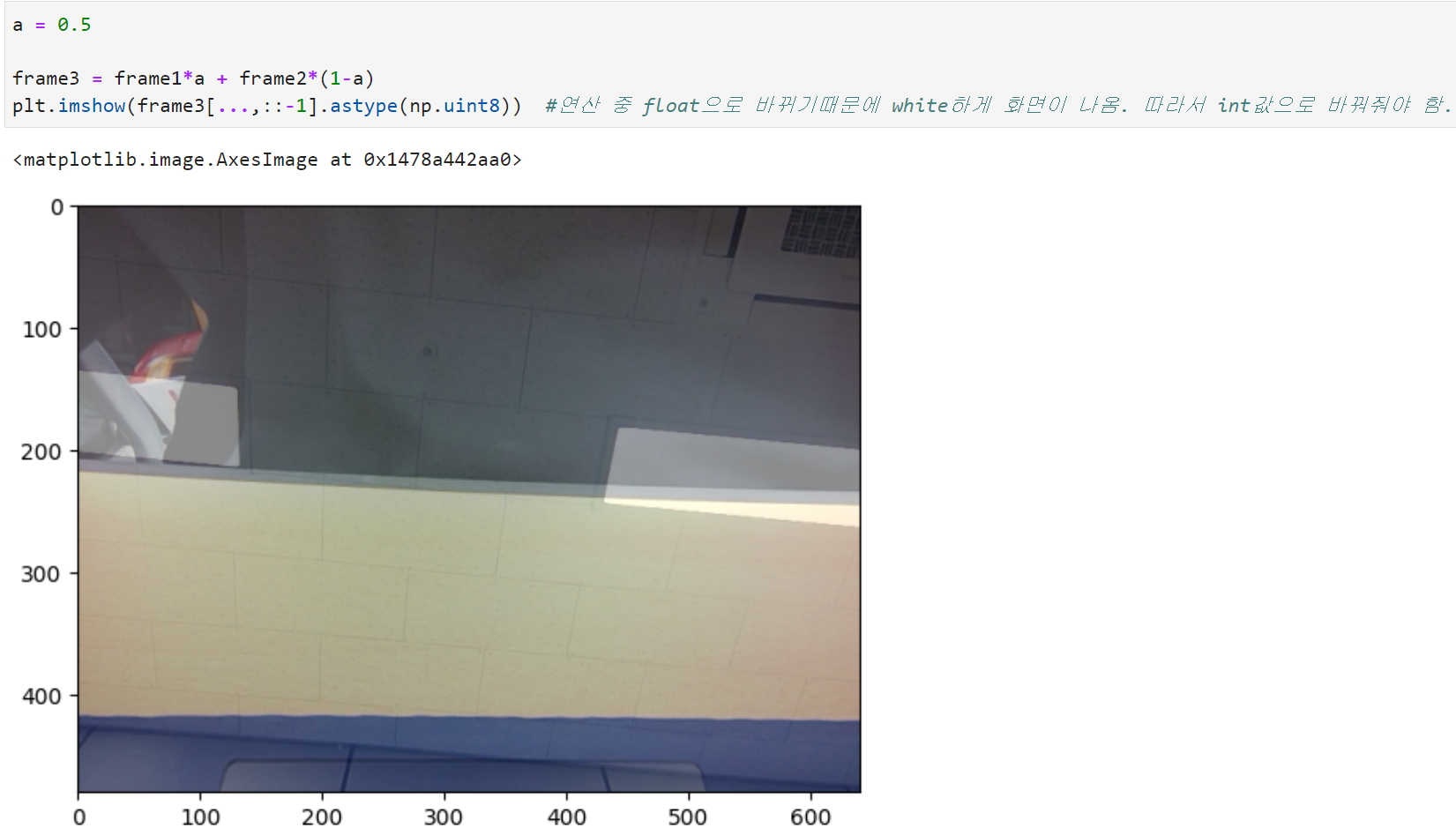
