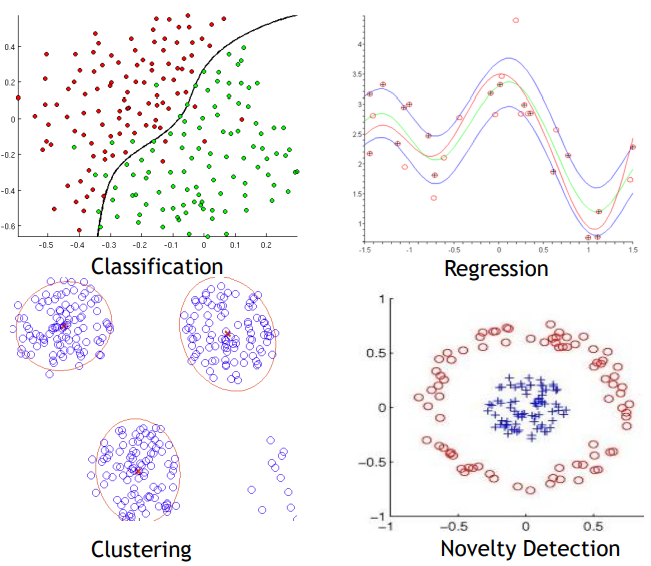
※ Supervised learning 과 Unsupervised learning
▶ Supervised learning (지도학습) _ Classification, Regression, etc.
정답과 오답 등과 같은 답이 있는 train dataset (학습데이터)로 학습시키는 것
§ 지도학습 알고리즘
- 선형 회귀(linear regression)
- 로지스틱 회귀(logistic regression)
- k-최근접 이웃(k-NN : k-Nearest Neighbors)
- 결정 트리(decision trees)
- 신경망(neural networks), Deep NN
- 서포트 벡터 머신(SVC : support vector machines)
- 랜덤 포레스트(randome forests)
▶ Unsupervised learning (비지도학습) _ Clustering, PCA, etc.
정답과 오답 등과 같은 답이 없는 train dataset (학습데이터)로 학습시키는 것
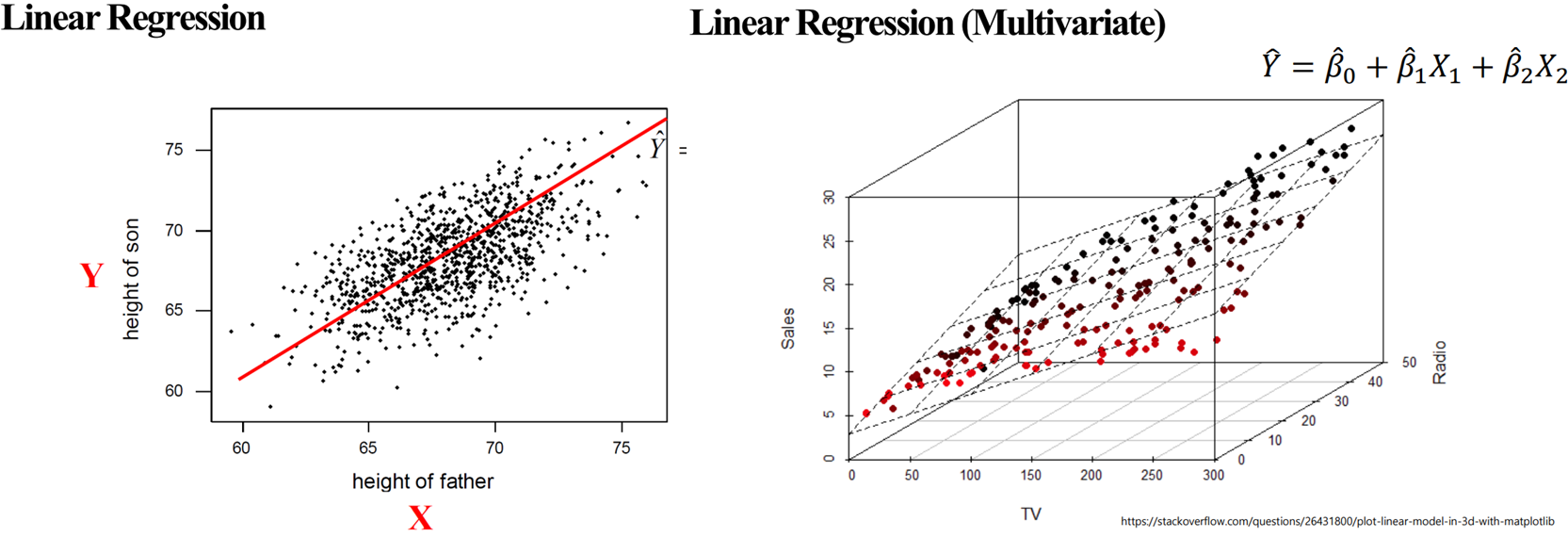
※ (Linear) Regression
장점: 사용하기 쉽고 설명력이 있다. (popular and easy to use, explain with prediction)
단점: 정확도와 linear 관계성을 설명해야 한다. (redundant features, irrelevant features)
 Examples
Examples
▶ 목적: how to predict y-values (continuous values)



