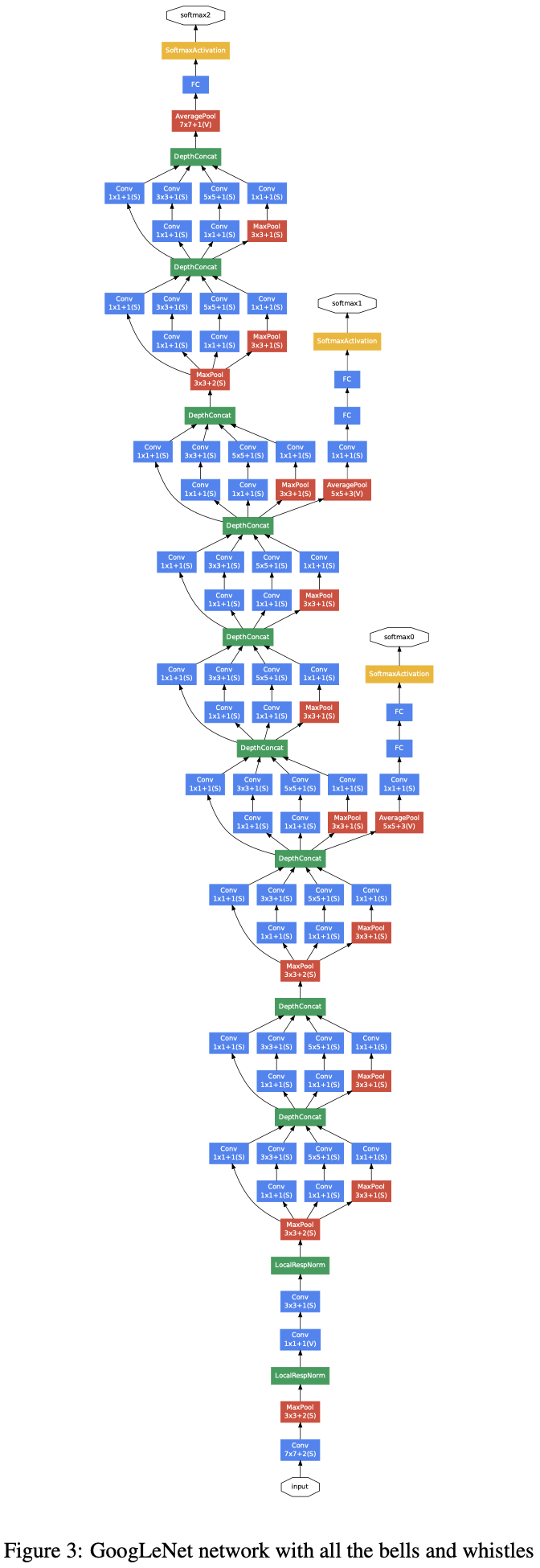
[우려사항] - 신경망의 상대적으로 깊은 깊이 고려시, 모든층에 효과적인 방식으로 gradient를 역전파하는 방식이 우려되었다. - 한가지 흥미로운점은 이때, 상대적으로 얕은 신경망의 강력한 성능이 신경망 중간층에 의해 생성된 특징이 매우 두드러져야만(discriminative) 한다는 점을 시사했다는 것이다. - 이런 중간층에 연결된 보조분류기(auxiliary classifier)를 추가함으로써 classifier가 하위단계에서 매우 두드러지는 특징을 보여준다. 이때, 역전파되는 gradient 신호를 증가시켜 추가적인 규제화(regularization)을 할 수 있을 것이다.
- 이런 classifier는 Inception (4a) 및 Inception (4d) 모듈의 출력위치에 배치된 더 작은 ConvNet의 형태를 취한다. training과정에서, 그들의 Loss는 discount weight인데, 이는 신경망의 전체 Loss에 추가된다. (보조분류기(auxiliary classifier)의 Loss는 0.3의 weight를 부여.)
- 추론(inference)시, auxiliary classifier는 제거되는데, auxiliary classifier를 포함한 부가적인 신경망(extra network on the side)의 정확한 구조는 아래와 같다. • 5×5 filter와 stride=3을 갖는 Avg.pooling layer, (4a)의 경우 4×4×512 output, (4d) 단계의 경우 4×4×528 output. • 차원 축소 및 ReLU를 위한 1×1 convolution(128개 filter존재). • 1024개 unit과 ReLU를 갖는 FC.layer. • Dropout(0.7)의 layer (Drop ratio = 70%) • softmax Loss를 classifier로 linear layer(main classifier와 동일한 1000개 클래스를 예측하지만 추론 시간에 제거됨).
cf) Inference time 추론 시간은 학습된 기계 학습 모델이 이미 학습된 후 새로운 입력에 대해 예측 또는 추론을 수행하는 데 걸리는 시간이다. 학습된 모델을 새로운 데이터에 적용하고 출력 예측을 생성하는 데 걸리는 시간으로 즉, 모델의 레이어를 통해 입력 데이터의 순전파(foward pass)를 수행하고 예측된 출력을 생성하는 데 걸리는 시간이다.