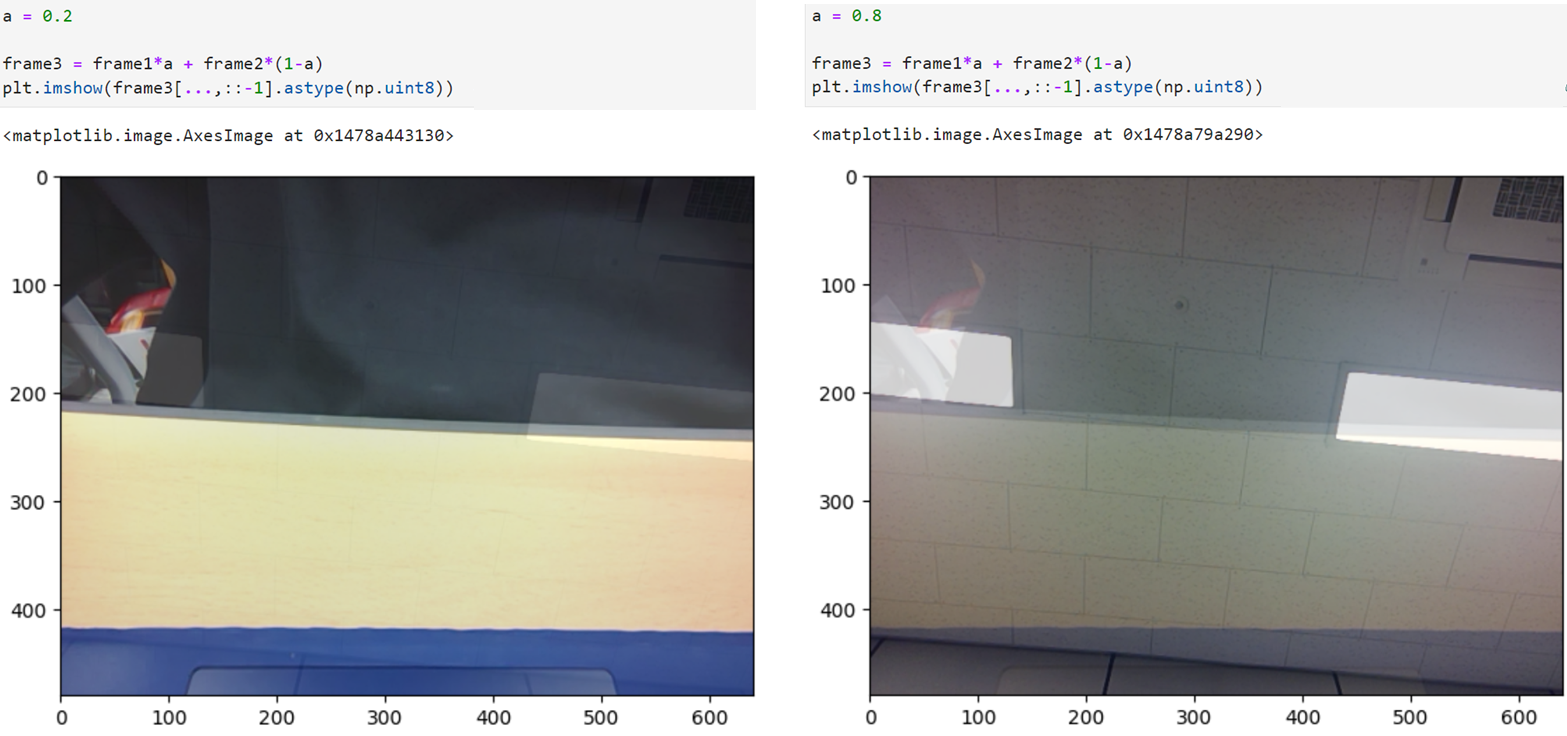
