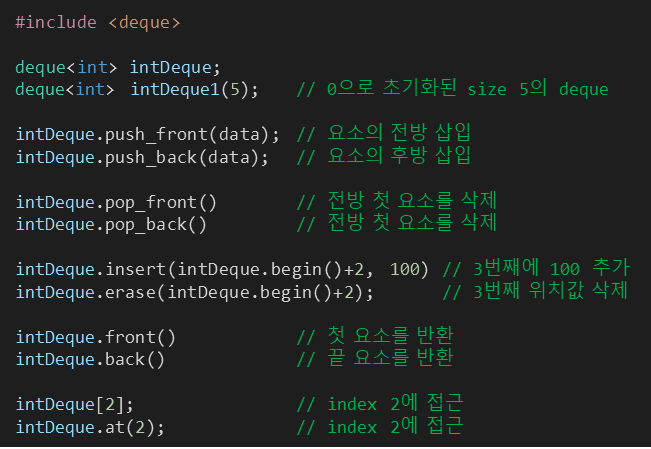
※vector(std::vector) _가변배열 / 가장 기본이 되는 컨테이너 (★★★★★)
#include <vector>
using namespace std;
vector<자료형> 변수명(숫자) //숫자만큼 벡터 생성 후 0으로 초기화
vector<자료형> 변수명(숫자, 변수1); //숫자만큼 벡터 생성 후 변수1으로 모든 원소 초기화
vector<자료형> 변수명{숫자, 변수1, 변수2, 변수3, ...}; // 벡터 생성 후 오른쪽 변수 값으로 초기화
vector<자료형> 변수명[]={ {변수1, 변수2}, {변수3, 변수4}, ...} //2차원 벡터생성 (열은 고정, 행 가변)
vector<vector <자료형>> 변수명 //2차원 벡터생성 (열, 행 가변)
ex);
vector<int> vec1; // 크기가 0인 벡터 선언
vector<int> vec2(10); // 크기가 10인 벡터 선언
vector<int> vec3(10, 3); // 크기가 10이고 모든 원소가 3으로 초기화된 벡터
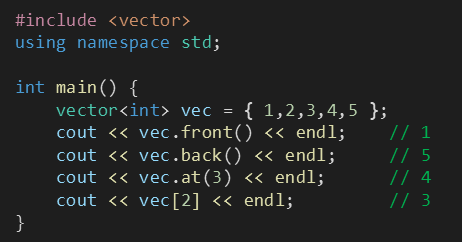
vector<int> vec4 = { 1,2,3,4,5 }; // 크기가 지정한 초기값으로 이루어진 벡터
vector<int> vec5[] = { {1,2},{3,4} }; // 벡터 배열 생성(행은 가변인지만, 열은 고정)
vector<vector<int>> vec6; // 2차원 벡터 생성(행과 열 모두 가변)
- set은 연관 컨테이너로 삽입, 삭제, 검색의 시간복잡도가O(logn) 인 Binary Search Tree로 구현되어 있다.
- key라는 원소들의 "집합"으로 key값은 중복되지 않는다!
- insert()를 통한 자동적으로 오름차순 정렬이 가능하다.
∴중복을 피하면서 정렬까지 사용할 때 매우 유용하다!
insert(k): 원소 k 삽입 begin(): 맨 첫번째 원소를 가리키는 iterator를 반환 end():맨 마지막 원소를 가리키는 iterator를 반환 find(k): 원소 k를 가리키는 iterator를 반환 size(): set의 원소 수 empty():비어있는지 확인
※algorithm
※ STL 알고리즘의 분류
find()는 2개의 입력 반복자로 지정된 범위에서 특정 값을 가지는 첫 번째 요소를 가리키는 입력 반복자를 반환
for_each()는 2개의 입력 반복자로 지정된 범위의 모든 요소를 함수 객체에 대입한 후, 대입한 함수 객체를 반환
copy()는 2개의 입력 반복자로 지정된 범위의 모든 요소를 출력 반복자가 가리키는 위치에 복사
swap()은 2개의 참조가 가리키는 위치의 값을 서로 교환
transform()은 2개의 입력 반복자로 지정된 범위의 모든 요소를 함수 객체에 대입후, 출력 반복자가 가리키는 위치에 복사
sort()는 2개의 임의 접근 반복자로 지정된 범위의 모든 요소를 비교, 오름차순정렬.
stable_sort()는 2개의 임의 접근 반복자로 지정된 범위의 모든 요소를 비교, 값이 같은 요소들의 상대적인 순서는 유지, 오름차순으로 정렬합니다.
binary_sort()는 정렬되어있는 경우(오름차순)에 한해서 탐색효율이 매우 좋고 적은 시간에 소요된다.
accumulate()는 두 개의 입력 반복자로 지정된 범위의 모든 요소의 합을 반환합니다.