결과 네트워크의 개략도는 그림 3, 아래와 같다.
6. Training Methodology
- 우리의 신경망은 DistBelief를 training으로 사용했다. (DistBelief는 대규모 분산 기계학습 시스템으로서 구글 클라우드 플랫폼에서 실행되는 클라우드 서비스이다. DistBelief의 단점으로는 구글 내부 인프라와 너무 단단히 연결되어 있다는 점, 뉴럴 네트워크만 지원한다는 점을 들 수있다.)
- 우리의 image sampling방법은 대회를 거치면서 몇달동안 크게 변화했다. 이미 통합된모델은 다른방법으로 (decay, learning rate같은 hyper-parameter의 변경으로) training을 진행하였기 때문에 이런 신경망을 training하는 가장효과적인 하나의 방법을 결정내리기 어렵다.
- 더욱 방법을 복잡하게 하기위해, 관련결과를 작게하거나 크게하는 등의 학습을 진행하였다. - 그러나 대회 후 효과가 좋다고 확인한 한가지 규칙(prescription)은 크기가 image면적의 8~100%사이에 고르게 분포하고 가로/세로가 3/4 ~ 4/3 사이에서 무작위선택되는 image의 다양한 크기 patch의 sampling을 포함한다는 것이다. - 또한, 광도왜곡(photometric distortion)이 overfitting 극복에 어느정도 유용하다는 것을 알아냈다.
- 게다가, 다른 hyper-parameter의 변화와 함께 크기조정을 위해 (bilinear, area, nearest neighbor and cubic, with equal probability 같은) 무작위보간방법(random interpolation methods)을 상대적으로 늦게 사용했다. 따라서 최종결과가 위의 방법의 사용으로 긍정적영향을 받았는지의 여부를 절대적으로 확신할 수 없다.
Adam versus SGD
cf. 대부분의 논문들에서 Adam 대신 SGD를 많이 사용하는데 그 이유는 무엇일까? Adam optimizer: 다양한 문제에서 좋은 결과를 보이는 최신 optimization Algorithm이지만 항상 최선의 선택은 아닌데, 이유는 다음과 같다.
1. Overfitting - Adam optimizer는 경사 하강법보다더 빠르게 수렴할 수 있지만, 이는 모델이 데이터에 과적합될 가능성을 높일 수있습니다. - 이런 점은작은 학습률을 사용할 때 더 두드러집니다. 2. Data size(크기) -Adam optimizer는 많은 데이터를 가진대규모 데이터 세트에서 더 잘 작동합니다. - 그러나 작은 데이터 세트에서는 SGD와 같은 더 간단한 알고리즘이 더 나은 결과를 보일 수 있습니다 3. Convergence speed (수렴속도) - Adam optimizer는초기 학습 속도가 빠르므로 초기 학습 속도를 낮추는 것이 필요할 수 있습니다. - 그러나 이렇게 하면수렴 속도가 느려질 수있습니다 따라서, Adam optimizer보다 SGD를 사용하는 이유는 데이터 세트의 크기, 과적합 문제, 수렴 속도 등 여러 가지 요인이 관련되기에 알고리즘을 선택할 때는 해당 문제와 데이터 세트에 대한 이해를 고려해야 한다.
7. ILSVRC-2014 Classification. Challenge. Setup and Result
- ILSVRC 2014 classification에는 1.2백만의 training dataset. //. 각각 5만, 10만개의 validation, test dataset이 있다. top-1 accuracy rate: predict class와 ground truth를 비교 top-5 accuracy rate: ground truth자료를 처음 5개의 predict class와 비교 (ground truth자료가 top-5안에 있으면 image가 옳게 분류된 것으로 간주)
- 대회참가에서 training에는 외부데이터를 사용하지 않았다. - training 기술은 이 논문에서전술(aforemention)한 것과 같으며, testing에서는 고성능을 얻기 위해 아래와 같은 정교한 기술을 사용했다. ① 동일한 GoogLeNet모델의 7개 버전을 독립적으로 training하고 ensemble prediction을 수행했다. - 이 모델은 동일한 초기화 및 learning rate방식으로 훈련했고, sampling방법과 input image는 단지 순서만 무작위로 다르다. (이때, 초기화는 주로 동일한 초기화가중치를 사용했는데, 간과(oversight)의 이유 때문이었다.)