§ β값은 어떻게 찾을 것인가?
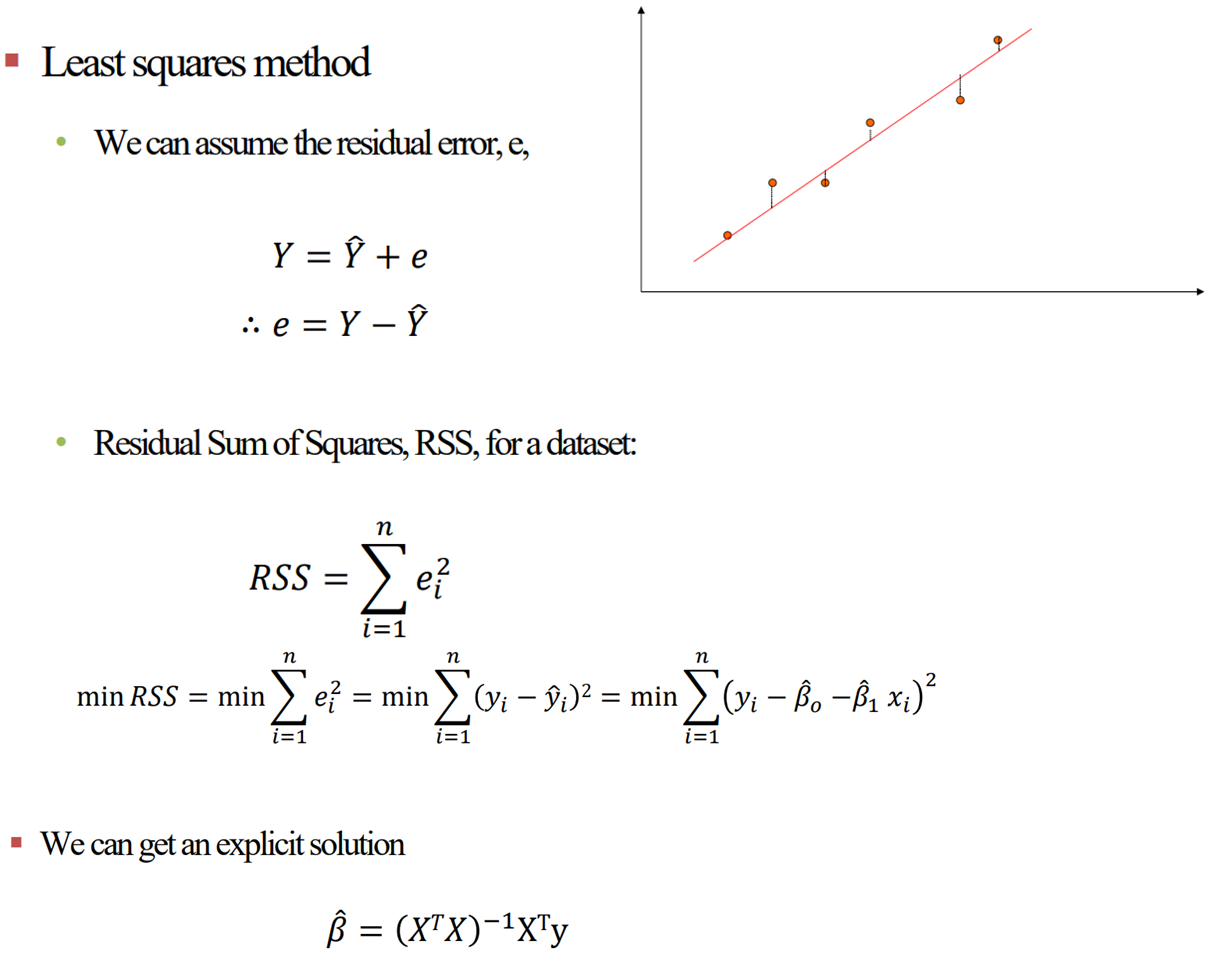 1차 직선그래프에 대해 빨간 점과 그래프 사이의 y축과 평행한 거리가 error값이 된다.
1차 직선그래프에 대해 빨간 점과 그래프 사이의 y축과 평행한 거리가 error값이 된다.
[ β_hat 구하는 방법 증명 ]