※ 벡터의 오름차순과 내림차순 정렬 (feat. greater<int> 키워드)
§ sort() 함수 형식
단, custom_func()은 0 또는 1이 나오도록 해야해서 보통 bool형 함수를 많이 넣는다.
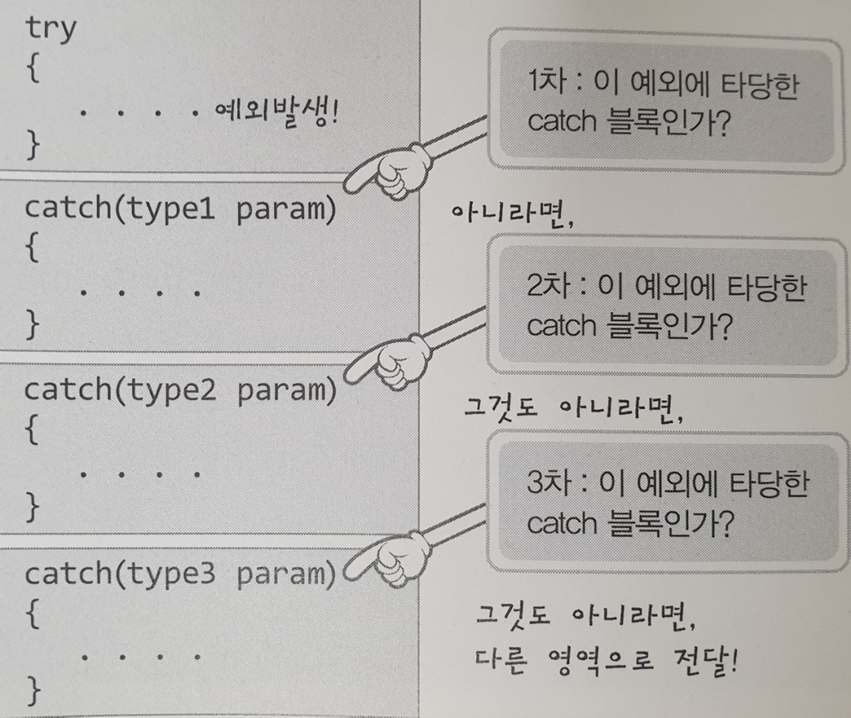
다음과 같이 객체를 throw할 수 있는데, nested block 즉, try{ }가 종료가 되었으므로
Animal a를 통해 만들어진 객체 a는 소멸자에 의해 소멸하게 된다.
Q. 그렇다면 왜 출력문에서 catch문 뒤에 소멸자가 한 번 더 출력된 것일까?
A. 그건 바로 catch(Animal& a)에서 생성자가 한 번 더 생성되었다는 것의 반증이 될 것이다.
생성자는 처음 객체생성되었을 때, 초기화를 위해 딱 한번만 호출된다는 것이 기본 개념이고, 핵심이기 때문이다.
따라서 catch 블록이 종료된 이후 Animal& a를 통해 생성된 객체를 다시 소멸자가 소멸해줘서 소멸자가 두번 출력된 것!
※ Exception 클래스 (예외 클래스)
Exception 클래스: 예외처리를 위해 exception 헤더에서 제공하는 클래스 (표준 라이브러리인 std namespace에 존재)
이런 예외클래스도 클래스이기에 상속은 물론 다형성, 생성자와 연산자에도 적용 가능하다.
§ what()
what은 exception 클래스에서 하나의 문자열 포인터를 반환하는 가상멤버함수이다.
what()은 exception 클래스에서는 아무 의미가 없지만 파생클래스에서 원하는 문자열을 출력할 수 있게 재정의 해준다!
#include <iostream>
#include <exception>
#include <string>
using namespace std;
class NewException : public exception{ //새로운 Exception NewException은 exception클래스를 상속받음
public:
const char* what() const noexcept override{ // what 함수의 오버라이딩 진행
return "NewException";
}
};
int main(){
try{
string str;
str.resize(-100);
}
catch (exception& e){
try {
throw NewException(); // 예외 발생시 새로운 Exception throw
}
catch (const NewException& newException){
cout << "My exception is " << newException.what() << endl; // NewException의 what()에서 전달받은 문자열 출력
}
}
}
§ 표준 Exception 클래스
#include <exception>는 exception 클래스로부터 파생된 다양한 표준 exception 클래스를 정의하고 있다.
