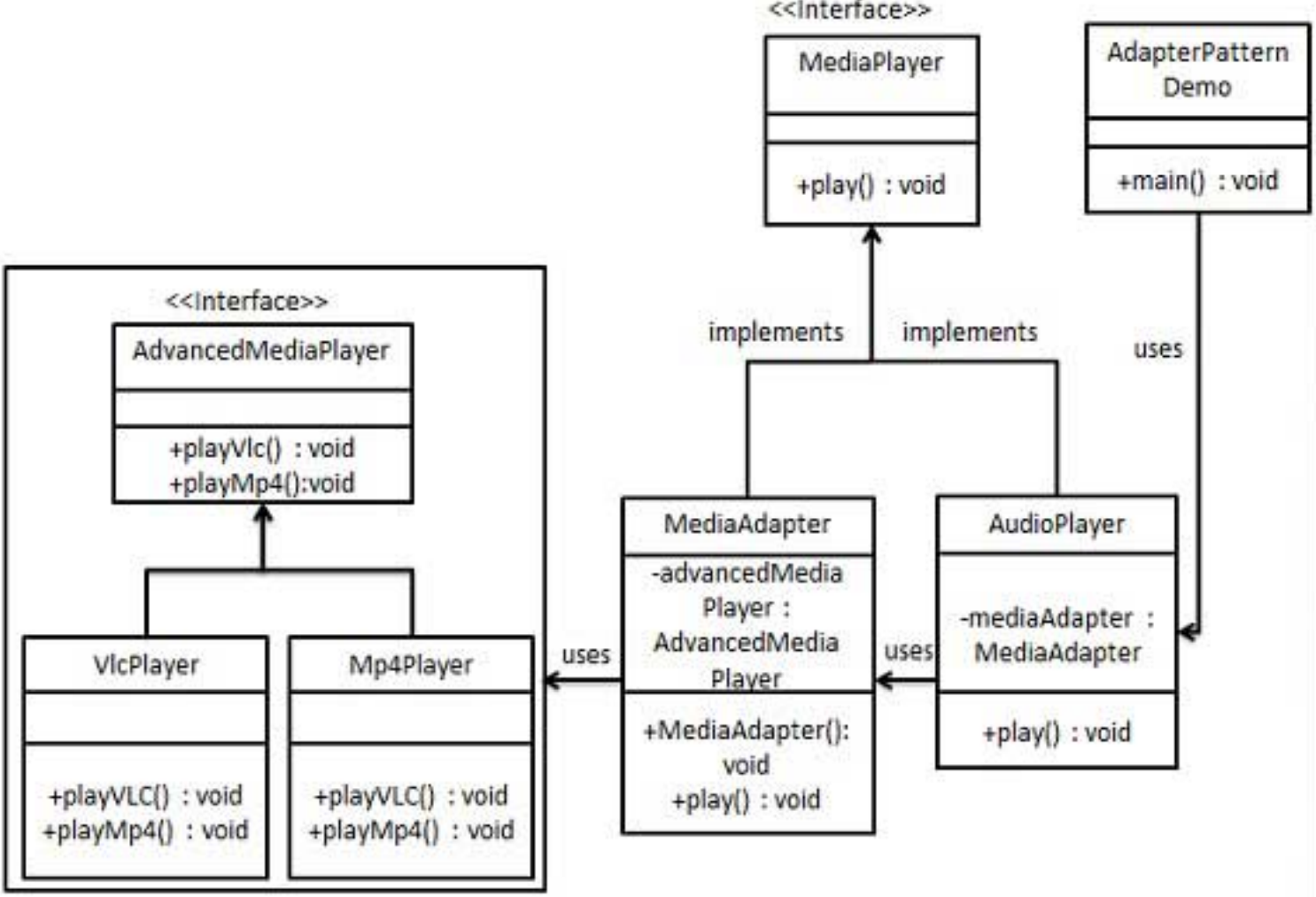
※ 리스트
리스트는 다른 언어의 배열과 같은 역할을 하며 다음과 같이 사용한다.
리스트형 변수 = [요소1, 요소2, ... ]
a = [1, 2, ['a', 'b', ['Life', 'is']]]
print(a[-1][-1][0])
print(a[2][2][0])
#--------출력--------#
# 둘 다 Life가 출력됨
※ 리스트 슬라이싱(slicing)
문자열 슬라이싱과 동일한 방법으로 진행된다.
a = [1, 2, 3, 4, 5]
print(a[1:3]) #출력: [2, 3]
※ 리스트 연산
§ 리스트 덧셈
a = [1, 2, 3]
b = [4, 5, 6]
print(a+b)
#--------출력--------#
[1, 2, 3, 4, 5, 6]
리스트는 같은 자료형의 집합이기에 다른 리스트간의 덧셈을 위해서는 형변환이 필요하다.
