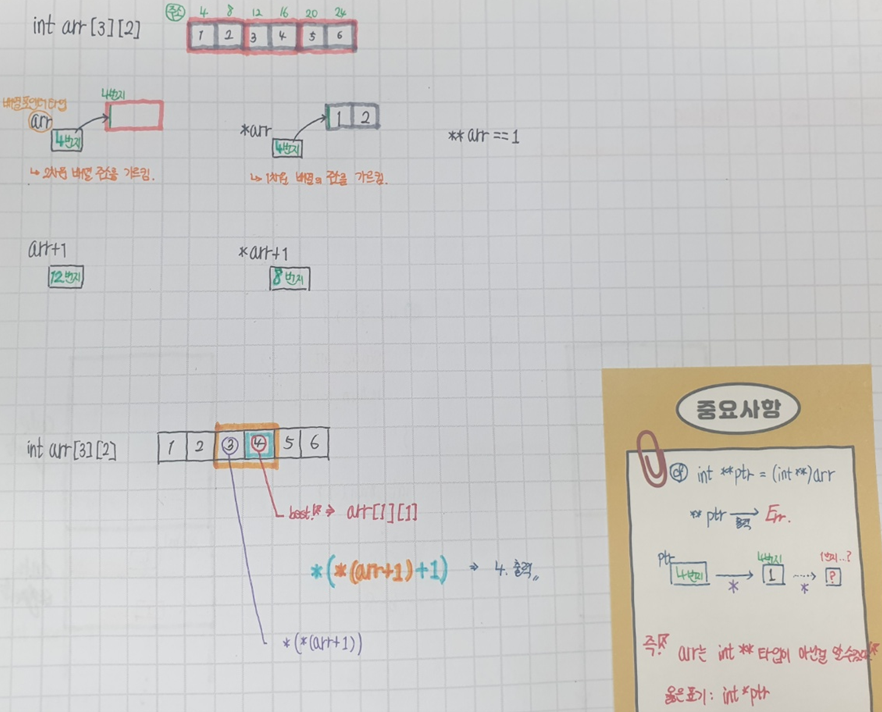
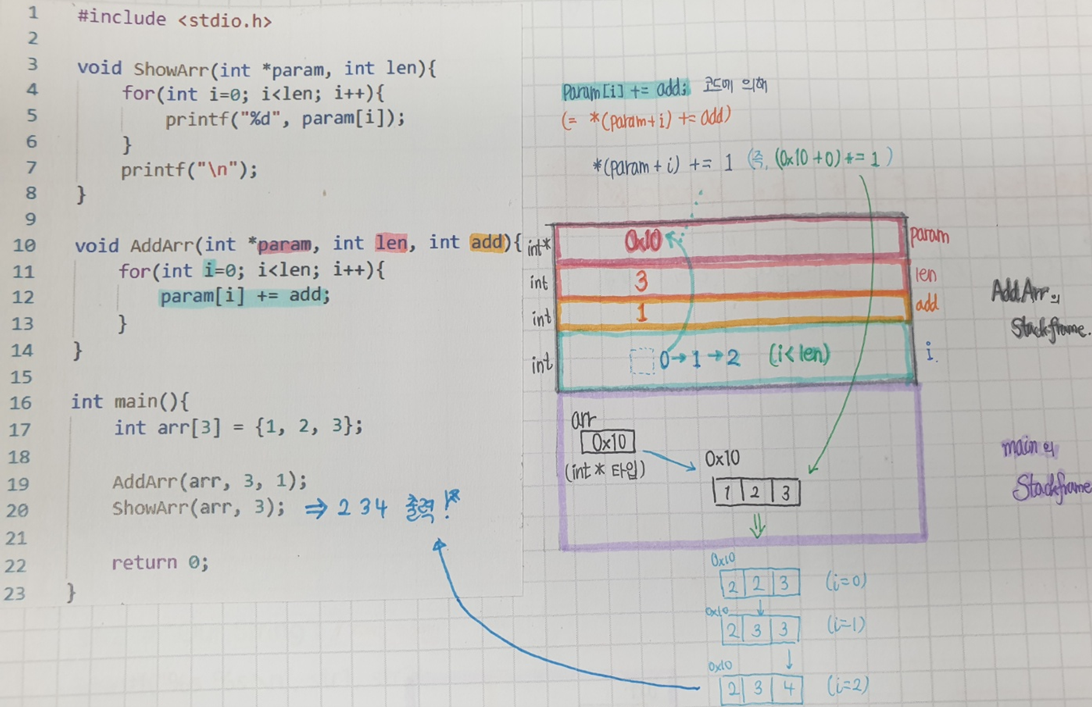
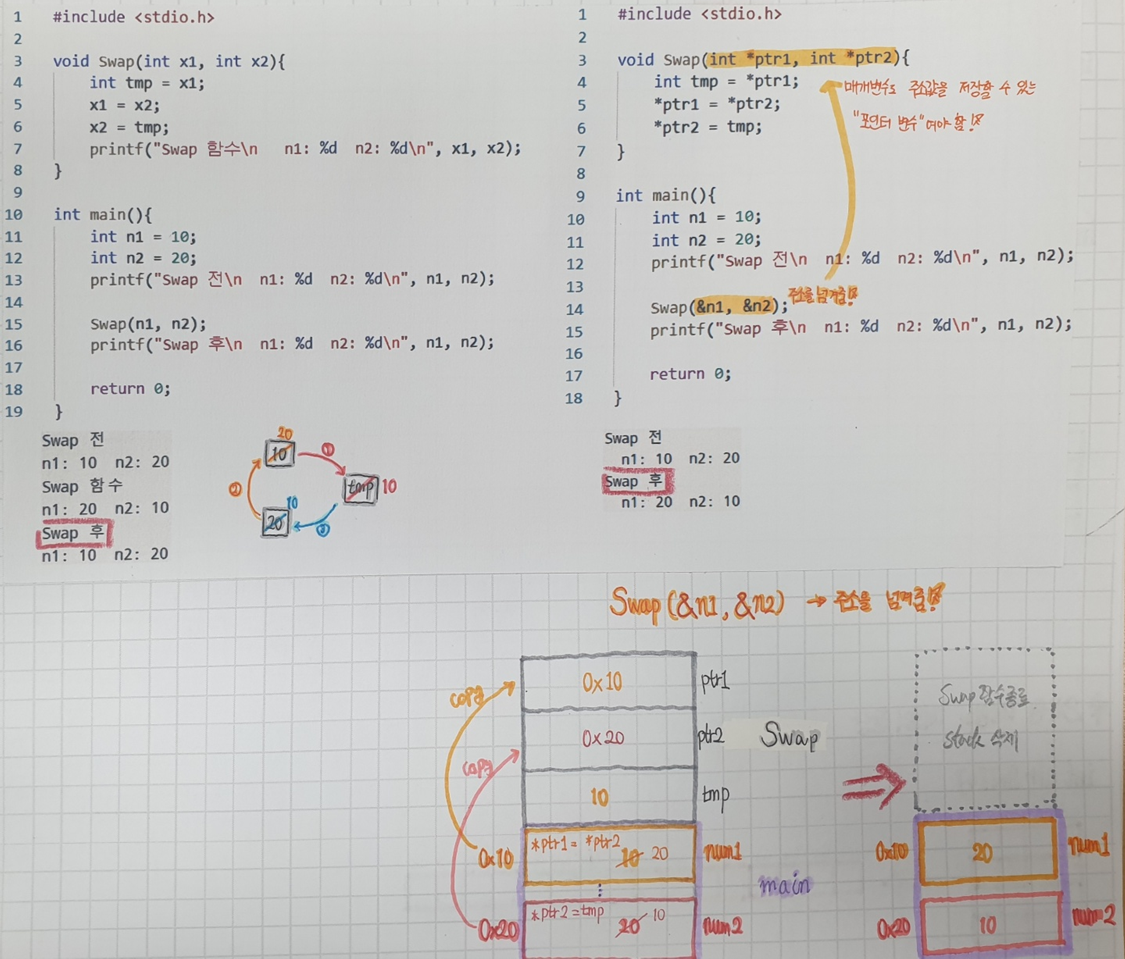
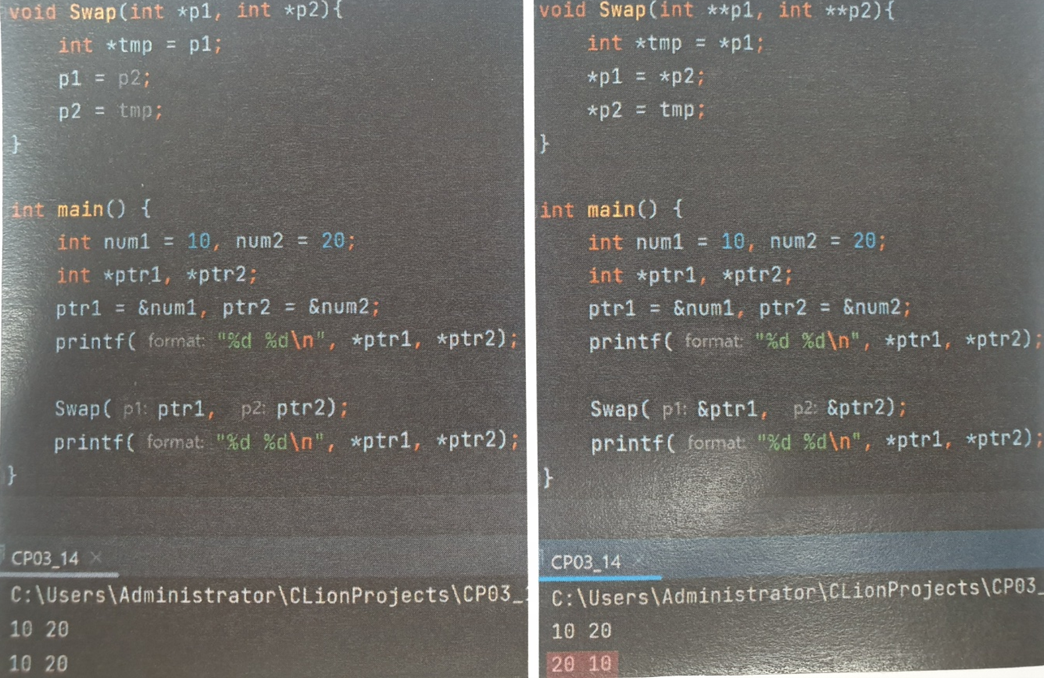
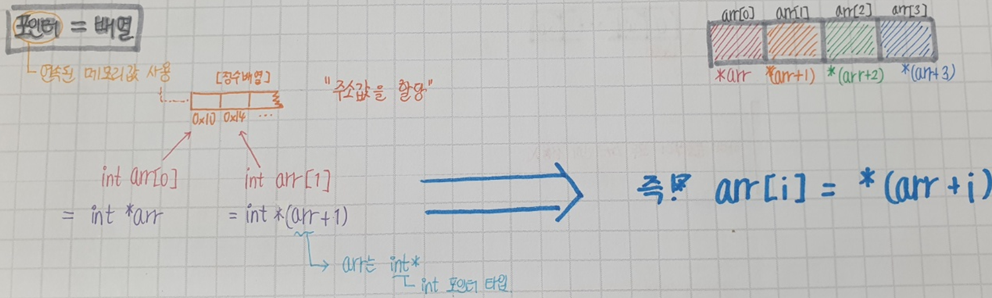
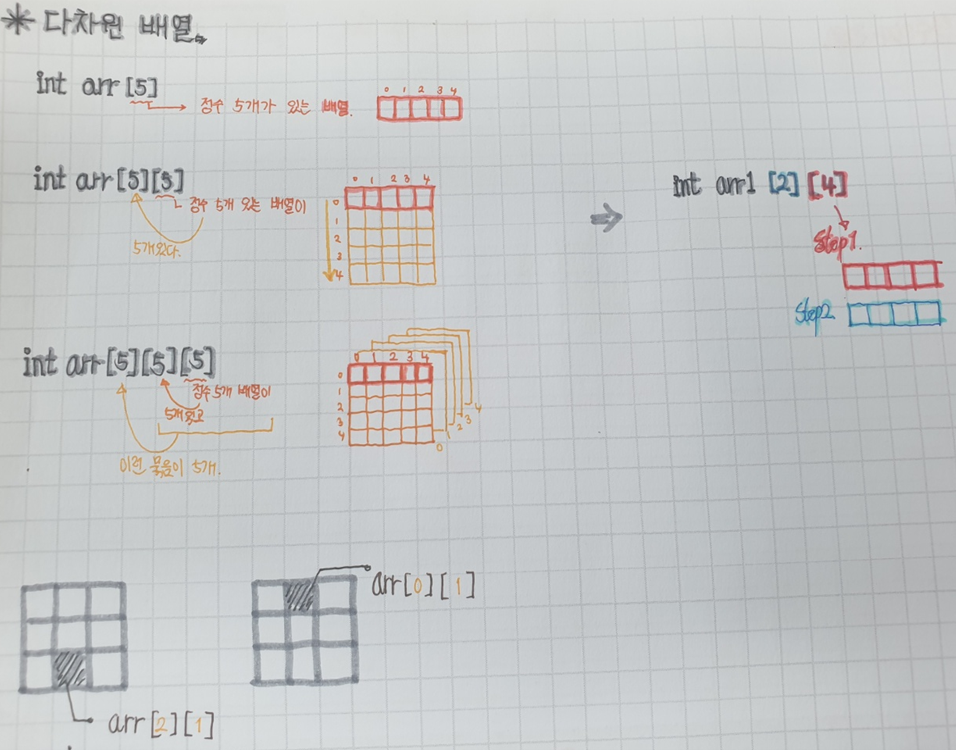
int arr[n];
