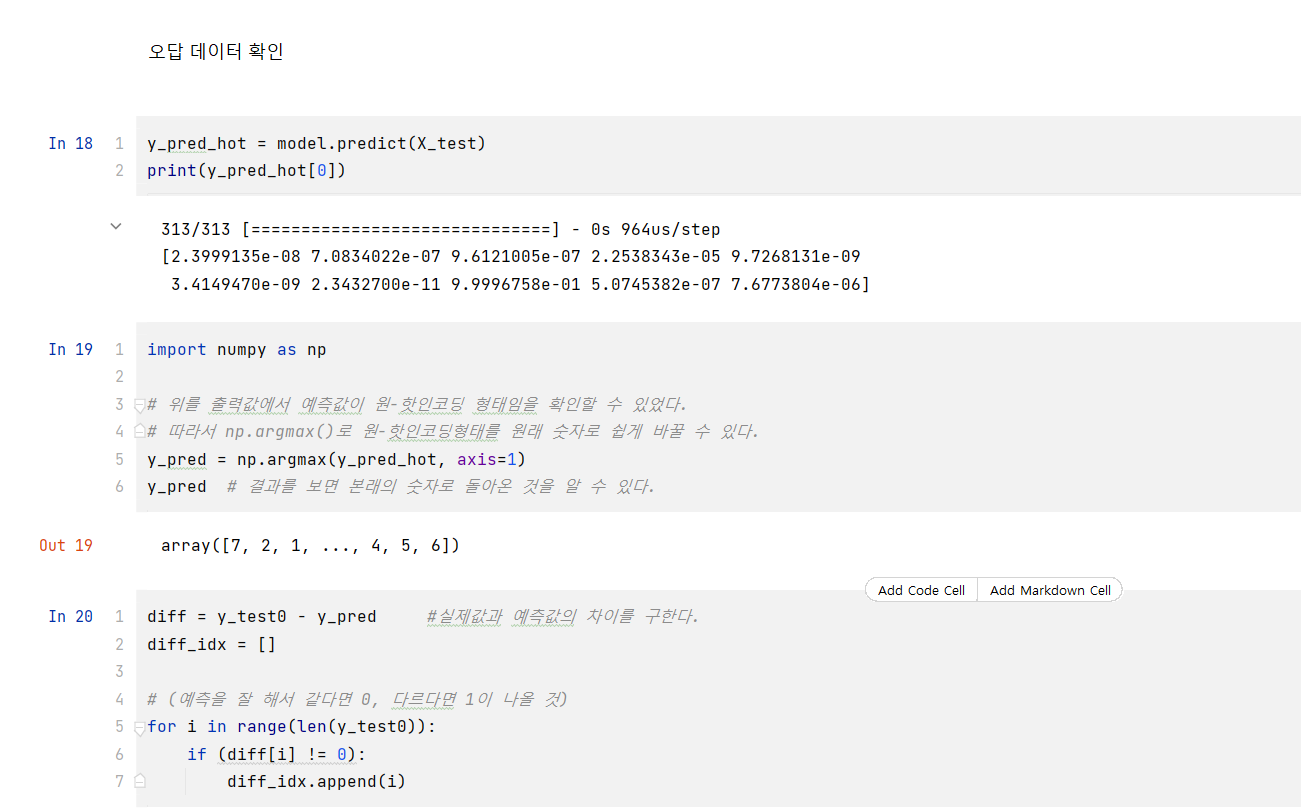
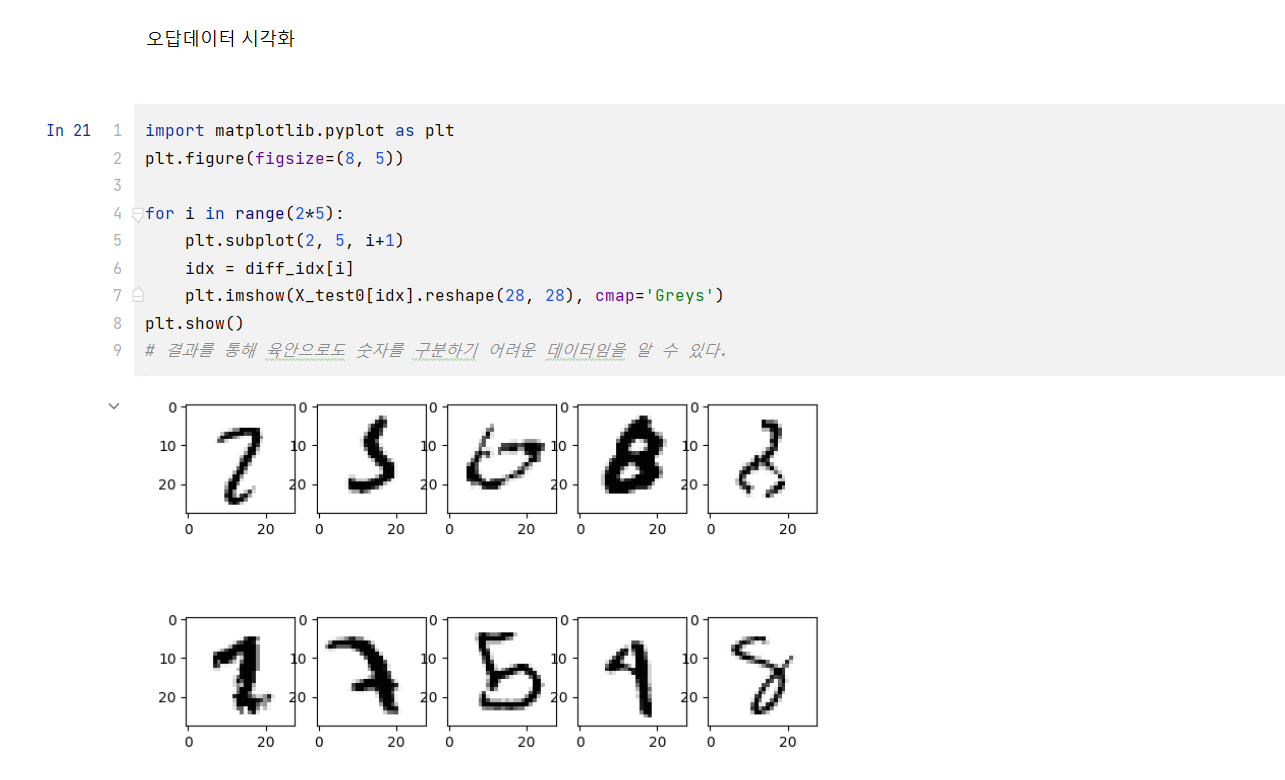
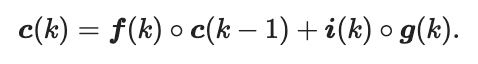🤫 RNN, 순환 신경망이란? RNN은 특정시점 데이터를 한번에 수집하는 방법들과 다르게 sequence data(시간의 흐름에 따라 값이 달라지는 데이터)를 사용한다. 또한 지금까지 다룬 신경망은 feed forward 신경망 즉, 한번 출력된 결과를 다시 사용하지 않았지만 RNN의 경우, 출력결과를 다음시점까지 기억했다가 다음 시점에서 사용하는 방법이다.
가장 일반적인AI딥 러닝을 사용한 시계열 작업에 대한 접근 방식은 순환 신경망(RNN)인데, RNN을 사용하는 이유는 시간에 대한 해결의 일반화에 있다.시퀀스는 (대부분) 길이가 다르기 때문에 MLP 같은 고전적인 딥러닝 구조는 수정하지 않고는 적용할 수 없고MLP의 가중치 수는 absolutely huge하다.따라서 전체 구조에서 가중치가 공유되는 RNN을 일반적으로 사용한다. (in sequential data)
activation function이 tanh일 때, 아래와 같은 과정으로 수식이 진행된다. 다만 은닉층에서 편향 벡터(bias vector)가 있다면 이전처럼 더해주면 된다.
🤫 RNN의 종류
🤫 시간을 통한 Backpropagation
single time step일 때, 아래와 같은 단계로 진행된다. input이 hidden layer를 거쳐 output에 도착하는데, 이때 실제와 예측의 차이계산을 위해 Loss함수가 계산된다. 전체 Loss가 계산되면 forward propagation이 완료되며 그 다음부터 도함수를 이용해 역전파를 진행한다.