② testing방식에서, AlexNet보다 더 공격적인(aggressive) cropping 접근법을 채택했다. - 구체적으로, (256, 288, 320, 352로 제각각인 4개의) 더 짧은 치수(height or width)의 사용으로 image크기를 조정한다. 이때, resize된 이미지의 크기는 좌측, 중앙 및 우측 방형(square)을 취한다(초상화의 경우에는 상단, 중앙 및 하단 방형을 취한다). - 각 방형에 대해 resize된 224x224 방형image 뿐만 아니라 4개의 모서리와 중앙이 crop된 224x224도 있는그대로의 버전을 반영한다(mirrored version). - 결과적으로, 이는 image 하나 당 4×3×6×2 = 144개의 결과물이 생긴다. - 이후 나오는 내용에서 알 수 있듯, 상당수의 결과물이 존재하면 많은 결과물의 이점이 미미해지기에 실제로 적용시에는 이러한 공격적인 crop은 필요하지 않을 수 있다는 점을 주의해야한다.
③ softmax 확률(probability)는 최종적인 예측값을 얻기 위해 여러 결과물 및 모든 개별분류기(individual classifiers)에 걸쳐 평균화된다. - 우리의 실험에서 결과물에 대한 MaxPooling과 classifier에 대한 평균같은 validation data에 대해 접근방법의 대안을 분석했으나 이들은 단순평균(simple averaging)보다 성능이 떨어진다.
[최종제출의 전반적인 성과요인 분석] - 성과: 대회에서 최종 제출은 validation, test data에서 6.67%의 top-5 error로 1위를 차지했다. 이는 2012년 SuperVision방식에 비해 56.5% 낮은 수치이다. classifier training에서 외부데이터를 사용한 전년도의 최고접근법인 Clarifai에 비해 약 40% 감소한 수치이다. 위의 표는 최고성능접근법에 대한 통계의 일부를 보여준다.
- 성과요인 분석: 위의 표에서 image prediction 시 모델 수와 사용되는 Crop의 수를 변경해 여러 test선택의 성능을 분석할 것이다. 하나의 모델만을 사용시 validation data에서 top-1 error rate인 모델을 선택 모든 숫자는 test data 통계에 overfitting되지 않도록 validation set을 이용한다.
8. ILSVRC-2014 Detection. Challenge. Setup. and. Result
9. Conclusions
- 본 논문의 결과는 쉽게 사용가능한 고밀도의 building block들에 의해 예상되는 최적의 빈약한 구조를 근사화하는 것이 컴퓨터비전을 위해 실현가능한 신경망 개선방법이라는 것을 알 수 있다. - 이 방법의 주요 이점은 얕고 덜 넓은 신경망에 비해 계산요구량이 약간 증가하게 될 때의 상당한 품질의 향상을 얻는다는 것 이다. 또한, context의 활용이나 bounding box regression을 하지 않아도 우리의 detection은 경쟁력이 있었으며 이 사실은 Inception 구조의 강점에 대한 추가적 증거라는 점을 제공해준다.
- 비록 유사한 깊이와 폭을 갖는 더 expensive한 신경망에 의해 유사한 결과를 얻을 수 있을 수도 있지만 우리의 접근방식은 희소적인 구조로의 이동이라는 점이 일반적으로 실현가능하고 유용한 생각이라는 확실한 증거를 제공한다.
🧐 논문 감상_중요개념 핵심 요약
"Going deeper with convolutions" CNN의 개념과 이미지 분류 작업에서의 효율성을 소개하는 연구 논문으로 이 논문은 filter 크기가 다른 여러 병렬 convolution을 사용해 CNN을 효율적으로 훈련하는 "Inception Module"이라는 모듈을 제안한다.
[핵심 개념]
1. Inception Module - GoogLeNet 아키텍처는 커널 크기(1x1, 3x3 및 5x5)가 다른 여러 병렬 컨벌루션 경로로 구성된 Inception 모듈을 사용한다. 이를 통해 네트워크는 다양한 규모의 기능을 캡처할 수 있고 네트워크 훈련의 계산 비용을 줄일 수 있다.