for (int i = 0; i < n; i++) {
scanf("%d", &arr[i]);
}
Ex. 배열에 담기 (feat. 약수구하기)
#include <stdio.h>
int main(){
int arr[100];
int cnt = 0, N = 0;
scanf("%d", &N);
for (int i = 1; i <= N; i++) {
if (N % i == 0){
arr[++cnt] = i; //cnt++; //arr[cnt] = i;
}
}
for (int i = 1; i <= cnt; i++) {
printf("%d ", arr[i]);
}
}
※ 배열을 이용한 문자열 변수 표현
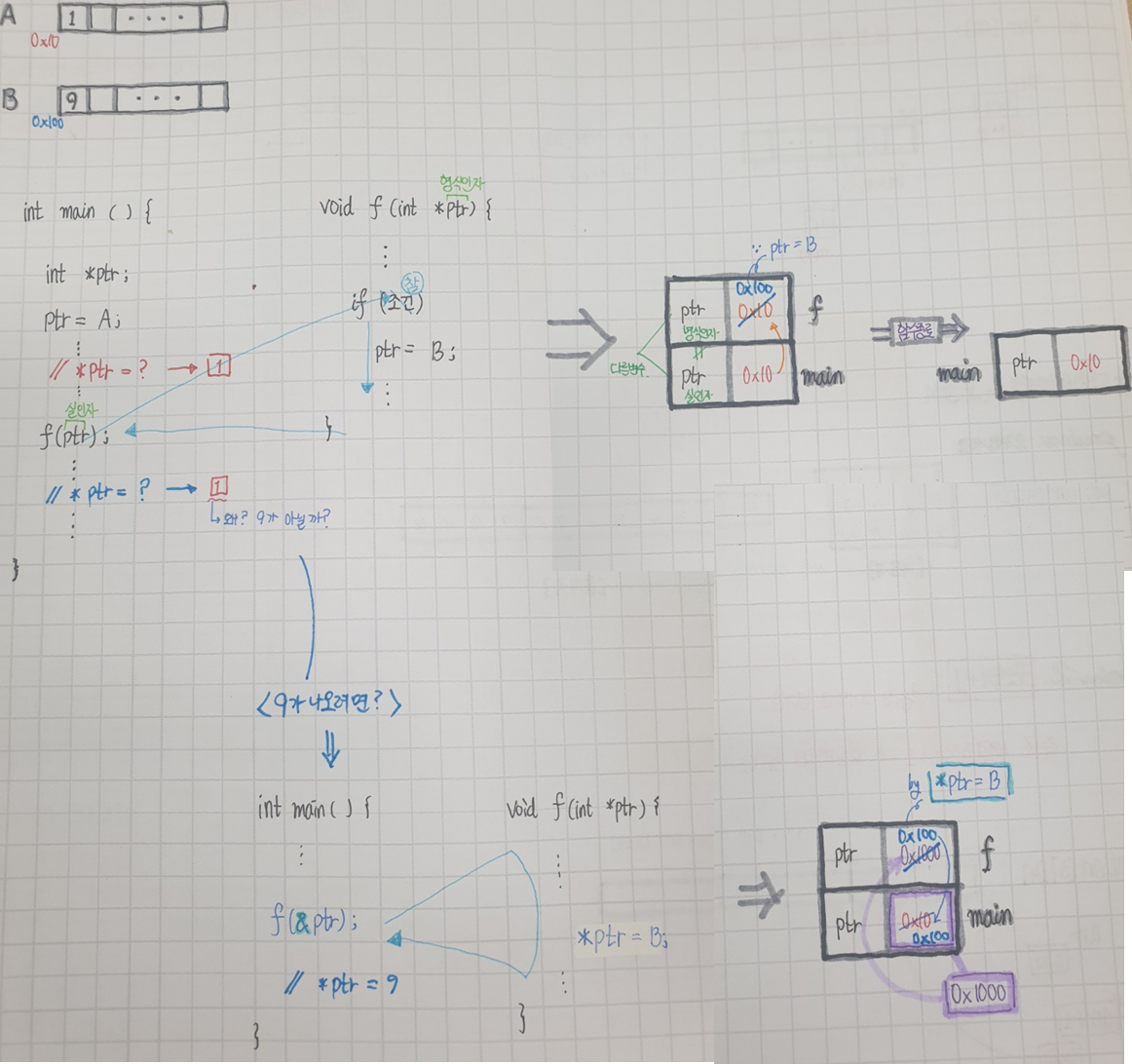
※ 포인터
포인터는 주소를 "꺼내는" 연산이기에 포인터는 값과 그 값의 type을 알아야 한다!
- * 연산자를 붙이면 주소를 따라가게 되며 &연산자는 주소를 꺼내는 연산자이다.
§ 직접접근과 간접접근을 이용한 값 변화
int a = 10;
int *ptr = &a;
a++; // 직접접근
*ptr = 20; // 간접접근
보통 if문 대신 사용하며 case를 나눌 필요가 있을 때, if-else를 여러번 쓰기 힘들 때 사용한다.
switch (n) // n은 정수형 변수로 전달되는 인자정보, n에 지정된 값에 따라 case 영역 실행
{
case 'M':
// 조건 입력
break;
case 2:
// 조건입력
break;
default:
// else문과 비슷한 역할
}
이때, break를 하지 않으면 다음 break가 있는 case문까지 같이 실행되기에 적는 것이 좋다.
§ break와 continue
break: 가장 가까운 반복문을 탈출한다.
continue: 실행위치와 상관없이 반복문의 조건검사위치로 이동한다.
이때, 이후부터는 continue는 생략하고 재실행한다.
※ while 문 vs for 문
보통 while문은 특정 종료조건이 나타나기 전까지의 지속적인 실행을 위해,
보통 for문은 반복횟수가 정해져 있는 경우에 많이 사용된다.
※ 비트 연산자
메모리에 할당된 정수값을 bit단위로 논리연산을 실행하기 위해 사용한다.