🧐 LSTM (Long Short Term Memory)
🤫 LSTM 의 등장배경: RNN의 Gradient 소실, 폭주 문제 RNN은 은닉층을 거친 결과값을 재사용하기에 그로 인해 gradient 소실 및 폭주 문제가 발생할 수 있다.
📌 Exploding Gradient Problem - 구간이 기하급수적으로 빠르게 무한대로 이동하고 불안정한 프로세스로 해당값이 NaN이 된다.
📌 Vanishing Gradient Problem - 구간이 기하급수적으로 빠르게 0이 되어 장기간 학습이 어려워 진다. - 이에 대한 해결을 위해 다양한 방식의 접근이 시도되었는데, 다음과 같다. ∙ ReLU 활성화 함수 사용 ∙ Forget Gate를 이용한 LSTM 구조 ∙ weight matrix W를 orthogonal matrix로 초기화, 전체 training에 사용 (orthogonal은 explode되거나 vanish되지 않음)
🤫 LSTM이란?
아래구조처럼 입력 게이트(input gate), 삭제 게이트(forget gate), cell state, hidden unit으로 나눌 수 있다.
🧐 GRU (Gated Recurrent Unit)
🤫GRU GRU는 LSTM과 비슷한 원리로 작동하지만 조금 더 간소화된 방식으로 계산이 간편하다는 장점이 있다. 하지만 LSTM보다 학습능력이 다소 낮은면을 보인다.
LSTM과 다르게 GRU는 이전 시점에서 받는 벡터가 h하나이다. 또한 벡터 z가 입력과 삭제게이트를 모두 제어한다. GRU에는 출력게이트가 없는데, 즉 전체 상태 벡터가 매 시점 출력된다는 뜻이다.