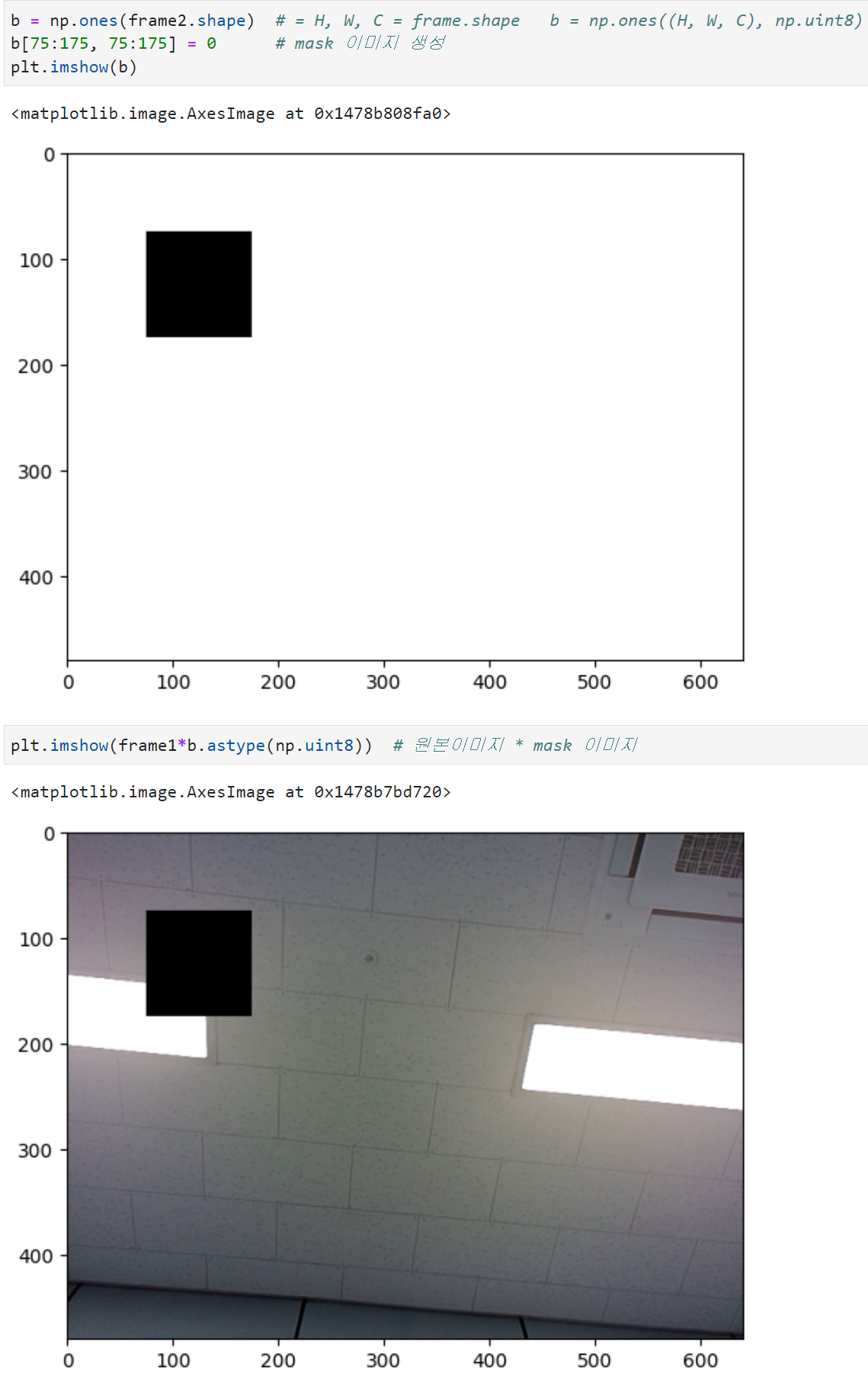
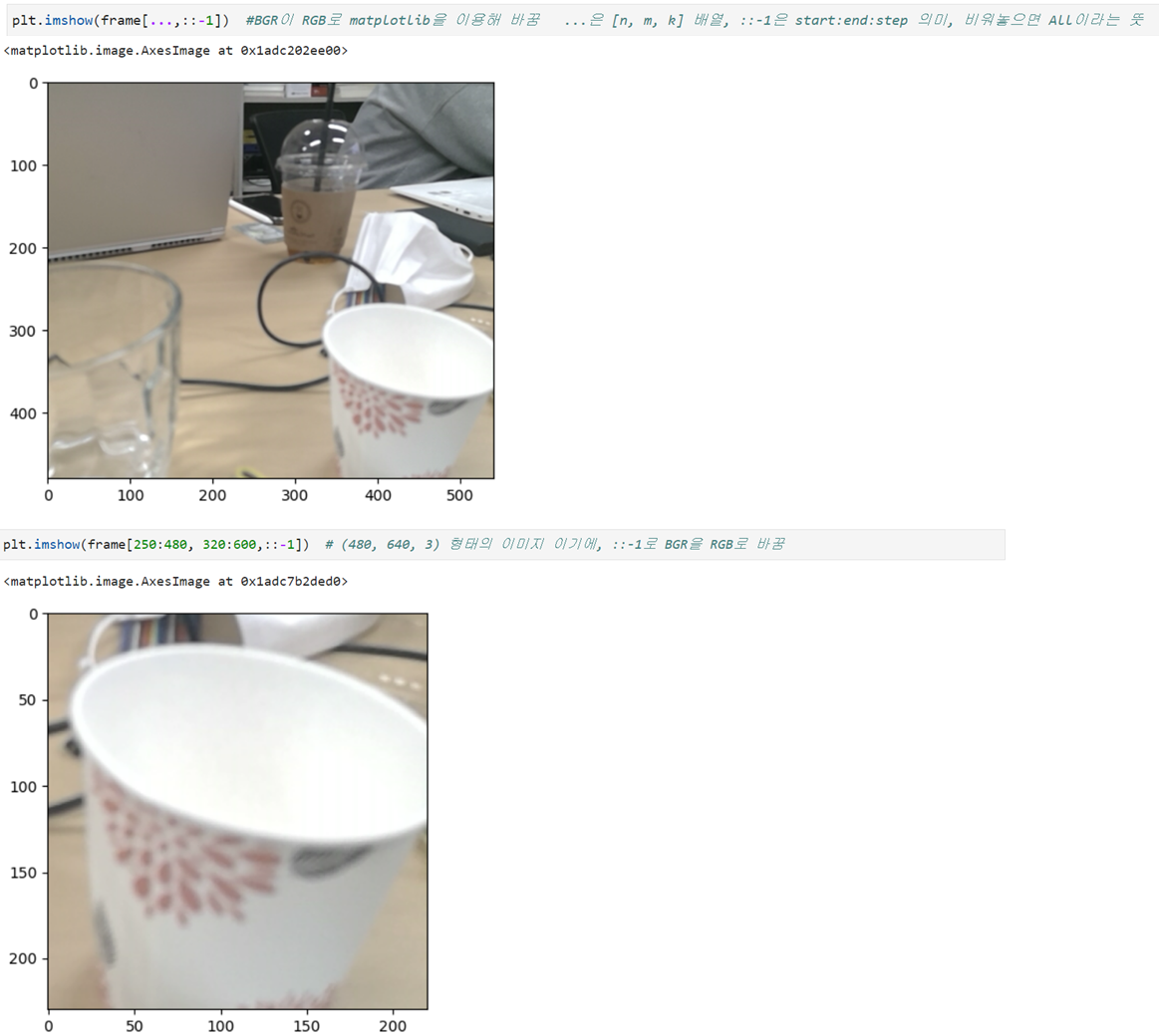