이때, str함수는 정수,실수를 문자열형태로 바꿔주는 내장함수이다.
a = [1, 2, 3]
print(str(a[2]) + "hi") # 3hi
§ 리스트 반복
a = [1, 2, 3]
print(a*3)
#--------출력--------#
[1, 2, 3, 1, 2, 3, 1, 2, 3]
§ 리스트 길이(len)
a = [1, 2, 3]
print(len(a)) # 3출력
§ 리스트 수정과 삭제(del)
a = [1, 2, 3]
a[2]=4
print(a) #출력: [1, 2, 4]
del a[1]
print(a) #출력: [1, 4]
arr = [1,2,3,4,5]
del arr[2:]
print(arr) #출력: [1, 2]
§ 리스트 복사
a = [1,2,3]
b = a
print(id(a))
print(id(b))
#-----출력-----#
2423373358208
2423373358208a와 b의 값이 동일함을 알 수 있는데, 이를 아래와 같이 알 수 있다.
a = [1,2,3]
b = a
print(a is b) # True따라서 a객체와 b객체가 동일한 주소값을 갖고 있음을 알 수 있기에
아래와 같은 양상이 일어날 수 있다.
a = [1,2,3]
b = a
a[1] = 4
print(a) # [1, 4, 3]
print(b) # [1, 4, 3]그렇다면 a값을 가져오지만 a와 다른 주소를 가리키도록 할 수는 없을까?
1. slicing 이용
a = [1,2,3]
b = a[:]
a[1] = 4
print(a) # [1, 4, 3]
print(b) # [1, 2, 3]2. copy()함수나 copy를 import하여 사용
a = [1,2,3]
b = a.copy()
a[1] = 4
print(a) # [1, 4, 3]
print(b) # [1, 2, 3]
from copy import copy
a = [1,2,3]
b = copy(a)
a[1] = 4
print(a) # [1, 4, 3]
print(b) # [1, 2, 3]
※ 리스트 관련 함수(append, sort, reverse, index, insert, remove, pop, count, extend)
§ 리스트 요소 추가 (append)
a = [1, 2, 3]
a.append(4)
print(a) # [1, 2, 3, 4] 출력
a.append([5, 6])
print(a) # [1, 2, 3, 4, [5, 6]] 출력
§ 리스트 정렬과 뒤집기 (sort ,reverse)
a = [1, 4, 3, 2]
a.sort()
print(a) # [1, 2, 3, 4] 출력a = [1, 4, 3, 2]
a.reverse()
print(a) # [2, 3, 4, 1] 출력
§ 리스트 위치반환 (index)
a = [1, 4, 3, 2]
print(a.index(4)) # 1출력
§ 리스트 요소 삽입 ( insert(i, x) )
insert(i, x)는 i번째에 x를 삽입하는 함수이다.
a = [1, 4, 3, 2]
a.insert(4, 5)
print(a) # [1, 4, 3, 2, 5] 출력
§ 리스트 요소 삭제 (remove)
첫 번째로 나오는 값을 삭제
a = [1, 2, 3, 1, 2, 3]
a.remove(2)
print(a) # [1, 3, 1, 2, 3] 출력
§ 리스트 요소 끄집어내기 (pop)
리스트 마지막 값을 pop(출력 후 삭제)
pop(i)로 i번째 index를 출력 후 삭제
a = [1, 2, 3, 1, 2, 3]
a.pop()
print(a) # [1, 2, 3, 1, 2] 출력
print(a.pop(2)) # 3출력
print(a) # [1, 2, 1, 2] 출력
§ 리스트에 포함된 요소x 개수 세기 ( count (x) )
a = [1, 2, 3, 1, 1, 1]
print(a.count(1)) # 4출력
§ 리스트 확장 (extend(리스트))
a.extend(x)에서는 x값은 리스트만 올 수 있으며 원래 리스트 a에 x를 더한다.
a = [1, 2, 3]
b = [4, 5]
a.extend(b)
a.extend([6, 7])
print(a) # [1, 2, 3, 4, 5, 6, 7] 출력
※ 튜플
리스트와 몇가지를 제외하면 거의 비슷하다.
<리스트와 다른점>
- 리스트는 [ ]이고 튜플은 ( )이며 (생략가능) 한 개의 요소만 가질 때는 쉼표가 필요하다.
- 리스트는 값의 생성, 삭제, 수정이 가능
- 튜플은 위와 같은 값의 변경이 불가능하다.
따라서 이런 값의 불변성 때문에 평균적으로는 리스트를 더 많이 사용한다.
리스트형 변수 = [요소1, 요소2, ... ]
a = [1, 2, ['a', 'b', ['Life', 'is']]]
print(a[-1][-1][0])
print(a[2][2][0])
#--------출력--------#
# 둘 다 Life가 출력됨
※ 튜플의 인덱싱과 슬라이싱(slicing)
a = (1, 2, 'a', 'b')
print(a[0]) # 1출력
print(a[0:3]) # (1, 2, 'a') 출력
※ 튜플의 덧셈, 곱셈, 길이구하기
t1 = (1, 2, 'a', 'b')
t2 = (3, 4)
print(t1+t2) # (1, 2, 'a', 'b', 3, 4)
print(t2 * 3) # (3, 4, 3, 4, 3, 4)
print(len(t1)) # 4 출력
'A.I > Python' 카테고리의 다른 글
| self.python(6). 모듈,패키지와 라이브러리, 내장함수 (2) | 2022.11.18 |
|---|---|
| self.python(5). 함수와 클래스 (0) | 2022.11.18 |
| self.python(4). 제어문 (if, while, for문) (0) | 2022.11.18 |
| self.python(3). 딕셔너리와 집합 자료형 (0) | 2022.11.18 |
| self.python(1).python 입력, 문법과 문자열 자료형 (4) | 2022.11.17 |