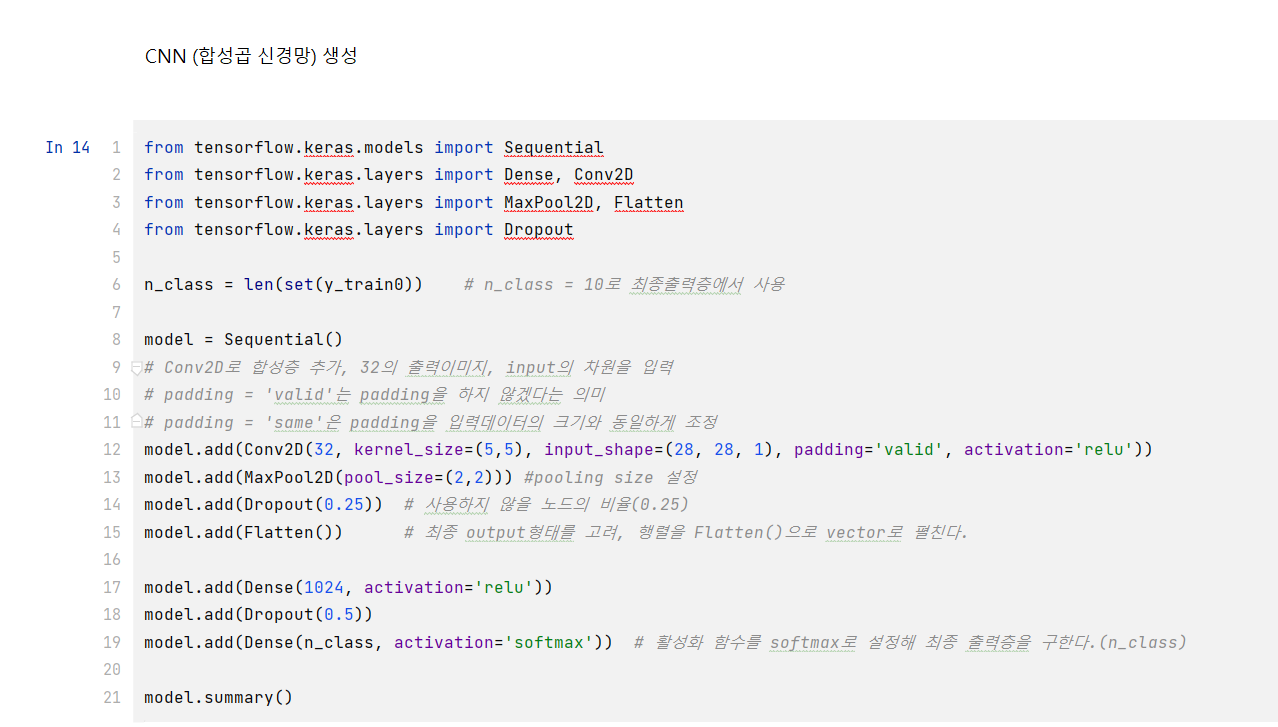
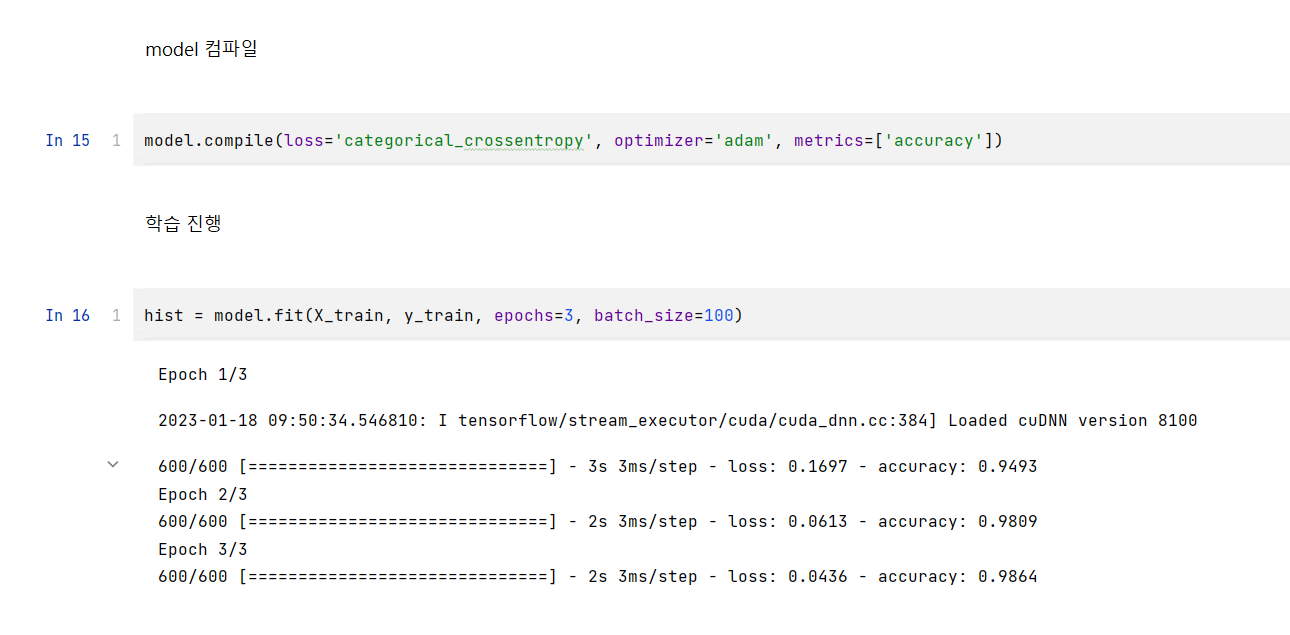
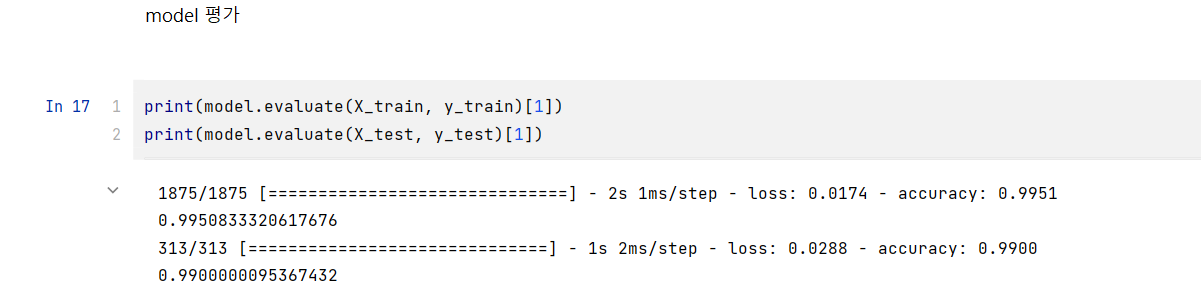
🤫 CNN, 합성곱 신경망이란? 여러 분야, 특히나 image classification에서 좋은 성능을 보여주는 방법이다. 이런 합성곱 신경망에서 합성곱의 연산은 정의 자체에 가중치를 flip하는 연산이기에 아래와 같은 수식으로 표현한다. i와 j시점에서 input x와 kernel(= weight)의 합성곱에 편향(bias)를 각 pixel에 더해 output y를 도출한다. 이때, 아래와 같은 연산식을 Cross-Correlation이라 부른다.
🤫 CNN이 등장하게 된 이유는 무엇일까? MLP vs CNN ▶ image classification에서 MLP보다 CNN이 더 선호된다.
1.MLP는 각 input(한 image의 pixel)에 대해 하나의 퍼셉트론만 사용하고 large한 image에 대해 weight가 급격하게 unmanageable해진다. 이는 너무 많은 parameter들이 fully-connected되어 있기 때문이다. 따라서 일반화를 위한 능력을 잃는, 과적합(overfitting)이 발생할 수 있다.
2. MLP는 input image와 shift된 image가 다르게 반응한다는 점이다. (translation invariant(불변)가 아니기 때문)