[가장 기초클래스가 되는 2개의 클래스, logic과 runtime]
logic_error 클래스는 일반적인 논리에 관한 오류들을 처리
runtime_error 클래스는 프로그램실행하는 동안 발생할 수 있는 다양한 오류들을 처리
- C++에서 template은 다른 객체지향언어에서 부르는 "일반화를 뜻하는"제네릭(generic)이다.
- template 사용은 약간의 비용(실행비용)이 발생하지만 전체적으로 프로그램의 크기와 난이도를 줄일 수 있다
예를들어 int, double, char 타입에 대한 최솟값을 구하는 min 함수를 만들어 보자면 아래와 같이 3개의 함수가 필요하다.
int min (int a, int b) { return a < b ? a : b; }
double min (double a, double b) { return a < b ? a : b; }
char min (char a, char b) { return a < b ? a : b; }
하지만 template을 사용한다면 모든 data type에 대한 정의가 하나의 함수로 가능하다. 아래처럼 말이다.
template<typename T>
T min (T a, T b) { return a < b ? a : b; }
cf. 위의 T는 템플릿 매개변수라 부른다.
※ 템플릿 함수와 함수 템플릿
※ 템플릿 함수
-템플릿을 기반으로컴파일러가 만들어 내는 함수(템플릿 기반의 함수임을 표기한 것)
- 즉,템플릿 기반의 호출이 가능한“함수”라는 점에서 차이가 있다.
※ 함수 템플릿
- 함수 템플릿은 함수를 만들어 낸다.(기능은 결정되어 있으나 자료형은 결정 X)
- 따라서 함수 템플릿으로 다양한 자료형의 함수를 만들 수 있다.
- 함수를 만드는데 사용되는 템플릿으로 호출이 가능한 함수가 아닌 “템플릿”이다
※ 템플릿의 종류
- 함수 템플릿: 함수의 오버로딩을 확장한 개념
template<typename T>
T min (T a, T b) { return a < b ? a : b; }
- 클래스 템플릿:클래스를 만드는 템플릿으로 내부의 멤버변수.함수의 data type 지정시 사용
- 템플릿 클래스: 클래스 템플릿을 기반으로 컴파일러가 만든 클래스이다. 다만, 클래스 템플릿 기반 객체생성에는 반드시 <int>와 같은 자료형을 명시해 줘야 한다!
template <typename T>
class Animal{
private:
T num;
public:
Animal(T num) : num(num) {}
T eat(const T& ref);
};
template <typename T>
T Animal<T>::eat(const T& ref) {}
int main() {
Animal<int> a(4);
a.eat(4);
}
- 타입 템플릿: using으로 data type을 템플릿으로 지정시 사용
template <typename T>
using ptr = T*;
ptr<int> x; // int *x와 동일한 선언
- 변수 템플릿: 변수에 적용할 수 있는 템플릿 (C++14 이후부터 적용)
template <typename T>
constexpr T PI = T(3.141592653589793238462643L);
※ 템플릿의 특수화
- 특정 자료형으로 생성된 객체에 대해 구분이 되는 다른 행동양식 적용하기 위함
- 즉, 템플릿을 구성하는 멤버함수 일부 혹은 전체를 모두 다르게 행동시킬 수 있음
Q. 문자열 비교할 때, 사전순이 맞을까? 아니면 길이순이 맞을까?
A: 이런 특수 상황에 따라 예외가 필요하기에 사용하는 것이 바로 템플릿의 특수화이다.
※ 함수 템플릿과 static 지역변수
함수템플릿을 기반, 컴파일러는 ‘템플릿 함수’들을 만들어 낸다.
따라서 static 지역변수도 템플릿 함수 별로 각각 존재하게 된다.
※ 클래스 템플릿과 static 멤버변수
static멤버변수는 변수가 선언된 클래스의 객체간 공유가 가능.
따라서 클래스별 static 멤버변수를 유지하게 된다.