※ Model evaluation (모델 평가) [ feat. y, y_hat ]
 Correlation value: 상관계수
Correlation value: 상관계수

※ Regularization (규제화)

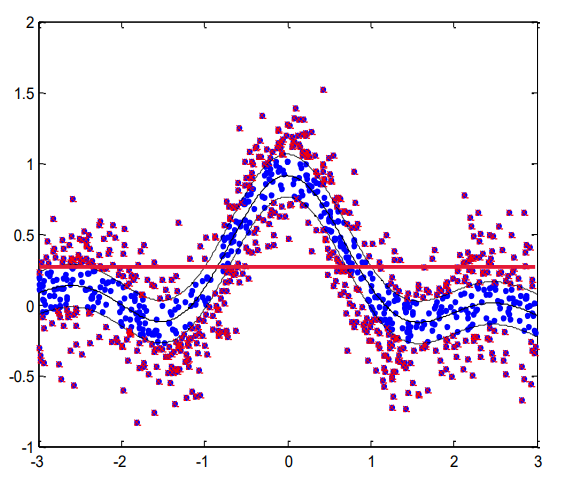
※ Nonlinear Regression
- input과 output사이의 관계성이 선형(nonlinear)일 때
※ Logistic Regression

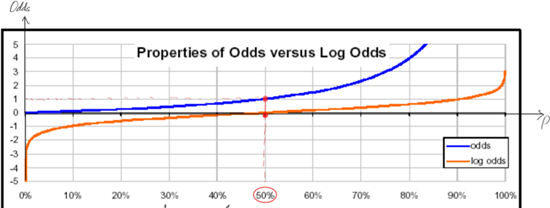
※ Logistic Function

※ Logistic Regression 의 해석 방법

※ (Linear)Regression vs Logistic Regression
§ Regression
장점: 사용하기 쉽고 설명력이 있다. (popular and easy to use, explain with prediction)
단점: 정확도와 linear 관계성을 설명해야 한다. (redundant features, irrelevant features)
§ Logistic Regression
장점: 해석력이 괜찮고 사용하기 편하다. (Interpretability, Easy to use)
단점: 예측력(prediction)이 다른 모델에 비해 뛰어난 편에 속하지는 않는다. (Performance)