예를 들어 고양이 사진이 한 사진의 이미지 왼쪽 상단에 나타나고 다른 사진의 오른쪽 하단에 나타나면 MLP는 자체 수정을 시도하고 고양이가 이미지의 이 섹션에 항상 나타날 것이다.
즉, MLP는 이미지 처리에 사용하기에 가장 좋은 아이디어가 아니다. 주요 문제 중 하나는 이미지가 MLP로 flatten(matrix -> vector)될 때 공간 정보가 손실된다.
∴고양이가 어디에 나타나든 사진에서 고양이를 볼 수 있도록 image features(pixel)의 공간적 상관 관계(spatial correlation)를 활용할 방법이 필요.
∴ 이를 위한 해결책으로 등장한 것이 바로 CNN 이다!
좀 더 일반적으로, CNN은 공간적 상관관계가 있는 data에 잘 반응할 수 있다. 따라서 CNN은 input으로 image data를 포함하는 문제에 대한 prediction의 한 방법이다.
이런 CNN의 사용은 2차원 이상의 image의 내부적 표현에 대한 좋은 이점을 갖는다. 즉, image작업 시, 가변적인 구조의 data안에서의 position과 scale을 model이 배우기 쉽게 해준다.
🧐 Padding, Stride, Pooling
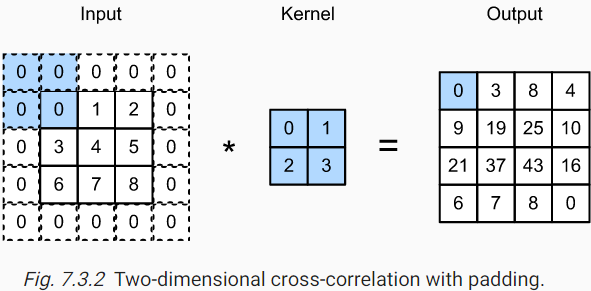
🤫 Padding 예를들어 4x4차원이 input에 2x2의 kernel로 합성곱을 하게되면 output 차원은 3x3으로 차원이 줄어든다. 이렇게 차원이 줄어드는 현상을 방지하기 위해서 padding이라는 방법을 사용한다. 위 사진처럼입력 데이터는 3x3이지만zero-padding을 통해 차원의 축소가 일어나지 않게 할 수 있다.