좌) 함수 템플릿과 static 지역변수 우) 클래스 템플릿과 static 멤버변수
※ 템플릿기반 템플릿 클래스 객체를 저장하는 객체 생성법
※ Advanced Template
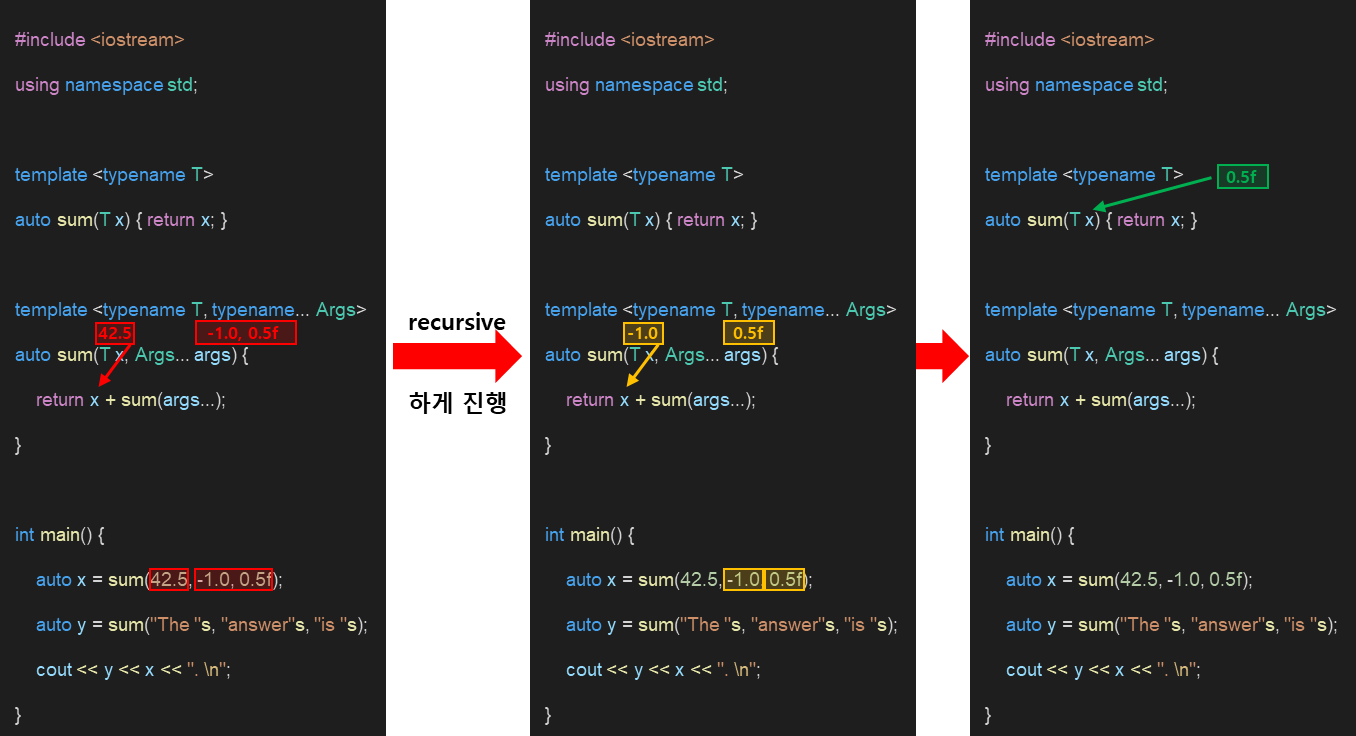
python에서 다음과 같이 print함수를 사용할 때, 인자로 전달되는 것들을 모두 출력할 수 있다.
print(1, 3.1, "abc")
그렇다면 C++에서도 이와 같은 방법으로 출력에서 인자에 대한 사전정보가 없을 때, 출력을 조금 더 유동적으로 하는 방법은 없을까?
위에서 사용한 recursion진행 대신 사용하는 방법으로 variadic template에서 가변인자 처리를 위해 parameter pack을 사용하는데, 이때! C++17부터 fold expression이 제공되어 parameter pack을 더 쉽게 사용할 수 있게 된 것이다.
- 인자가 1개:
1) Unary right
(E op ...) ex_ (E1 op (... op (EN-1 op EN)))
2) Unary left
(... op E) ex_ (((E1 op E2) op ...) op EN)
unary right fold
E1 op ( ... op ( En-1 op En))
- 전달받은 parameter pack을 위와 같은 표현식으로 변경 - 뒤에 있는 인자 부터 먼저 순차적으로 연산해서 결과 값을 생성
이를 위해서((AnotherClass*)(ptr.get()))와 같이 강제로 포인터를 얻어 캐스팅을 해줄 수 있지만 전혀 C++ 답지 못하다.