- 또한 Inception 모듈에는 입력의 차원을 줄이고 계산 속도를 높이기 위해 1x1 컨볼루션이 포함되어 있다.
- GoogLeNet 구조는 여러 Inception 모듈을 쌓고 보조 분류기를 사용하여 신경망이 서로 다른 층에서 구별되는 특징을 학습하도록 한다. 이 논문은 GoogLeNet 아키텍처가 AlexNet 및 VGG를 포함한 다른 CNN 아키텍처보다 더 적은 매개변수와 계산으로 ImageNet 데이터 세트에서 최첨단 성능을 달성한다는 것을 보여준다.
cf) depth는 깊이와 관련, width는 filter의 unit과 관련
2. 1x1 convolution - GoogLeNet 구조는 또한 1x1 convolution을 사용하여 특징 변환 및 차원 축소를 수행하는 "네트워크 내 네트워크"(Network-in-Network) layer의 개념을 도입한다.
- Network-in-Network layer는 Inception module과 함께 사용되어 네트워크의 계산 비용을 더욱 줄인다.
cf) 3x3, 5x5은 1x1보다 expensive하다.
3. Normalization 각 층에 대한 입력을 정규화하고 내부 공변량 이동(internal covariance shift)을 줄이는 배치 정규화(Batch Normalization)의 사용으로 신경망이 더 빠르게 수렴하고 과적합을 줄이는 데 도움이 되게한다.
전반적으로 이 논문은커널 크기가 다른 여러 병렬 합성곱 경로(multiple parallel convolutional pathways)를 사용해 깊은 CNN을 효율적으로 training하는 Inception 모듈을 소개한다. 이 논문은 GoogLeNet 구조가 ImageNet에서 최첨단 성능을 달성하고 심층 CNN trainig의 계산 비용(computational cost)을 줄인다는 것을 보여준다.
🧐 논문을 읽고 Architecture 생성 (withtensorflow)
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout, Dense, Flatten, AveragePooling2D, concatenate
def inception_module(x, filters):
# Filters is a tuple that contains the number of filters for each branch
f1, f2, f3, f4 = filters
# Branch 1
branch1 = Conv2D(f1, (1, 1), padding='same', activation='relu')(x)
# Branch 2
branch2 = Conv2D(f2, (1, 1), padding='same', activation='relu')(x)
branch2 = Conv2D(f2, (3, 3), padding='same', activation='relu')(branch2)
# Branch 3
branch3 = Conv2D(f3, (1, 1), padding='same', activation='relu')(x)
branch3 = Conv2D(f3, (5, 5), padding='same', activation='relu')(branch3)
# Branch 4
branch4 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(x)
branch4 = Conv2D(f4, (1, 1), padding='same', activation='relu')(branch4)
# Concatenate the outputs of the branches
output = concatenate([branch1, branch2, branch3, branch4], axis=-1)
return output
def GoogLeNet(input_shape, num_classes):
input = tf.keras.layers.Input(shape=input_shape)
# First Convolutional layer
x = Conv2D(64, (7, 7), strides=(2, 2), padding='same', activation='relu')(input)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
# Second Convolutional layer
x = Conv2D(64, (1, 1), padding='same', activation='relu')(x)
x = Conv2D(192, (3, 3), padding='same', activation='relu')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
# Inception 3a
x = inception_module(x, filters=(64, 96, 128, 16))
# Inception 3b
x = inception_module(x, filters=(128, 128, 192, 32))
# Max pooling with stride 2
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
# Inception 4a
x = inception_module(x, filters=(192, 96, 208, 16))
# Inception 4b
x = inception_module(x, filters=(160, 112, 224, 24))
# Inception 4c
x = inception_module(x, filters=(128, 128, 256, 24))
# Inception 4d
x = inception_module(x, filters=(112, 144, 288, 32))
# Inception 4e
x = inception_module(x, filters=(256, 160, 320, 32))
# Max pooling with stride
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
# Inception 5a
x = inception_module(x, filters=(256, 160, 320, 32))
# Inception 5b
x = inception_module(x, filters=(384, 192, 384, 48))
# global average pooling layer
x = AveragePooling2D((7, 7), padding='same')(x)
x = Flatten()(x)
# Fully Connected layer with linear. and. Dropout
x = Dropout(0.4)(x)
x = Dense(1024, activation='relu')(x)
# softmax
output_layer = Dense(num_classes, activation='softmax')(x)
# define the model with input and output layers
model = tf.keras.Model(inputs=input, outputs=output_layer)
return model
model = GoogLeNet(input_shape=(224,224,3), num_classes=1000)
model.summary()