🤫 Stride 한 번의 합성곱연산 이후 다음 계산영역으로 이동을 해야하는데, 이때 얼마나 이동할 것인지 간격을 정하는 값이며 이때 output 데이터 행렬의 차원이 더 작아지는 것을 알 수 있다. 그렇다면, padding과 stride를 해도 output data의 크기를 미리 계산할 수는 없을까?
🤫 Pooling CNN에서 feature의 resolution을 줄일 때, 사용하는 방식으로 아래와 같이 작동한다.
그렇다면, 이쯤에서 드는 생각이 있을 것이다. Question? 왜 굳이? pooling을 사용하는거지? 그냥 convolution layer를 stride = 2로 줄여서 작동하면 같은작업이지 않나?
Answer!
convolution layer를 이용하여stride = 2로 줄이면학습 가능한 파라미터가 추가되므로 학습 가능한 방식으로 resolution을 줄이게 되나 그만큼 파라미터의 증가 및 연산량이 증가하게 됩니다.
반면pooling을 이용하여 resolution을 줄이게 되면 학습과 무관해지며 학습할 파라미터 없이 정해진 방식 (max, average)으로 resolution을 줄이게 되어 연산 및 학습량은 줄어든다. 다만convolution with stride방식보다 성능이 좋지 못하다고 알려져 있습니다. 따라서,layer를 줄여서 gradient 전파에 초점을 두려고 할 때 pooling을 사용하는게 도움이
🤫 Neural Network perceptron에서 단지 층이 여러개 늘어난 것 뿐이지만, XOR 문제처럼 하나의 perceptron으로 해결하기 어려웠던 문제를 해결할 수 있다. 다수의 뉴런을 사용해 만든 것을 인공신경망(artificial neural network)라 하며, 줄여서 신경망(neural network)라 한다. 이런 신경망은 아래와 같은 모양으로 되어있는데, 이때 은닉층(hidden layer)의 깊이가 깊은 것을 이용한 학습방법을 Deep Learning이라 한다.
신경망: 입력층에서 은닉층으로 값을 전달하는 함수는 vector-to-vector함수 딥러닝: 함수는 vector-to-scalar함수( ∵ 벡터를구성하는데이터값들이개별적으로자유롭게활동) input layer(입력층): input은 data의 feature로 node의 개수 = feature의 개수이다. output layter(출력층): node개수 = 분류하려는 class의 개수이며 이때, 각 클래스의 score 중 가장 높은값을 갖는 class를 최종적으로 선정한다.
🧐 back propagation (오차 역전파)
🤫 오차 역전파 (back propagation)
다층 퍼셉트론(multi-perceptron)에서 최적값을 찾아가는 과정은 오차역전파(back propagation)방법을 사용한다.
역전파라는 말처럼 역전파는 출력층-은닉층-입력층 순서대로 반대로 거슬러 올라가는 방법이다.
오차역전파를 통해 오차를 기반으로 가중치(weight)를 수정한 후 더 좋은 성능을 내도록 모델을 개선한다.
🤫 back propagation 과정
1) weight 초기화
2) forward propagation을 통한 output 계산
3) Cost function 정의, 1차 미분식 구하기. => 실제값 t에 대해, ([t-z]^2) / 2
4) back propagation을 통한 1차 미분값 구하기
5) 학습률(learning rate)설정 후 parameter(weight, bias) update
6) 2 ~ 6의 과정 반복
🧐 activation function (활성화 함수)
🤫활성화 함수 (activation function) 활성화 함수는 input, weight, bias로 계산되어 나온 값에 대해 해당 노드를 활성화 할 것인지를 결정하는 함수이다.
🤫 활성화 함수의 종류 계단 함수(step function): 0을 기점으로 출력값은 0과 1, 두가지 값만 갖는특징이 있다.
(다만 0에서 미분불가능이라는 단점이 존재)
부호 함수(sign function): 계단함수와 비슷하지만 0을 기점으로 -1, 0, 1 세 값을 갖는 특징이 있다.
Sigmoid function: 1/(1 + exp(-x)) 로 0과 1사이 값을 출력한다.
다만 단점이 존재하는데, 바로 vanishing gradient problem이다.
Vanishing gradient problem: 학습하는 과정에서 미분을 반복하면 gradient값이 점점 작아져 소실될 가능성이 있다.
0~1사이인 sigmoid함수를 변형한 함수로 tanh함수는 -1 ~ 1사이의 범위를 갖는다.
ReLU 함수 (Rectified Linear function):max(x, 0)로 앞선 함수들과 다르게 상한선이 없다는 특징이 있다.
Leaky ReLU 함수: a <= 1일 때, max(x, ax)로 보통 a는 0.01값을 갖는다.