따라서 static_pointer_cast / dynamic_pointer_cast / const_pointer_cast 가 추가되었다.
이를 통해 안전하고도 편한 스마트 포인터 캐스팅이 가능해진 것이다.
vector<shared_ptr<MediaAsset>> assets;
assets.push_back(shared_ptr<Song>(new Song(L"Himesh Reshammiya", L"Tera Surroor")));
assets.push_back(shared_ptr<Song>(new Song(L"Penaz Masani", L"Tu Dil De De")));
assets.push_back(shared_ptr<Photo>(new Photo(L"2011-04-06", L"Redmond, WA", L"Soccer field at Microsoft.")));
vector<shared_ptr<MediaAsset>> photos;
copy_if(assets.begin(), assets.end(), back_inserter(photos), [] (shared_ptr<MediaAsset> p) -> bool {
// Use dynamic_pointer_cast to test whether
// element is a shared_ptr<Photo>.
shared_ptr<Photo> temp = dynamic_pointer_cast<Photo>(p);
return temp.get() != nullptr;
});
for (const auto& p : photos) {
// We know that the photos vector contains only
// shared_ptr<Photo> objects, so use static_cast.
wcout << "Photo location: " << (static_pointer_cast<Photo>(p))->location_ << endl;
}
변수의 type을 강제로 다른 type으로 변경하는 것으로 자료형간 || 포인터간 형변환시 사용된다.
C/C++은 변수의 type을 변경해 처리해야 하는 경우가 빈번하게 발생한다.
Q. 외부 library 사용시, 인자로 넘겨야할 변수가 char인데 외부의 library가 unsigned char를 사용한다면?
A: 개발자는 unsigned char로 변경해서 넘겨주어야 컴파일 에러가 발생하지 않는다.
int print(unsigned char *str){
cout << str << endl;
}
int main() {
char str[20] = "Hello, world!";
print(str); // type casting이 필요 (Err)
print(reinterpret_cast<unsigned char*>(str));
}
※ Type Casting의 종류
캐스트는 크게 2가지로 나눌 수 있다.
- 묵시적 캐스트 (implicit cast): 캐스트 연산자를 사용하지 않고 형변환이 이뤄지는 경우
- 명시적 캐스트 (explicit cast): 캐스트 연산자를 사용하여 형변환이 이뤄지는 경우
※ static_cast
[사용시기]: 논리적으로 변경가능한 경우
- static_cast의 특성은 묵시적 캐스트와 비슷하다 보면 된다.
- 묵시적 캐스트는 컴파일 시점에서 '무결성'을 검사하는데 이때, '허용'과 '컴파일러에 의한 값 변환' 두 관점이 있다.
- static_cast는 형변환에 의한 타입 확인을 compile 시간에 정적으로 수행한다.
§ 명시적 형변환 §
float f;
int a = static_cast<int>(f);
char *str = static_cast<char*>(f); // Err!
※ const_cast
[사용시기]: 포인터, 참조형에서만 사용가능const 및 volatile 제거할 때 사용된다!
- const_cast는 상수성이나 volatile(최적화 제외 변수)의 속성을 제거할 때 사용한다.
§ 명시적 형변환 §
int x = 10;
const int *pt_const_x = new int(10);
int *ptx;
ptx = const_cast<int*>(pt_const_x);
*ptx = 20; // 20에서 10으로 값 변경
const int &rt_const_x = x;
int& rtx = const_cast<int&>(rt_const_x);
※ reinterpret_cast
[사용시기]: 명시적 변환과 동작이 동일해 대신 사용된다. 단, const 사용 변환대상은 불가!
- 어떤 포인터 타입도 어떤 포인터 타입으로든 변환이 가능!
- [정수 -> 포인터] 타입도, [포인터 -> 정수]타입으로도 가능하다.
- 강력한 casting 같지만 특수 케이스가 아닌이상 사용을 잘하지 않는 것을 추천 (포인터가 강제 형변환되서)
§ 명시적 형변환 §
int *ptr = new int(10);
char *str;
str = reinterpret_cast<char*>(ptr);
*str = 20; // 10 -> 20으로 값변경
§ const 지정자 사용시, 명시적 형변환 §
const int *ptr = new int(10);
char *str;
str = reinterpret_cast<char*>(const_cast <int*> (ptr));
*str = 20; // 10에서 20으로 값변경
※ dynamic_cast
[사용시기]: class의 포인터, 참조변수간 형변환 시 안전하게 down casting을 위해 사용.