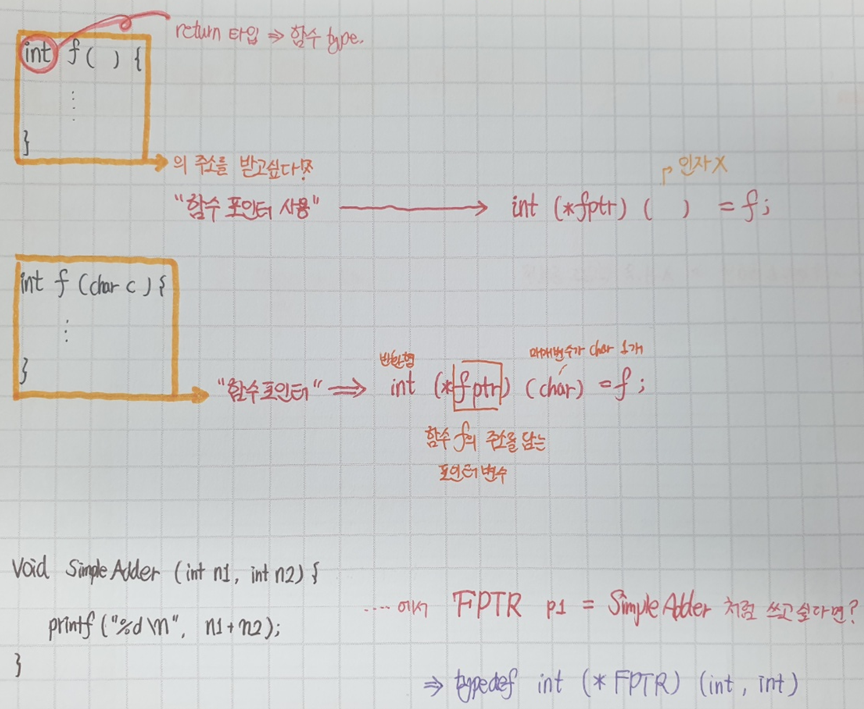
※ 함수 선언
[함수 return 타입] [함수 이름] (인자) {
/*
*
*/
}
인자 (argument): 함수 호출 시 전달되는 "값"
매개변수(parameter): 그런 인자를 받는 "변수"
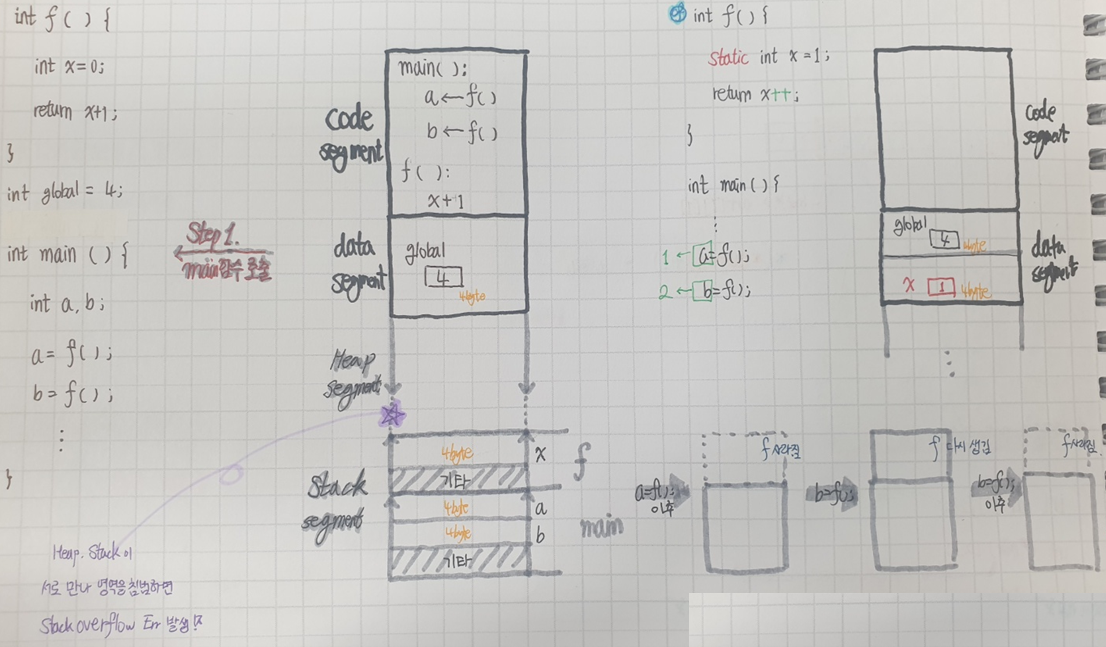
※ 지역변수와 전역변수, static과 block scope
지역변수(local variable): 중괄호에 의해 형성되는 영역안에 존재, "스택"이라는 메모리 영역에 할당
전역변수(global variable): 초기화를 하지 않으면 0으로 초기화되며 많이 사용하면 효율이 떨어진다.