항등함수(identity function, linear function): x로 입력값과 출력값이 동일하다.
주로 regression문제에서 최종 출력층에 사용되는 활성화 함수.
softmax function: exp(x) / Σ(exp(x))
주로 classification최종 출력층에 사용되는 활성화 함수.
다만 위의 식을 그대로 사용할 경우, overflow발생의 가능성 때문에 아래와 같이 사용한다.
exp(x + C) / Σ(exp(x + C))
이때, 상수 C는 일반적으로 입력값의 최댓값을 이용한다.
또한 softmax는 결과가 0~1사이이기에 이를 확률에 대응하여 해석할 수 있다.(입력이 크면 확률도 크다는 비례관계.)
즉, 어떤 값이 가장 크게 출력될 지 예측가능하다.
🧐 batch normalization
🤫 batch size란?
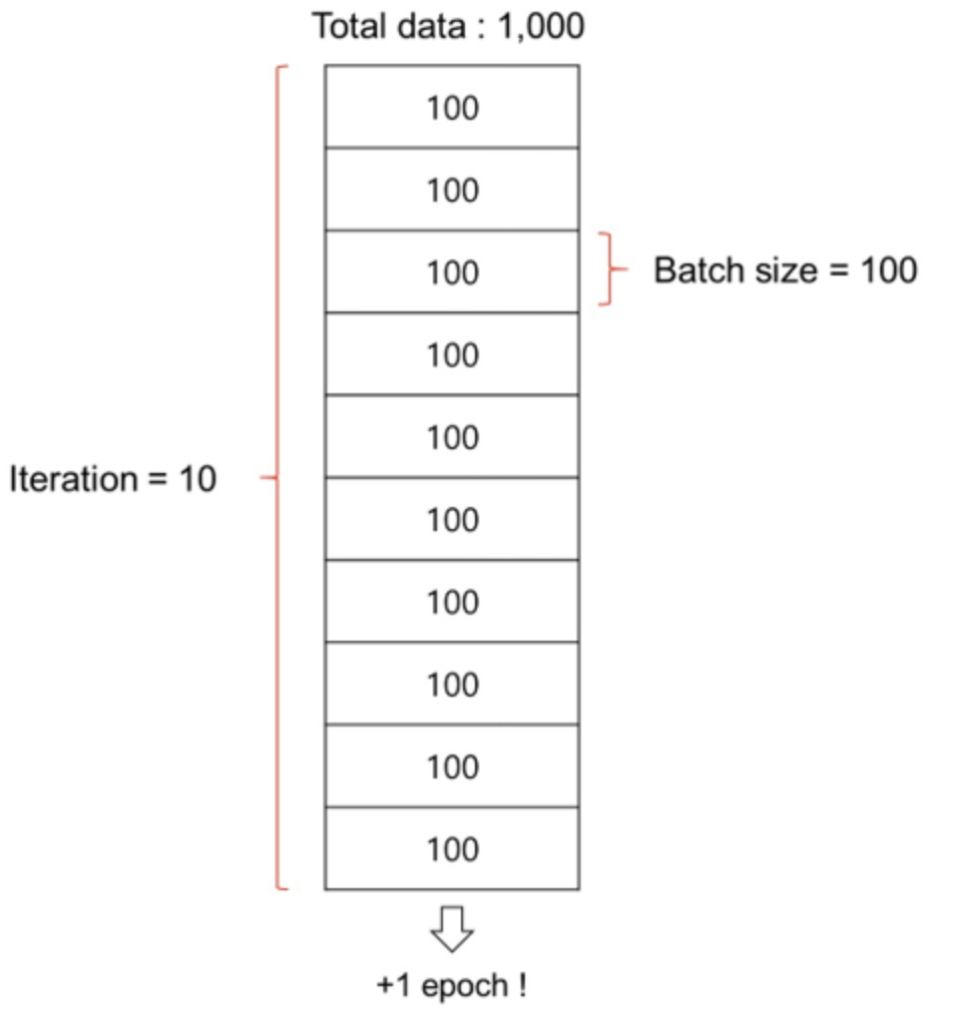
batch 크기는 모델 학습 중 parameter를 업데이트할 때 사용할 데이터 개수를 의미한다. 사람이 문제 풀이를 통해 학습해 나가는 과정을 예로 들면, batch 크기는 몇 문제를 한 번에 쭉 풀고 채점할지를 결정하는 것이다. 예를 들어, 총 100개의 문제가 있을 때, 20개씩 풀고 채점한다면 batch 크기는 20이다.
이를 이용해 딥러닝 모델은 batch 크기만큼 데이터를 활용해 모델이 예측한 값과 실제 정답 간의 오차(conf. 손실함수)를 계산하여 optimizer가 parameter를 업데이트합니다.
🤫batch normalization layer의 값의 분포를 변경하는 방법으로 평균과 분산을 고정시키는 방법이다. 이를 이용하면 gradient 소실문제를 줄여 학습 속도를 향상시킬 수 있다는 장점이 존재한다.