Runtime conversions로 RTTI(Requires Runtime Type Information)
단, parent에 virtual 함수가 존재해야 정상작동!
- run time에 동적으로 상속계층관계를 가로지르거나 down casting시 사용됨
- 기본클래스에 virtual 멤버함수가 하나도 없다면, 다형성을 갖는게 아님(단형성)
∴따라서 dynamic_cast는 다형성을 띄지 않은 객체간 변환은 불가능!
§ 명시적 형변환 §
#include <iostream>
using namespace std;
class Blog {
public:
Blog() { cout << "Blog()\n"; };
virtual ~Blog() { cout << "~Blog()\n"; };
void Show() { cout << "This is Blog Class\n"; }
};
class Tistory : public Blog {
public:
Tistory() { cout << "Tistory()\n"; };
virtual ~Tistory() { cout << "~Tistory()\n"; };
void Show() { cout << "This is Tistory Class\n"; }
};
int main(void) {
Blog* pBlog = new Blog();
pBlog->Show();
Tistory* pTistory = dynamic_cast<Tistory*>(pBlog);
if (pTistory == nullptr) { //티스토리 클래스의 포인터가 nullptr이 나올떄.
cout << "Runtime Error\n";
}
else {
pTistory->Show();
}
delete pBlog;
system("pause");
}
※ static_cast VS dynamic_cast
[static_cast]: 정적으로 형변환을 해도 아무 문제가 없다 (= 이미 어떤 녀석인지 알고 있다는 뜻), Fast
[dynamic_cast]: 동적으로 형변환을 시도 해본다는 뜻 (= 이녀석의 타입을 반드시 알아봐야 한다는 뜻), Slow (RTTI)
따라서 dynamic_cast를 이용해 Runtype의 해당 타입을 명확히 알아봐야 하고 (RTTI, Requires Runtime Type Info)
그렇지 않은 경우, static_cast를 이용해 변환 비용을 줄이는 것이 좋다. (동적타입체크를 안해도 되서)
// 비행기에 여러 직군의 사람들이 탑승했다.
// 한 승객이 갑자기 급성 맹장염에 걸려 의사가 급하게 수술을 해야 한다.
class Passenger {...};
class Student : public Passenger{
...
void Study();
};
class Teacher : public Passenger{
...
void Teach();
};
class Doctor : public Passenger{
...
void Treat();
void Operate();
};
int main() {
typedef vector<Passenger *> PassengerVector;
PassengerVector passengerVect;
Passenger* pPS = new Student();
if (pPS){
passengerVect.push_back( pPS );
// 비행기 타자마자 공부한다고 치고~
// pPS가 명확하게 어느 클래스의 인스턴스인지 알고 있다.
// 이 경우엔 굳이 비용이 들어가는 dynamic_cast가 아닌, static_cast를 쓰는게 낫다.
Student* pS = static_cast<Student *>( pPS );
pS->Study();
}
Passenger* pPT = new Teacher();
if ( pPT ){
passengerVect.push_back( pPT );
}
// Doctor 역시 비슷하게 추가.
...
// 응급 환자 발생. passengerVect 중 의사가 있다면 수술을 시켜야 한다.
PassengerVect::iterator bIter(passengerVect.begin());
PassengerVect::iterator eIter(passengerVect.end());
for( ; bIter != eIter; ++bIter ) {
// Passenger 포인터로 저장된 녀석들 중 누가 의사인지 구분해야 한다.
// 런타임 다형성 체크에 의해 Doctor가 아닌 녀석들에 대한 형변환 결과는 NULL
Doctor* pD = dynamic_cast<Doctor *>(*bIter);
if (pD){
pD->Operate();
}
}
}
위 예제는 static_cast와 dynamic_cast를 구분해서 언제 쓰는게 좋은지 알 수 있는 예제이므로 잘 분석해보자.
Q. 만약, 위 코드의 전체 승객 중 의사를 찾아내는 과정에서 dynamic_cast가 아니라, static_cast를 사용하였다면 어떻게 될까?
static_cast는 동적 타입체크를 하지 않고, Student와 Teacher는 Person의 파생 클래스이므로
변환 연산 규정에도 위배되지 않으므로, 그냥 타입 변환이 일어난다.
하지만, 변환 결과는 애초 기대했던 바와 전혀 다릅니다. 실제 Student 클래스 타입이지만,
Doctor 클래스 타입으로 타입 변환이 되면서Doctor 클래스 고유 멤버 함수에 대한 접근이 불가능해진다.