§ 지역변수와 Block Scope
특정함수, 명령문의 블록안에 선언된 변수는 블록범위(Block Scope)밖에서는 사용이 불가능하다!
int a = 1;
{
a = 2; // a는 2로 초기화 됨
}
{
int a = 5; // 앞선 a와는 전혀 다른 a
// Block scope가 끝나면 사라짐
}
{
a++; // 여기까지 a값은 2, 아래줄 실행 시 a=3으로 증가
}
printf("%d", a); // 3 출력
§ static: "한 함수 내"에서 "지역변수의 전역변수화"를 해주는 tool
선언된 함수내에서만 접근 가능 (지역변수의 특징)
1회만 초기화, 종료전까지 메모리 공간에 저장 (전역변수 특징)
★ 전역변수와 달리 Block Scope 내부에서만 접근 가능
1972년, 벨 연구소의 데니스 리치가 만든 범용 프로그래밍 언어로 세계적으로 많이 쓰이는 프로그래밍 언어중 하나이다.
[사용분야]
- 운영체제 및 디바이스 드라이버
- 마이크로 컨트롤러
- 임베디드 시스템
- 암호학
- CPython 등의 프로그래밍 언어 인터프리터
- 매우 빠른 계산속도가 필요한 프로그램, 라이브러리의 구성
위의 예시를 보면 알 수 있듯이 C언어로 짜여진 코드는 속도가 매우 빠르고 바이널 크기도 작아 속도가 매우 빠르다.
따라서 정밀기계 등의 적은 메모리공간에서도 작동할 수 있거나 시시각각 빠른 연산이 필요할 때 많이 사용된다.
하드웨어나 컴퓨터 아키텍처를 배우게 된다면, C언어의 특징은 오히려 장점이 된다. Java나 Python 같은 언어들은 일반적인 상황에서 생산성을 높이기는 좋지만 특정한 상황에서 속도를 높이기는 어렵다. 일반적인 개발을 하려면 많은 상황을 처리할 수 있도록 강력하고 복잡하게 만들어야 하기 때문이다.
따라서 고성능이 필요한 특정 목적이 필요할 경우 언어에서 쌓은 추상화의 장벽을 뚫고 저수준(low level) 개념을 이용할 필요가 있는데, 이에 관한 개념을 제대로 이해하려면 처음부터 OS와 기계 제어를 위해 태어난 C언어를 사용하는 것이 가장 효과적이다. 다시 말해, C언어를 공부한다는 말은 곧 하드웨어를 공부한다는 말과 같다고 할 수 있다.
특히나 다른 언어에 비해 메모리관리를 할 수 있어서 (java 등의 언어는 garbage collector가 자동으로 메모리 누수(memory leak)을 잡아준다.) 메모리 누수를 모두 잡는다는 가정하에 매우 뛰어난 메모리 관리효과를 기대할 수 있다.
물론 이는 단점이 될 수도 있지만 말이다.
단점은 문자와 문자열, 포인터와 배열의 혼동과 범위를 넘어선 배열접근(buffer overflow) 등을 꼽을 수 있다.
하지만 이런 여러 단점들에도 C언어는 50여년이 훨씬 지난 지금에도 여전히 자리를 굳건히 지키고 있으니 배워보는것은 추천이 아니라 필수라 생각한다.