Mini-batch mean, variance를 이용해 정규화(normalize)시킨 후 평균 0, 분산 1의 분포를 따르게 만든다. N(0, 1^2)
이때, scale parameter γ와 shift parameter β를 이용해 정규화시킨 값을 Affine transformation을 하면 scale and shift가 가능하다.
🤫 normalization? standardization? Regularization?
Normalization
값의 범위(scale)를 0~1 사이의 값으로 바꾸는 것
학습 전에 scaling하는 것
머신러닝에서 scale이 큰 feature의 영향이 비대해지는 것을 방지
딥러닝에서 Local Minima에 빠질 위험 감소(학습 속도 향상)
scikit-learn에서 MinMaxScaler
Standardization
값의 범위(scale)를 평균 0, 분산 1이 되도록 변환
학습 전에 scaling하는 것
머신러닝에서 scale이 큰 feature의 영향이 비대해지는 것을 방지
딥러닝에서 Local Minima에 빠질 위험 감소(학습 속도 향상)
정규분포를 표준정규분포로 변환하는 것과 같음
Z-score(표준 점수)
-1 ~ 1 사이에 68%가 있고, -2 ~ 2 사이에 95%가 있고, -3 ~ 3 사이에 99%가 있음
-3 ~ 3의 범위를 벗어나면 outlier일 확률이 높음
표준화로 번역하기도 함
scikit-learn에서 StandardScaler
Regularization
weight를 조정하는데 규제(제약)를 거는 기법
Overfitting을 막기위해 사용함
L1 regularization, L2 regularizaion 등의 종류가 있음
L1: LASSO(라쏘), 마름모
L2: Lidge(릿지), 원
🧐 Drop Out
🤫 드롭 아웃 (Drop out)
신경망의 모든 노드를 사용하지 않는 방법으로 신경망에서 일부 노드를 일시적으로 제거하는 방법이다.
이때, 어떤 노드를 일시적으로 제거할 것인지는 무작위로 선택하는데, 이 방법은 연산량을 줄여 overfitting(과적합)을 방지할 수 있다.
🤫 Deep Neural Network 우리의 신경망은 임계치를 넘는 자극을 신호로 전달받고 그에 해당하는 반응을 하는데, 이처럼 수많은 퍼셉트론(perceptron)이 연결되어 연산결과를 주고 받으며 임계치(threshold)를 넘긴 값에 대해 신경망을 기반으로 학습하는 방법을 "딥러닝"이라 한다.
n, m = map(int, input().split())
num = list(map(int, input().split()))
prefix_sum = [0]
p_sum = 0
for i in num:
p_sum += i
prefix_sum.append(p_sum)
for _ in range(m):
i, j = map(int, input().split())
print(prefix_sum[j] - prefix_sum[i-1])
🧐 백준 11660(구간 합 구하기 _ 이차원 배열) Silver I
🤫 Algorithm
🤫solution_11660
n, m = map(int, input().split())
num = [list(map(int, input().split())) for i in range(n)]
S = [[0 for i in range(n + 1)] for i in range(n + 1)]
for i in range(n):
for j in range(n):
S[i + 1][j + 1] = (S[i][j + 1] + S[i + 1][j] - S[i][j]) + num[i][j]
for i in range(m):
x1, y1, x2, y2 = map(int, input().split())
print(S[x2][y2] - (S[x2][y1-1] + S[x1-1][y2]) + S[x1-1][y1-1])
🧐 백준 10986(구간 합 구하기) Gold III
부분 합 개념을 이용해서 풀 때, 부분 합을 계산한 배열을 i, j로 순차적으로 접근할 경우
O(n^2)으로 시간 초과가 발생하므로 다른 풀이 방법이 필요하다.
🤫 Algorithm
미리 구해둔 prefix sum에서의 부분합은 S[j] - S[i - 1]의 과정이다.
이때, S[j]와 S[i-1]이 각각 m으로 나눴을 때의 나머지가 동일하다면?
S[j] - S[i - 1] 연산 후 나머지는 0이 되기에 m으로 나눠 떨어진다.
결국 m으로 나눠떨어지는 부분합을 구하는 것은
나머지가 동일한 idx 중 임의로 nC2를 선택하는 것과 같으므로 다음 알고리즘을 거친다.
[1] [2] [3] [1] [2] -> [0] [1] [3] [6] [7] [9] -> [0] [1] [0] [0] [1] [0]
-> [0 : 4, 1 : 2] -> 6 + 1 -> 7
🤫solution_10986
import sys
input = sys.stdin.readline
n, m = map(int, input().split())
num_list = list(map(int, input().split()))
rest_list = [0 for _ in range(m)]
rest_list[0] = 1
prefix_sum = 0
for i in range(n):
prefix_sum += num_list[i]
rest = prefix_sum % m
# 나머지 값에 따라서 idx 정보 저장
rest_list[rest] += 1
cnt = 0
for i in rest_list:
cnt += i*(i - 1) // 2
print(cnt)
2개의 포인터를 이용해 알고리즘의 시간복잡도를 최적화하는 방법으로 간단한 알고리즘을 사용한다.