포인터가 가리키는 메모리 내용을 Doctor 클래스에 맞춰서 해석하기에
Student의 내용 중 일부가 Doctor 멤버 필드에 엉뚱하게 들어가거나, 슬라이스 문제가 발생할 수 있다.
다시 말해, 껍데기만 Doctor 클래스이지 내용은 전혀 Doctor의 것이 아니게 되는데,
멤버 필드에 접근시 엉뚱한 값이 들어가 있거나, 런타임 Err가 발생할 수 있다.
2. 그 후 expr의 형식을 ParamType에 대해 pattern-matching방식으로 대응시켜 T의 형식을 결정한다.
template<typename T>
void f(T& param); // param은 참조형식
int x = 27; // x는 int
const int cx = x; // cx는 const int
const int& rx = x; // rx는 const int인 x에 대한 참조
/* 여러 호출에서 param과 T에 대해 연역된 형식 */
f(x); // T는 int, param의 형식은 int&
f(cx); // T는 const int, param의 형식은 const int&
f(rx); // T는 cosnt int, param의 형식은 const int&
위 f(cx), f(rx)의 param은 const값이고, 이는 그 객체가 수정되지 않을 것이라 기대한다.
즉, 해당 매개변수가 const에 대한 참조일 것이라 기대한다. (T& 매개변수를 받는 템플릿에 const객체를 전달해도 안전한 이유)
f(rx)에서 비록 rx의 형식이 참조이지만 T는 비참조로 연역된 것에 주목하면 이는 형식연역과정에서 rx의 참조성이 무시되기 때문임을 알 수 있다.
만약 f의 매개변수 형식을 T&에서 const T&로 바꾸게 된다면 상황이 달라지지만 큰 변화는 없다.
cx와 rx의 const성은 유지되며 단, param이 const에 대한 참조로 간주되므로
const가 T의 일부로 연역될 필요는 없다.
template<typename T>
void f(const T& param); // param이 cosnt에 대한 참조
int x = 27; // x는 int
const int cx = x; // cx는 const int
const int& rx = x; // rx는 const int인 x에 대한 참조
/* 여러 호출에서 param과 T에 대해 연역된 형식 */
f(x); // T는 int, param의 형식은 const int&
f(cx); // T는 int, param의 형식은 const int&
f(rx); // T는 int, param의 형식은 const int&
이전처럼 rx의 참조성은 형식연역과정에서 무시된다.
이는 아래처럼 param을 참조가 아닌 포인터, const를 가리키는 포인터라도 형식연역은 본직적으로 같은 방식을 취한다.
template<typename T>
void f(T* param); // param이 cosnt에 대한 참조
int x = 27; // x는 int
const int *px = x; // px는 const int로 x를 가리키는 포인터
/* 여러 호출에서 param과 T에 대해 연역된 형식 */
f(&x); // T는 int, param의 형식은 int*
f(px); // T는 const int, param의 형식은 const int*
여기까지는 너무 쉬워서 하품이 날 지경이라고 한다.(물론 저자가 그런거지 난 아니다. 어려워 죽을거 같다.)
Case 2. ParamType이 보편참조임.
템플릿이 보편참조매개변수를 받는 경우, 상황이 불투명해진다.
그런 매개변수 선언은 rvalue 참조와 같은 모습이다. (보편참조의 선언형식은 T&&이다.)
l-value가 전달되면 r-value참조와는 다른 방식으로 행동한다.
- 만약 expr이 l-value면, T와 ParamType 둘 다 l-value 참조로 연역된다. (비정상적 상황)
i) 템플릿 형식 연역게서 T가 참조형식으로 연역되는 경우, 이것이 유일
ii) ParamType의 선언구문은 r-value 참조와 같지만 연역된 형식은 l-value참조이다.
- 만약 expr이 r-value면, '정상적인' 규칙들이 적용된다. (Case 1의 규칙들.)
template<typename T>
void f(T&& param); // 이번에는 param이 보편 참조
int x = 27; // x는 int
const int cx = x; // cx는 const int
const int& rx = x; // rx는 const int인 x에 대한 참조
f(x); // x는 l-value, 따라서 T는 int&, param 형식도 int&
f(cx); // cx는 l-value, 따라서 T는 const int&, param 형식도 const int&
f(rx); // rx는 l-value, T는 const int&, param 형식도 const int&
f(27); // 27은 r-value, 따라서 T는 int, param 형식은 int&&
나중에 item 24에서 설명될 것이고, 지금은 보편참조매개변수에 관한 형식연역 규칙들이
l-value참조나 r-value참조 매개변수들에 대한 규칙들과는 다르다는 점만 기억하면 된다.