주로 n의 최댓값이 크게 잡혀있고 O(nlog n)의 시간복잡도로 해결이 힘들 때, O(n)의 시간복잡도로 구현해야 한다. 이때, 자주 사용되는 것이 바로 투 포인터 알고리즘이다.
투 포인터 알고리즘은 시작 인덱스와 종료 인덱스를 지정해 서로 조건에 따라 접근하도록 하는 것이다.
🧐슬라이딩 윈도우
슬라이딩 윈도우 알고리즘은 2개의 포인터로 범위를 지정한 후 범위(window)를 유지한 채로 이동(sliding)하며 문제를 해결하는 알고리즘이다.
투포인터 알고리즘과 매우 비슷하다.
🧐 백준 17609 (회문) Gold V
🤫solution_17609(시간초과)
string_list = [input() for _ in range(int(input()))]
def palindrome(string):
# 회문인 경우
if string == string[::-1]:
print(0)
# 회문이 아닌경우
else:
ans = 2
for i in range(len(string)):
new_string = string[:i] + string[i+1:]
if new_string == new_string[::-1]:
ans = 1
print(ans)
for i in string_list:
palindrome(i)
🤫solution_17609
# 유사 회문 판단 함수
def palindrome_like(string, left, right):
while left < right:
if string[left] == string[right]:
left += 1
right -= 1
else:
return False
return True
# 회문 함수
def palindrome(string, left, right):
while left < right:
if string[left] == string[right]:
left += 1
right -= 1
else:
pseudo1 = palindrome_like(string, left+1, right)
pseudo2 = palindrome_like(string, left, right-1)
if pseudo1 or pseudo2:
return 1
else:
return 2
return 0
for string in list([input() for _ in range(int(input()))]):
print(palindrome(string, 0, len(string) - 1))
🧐 백준 1253 (Good Number) Gold IV
🤫 Algorithm
# 해당 원소를 제외한 리스트에서 투 포인터(Two-Pointer)를 통해
# 두 원소의 합이 선택한 원소와 같은지 비교하는 방식으로 해결할 수 있다.
1. num 리스트를 정렬한다.
2. 0부터 N - 1 까지 반복문을 통해 특정 원소(num[i])를 선택하고, 해당 원소를 제외한 except_num 리스트를 생성
3. except_num 리스트에서 투 포인터를 통해 두 원소의 합(sum)이 num[i] 인지 비교한다.
t < num[i]이면 left를 증가
t > num[i]이면 right를 감소
4. 2, 3 과정을 반복한다.
🤫solution_1253
N = int(input())
num = list(map(int, input().split()))
num.sort()
cnt = 0
for i in range(N):
except_num = num[:i] + num[i + 1:]
left, right = 0, len(except_num) - 1
while left < right:
sum = except_num[left] + except_num[right]
if sum == num[i]:
cnt += 1
break
if sum < num[i]:
left += 1 # t 를 증가시켜야 하므로 left 증가
else:
right -= 1 # t 를 감소시켜야 하므로 right 감소
print(cnt)
🧐 백준 11003 (최솟값 찾기, 슬라이딩 윈도우 이용) Platinum V
🤫Algorithm
특정 새로운 원소가 추가될 때 이 원소보다 큰 값은 유지될 필요가 없다.
(인덱스로 볼 때에도 새로 추가되는 원소가 가장 오래 남기 때문.)
덱으로 구성하고 덱의 앞에 항상 최소값이 오도록하기 위해
삽입은 append를 이용해 값과 인덱스로 진행한다.
1. 삽입하기전에 덱을 뒤에서 while로 삽입하려는 요소보다 큰값을 모두 제거.
(삽입한다면 덱은 항상 오름차순으로 정렬된 상태를 자동적으로 유지할 것이다.)
(이는 정렬로 인한 시간복잡도를 없애줘 시간초과가 발생하지 않게 할 수 있다.)
2. 추가적으로 슬라이딩 범위를 벗어난 요소들을 생각하면 아래와 같다.
삽입하기전에 덱을 앞에서부터 보며 인덱스 범위가 벗어난 요소들을 빼준다.
i) 뒤에서부터 확인하며 삽입하려는 요소보다 큰 값들을 제거
ii) 앞에서부터 보며 슬라이딩 범위를 벗어난 요소들을 제거
iii) 현재 요소 삽입
모든 연산이 O(1)으로 전체 배열을 확인하는데 O(n)으로 해결가능하다.
🤫solution_11003
from collections import deque
N, L = map(int, input().split())
A = list(map(int, input().split()))
dq = deque()
for i in range(N):
first, end = i - L, i
# 현재 들어온 값보다 큰 값들을 제거하여 시간복잡도를 줄임
while dq and dq[-1][0] > A[end]: # 덱의 마지막 위치에서 현재값보다 큰 값 제거
dq.pop()
dq.append((A[end], end)) # A, A_idx, 마지막 위치에 현재값 저장
if dq[0][1] <= first:
dq.popleft()
print(dq[0][0], end = " ")