특히 보편참조가 관여하는 경우, l-value와 r-value에 대해 서로 다른 연역규칙이 적용된다. (보편참조가 아니면 발생X)
Case 3. ParamType이 포인터도 아니고 참조도 아님
ParamType이 포인터도 참조도 아닌 경우, 인수가 함수에 값으로 전달되는 pass-by-value인 상황이다.
param이 새로운 객체라는 사실 때문에 expr에서 T가 연역되는 과정에서 다음과 같은 규칙들이 적용된다.
1. 이전처럼, 만약 expr의 형식이 참조라면, 참조부분은 무시된다.
2. expr의 참조성을 무시한 후 만약 expr이 const라 해도 그 const 역시 무시한다.
만약 volatile객체라도 그것도 무시한다. (volatile객체는 흔하지 않기에 (장치구동기 구현시 사용) item 40 참고)
다음은 이 규칙들이 적용되는 예이다.
template<typename T>
void f(T&& param); // 이번에는 param이 보편 참조
int x = 27; // x는 int
const int cx = x; // cx는 const int
const int& rx = x; // rx는 const int인 x에 대한 참조
f(x); // T와 param의 형식 둘 다 int
f(cx); // 여전히 T와 param의 형식 둘 다 int
f(rx); // 여전히 T와 param의 형식 둘 다 int
이때, cx와 rx는 const값이지만, param은 const가 아님을 주목하자.
param은 cx, rx의 복사본이므로 (param은 cx, rx와 달리 완전히 독립적인 객체이므로) 당연한 결과이다.
cx, rx가 수정될 수 없다는 점(const)은 param의 수정가능 여부와는 무관하기 때문이다.
param의 형식을 연역하는 과정에서 expr의 const성이 무시되는 이유가 바로 이것이다.
expr을 수정할 수 없다해서 그 복사본까지 수정할 수 없는 것은 아니기 때문이다.
여기서 명심할 점은, const가 값 전달 매개변수에 대해서만 무시된다는 점이다.
즉, const에 대한 참조나 포인터 매개변수의 경우, 형식연역과정에서 expr의 const성이 보존된다.
그러나 expr이 cosnt객체를 가리키는 const포인터이고 param에 값으로 전달되는 경우는 어떨까?
template<typename T>
void f(T param); // 인수는 param에 여전히 값으로 전달됨
const char* const ptr = "V2LLAIN"; // ptr은 const 객체를 가리키는 const 포인터
f(ptr); // const char* const 형식의 인수를 전달
포인터 선언 오른쪽 const로 ptr 자체가 const가 된다. (const char* const ptr)
즉, ptr을 다른 장소를 가리키도록 변경불가능! (nullptr도 배정할 수 없다.)
포인터 선언 왼쪽 const가 가리키는 것은 문자열이 const인 것을 의미한다. (const char* const ptr)
ptr을 f에 전달하면 그 포인터를 구성하는 bit들이 param에 복사되며 포인터자체(ptr)는 값으로 전달된다.
형식연역과정에서 ptr의 const성은 무시되며 따라서 param에 연역되는 형식은 const char*이다.
즉, 형식연역과정에서 ptr이 가리키는 것의 const성은 보존되나
ptr 자체의 const성은 ptr을 복사해 새 포인터 param을 생성하는 도중 사라진다!
※ 템플릿 연역과정에서 배열이나 함수이름에 해당하는 인수는 포인터로 붕괴(decay)한다.
(단, 그런 인수가 참조를 초기화하는데 사용되면, 그 경우에는 포인터로 붕괴하지 않는다.)
- 템플릿형식 연역 중 참조형식의 인수들은 비참조로 취급된다. 즉, 참조성이 무시된다.
- 보편참조 매개변수에 대한 형식 연역과정에서 l-value들은 특별하게 취급된다.
- 값 전달방식의 매개변수에 대한 형식연역과정에서 const, volatile 인수는 비 const, 비 volatile 인수로 취급된다.
- 템플릿형식 연역과정에서 배열이나 함수이름에 해당하는 인수는 포인터로 붕괴한다.
단, 그런 인수가 참조를 초기화하는데 쓰이는 경우, 포인터로 붕괴하지 않는다.