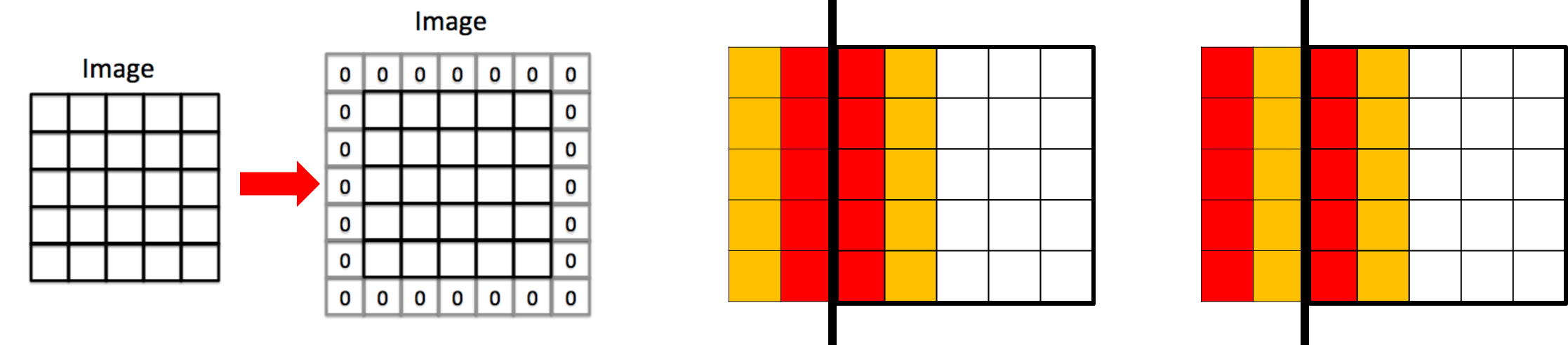
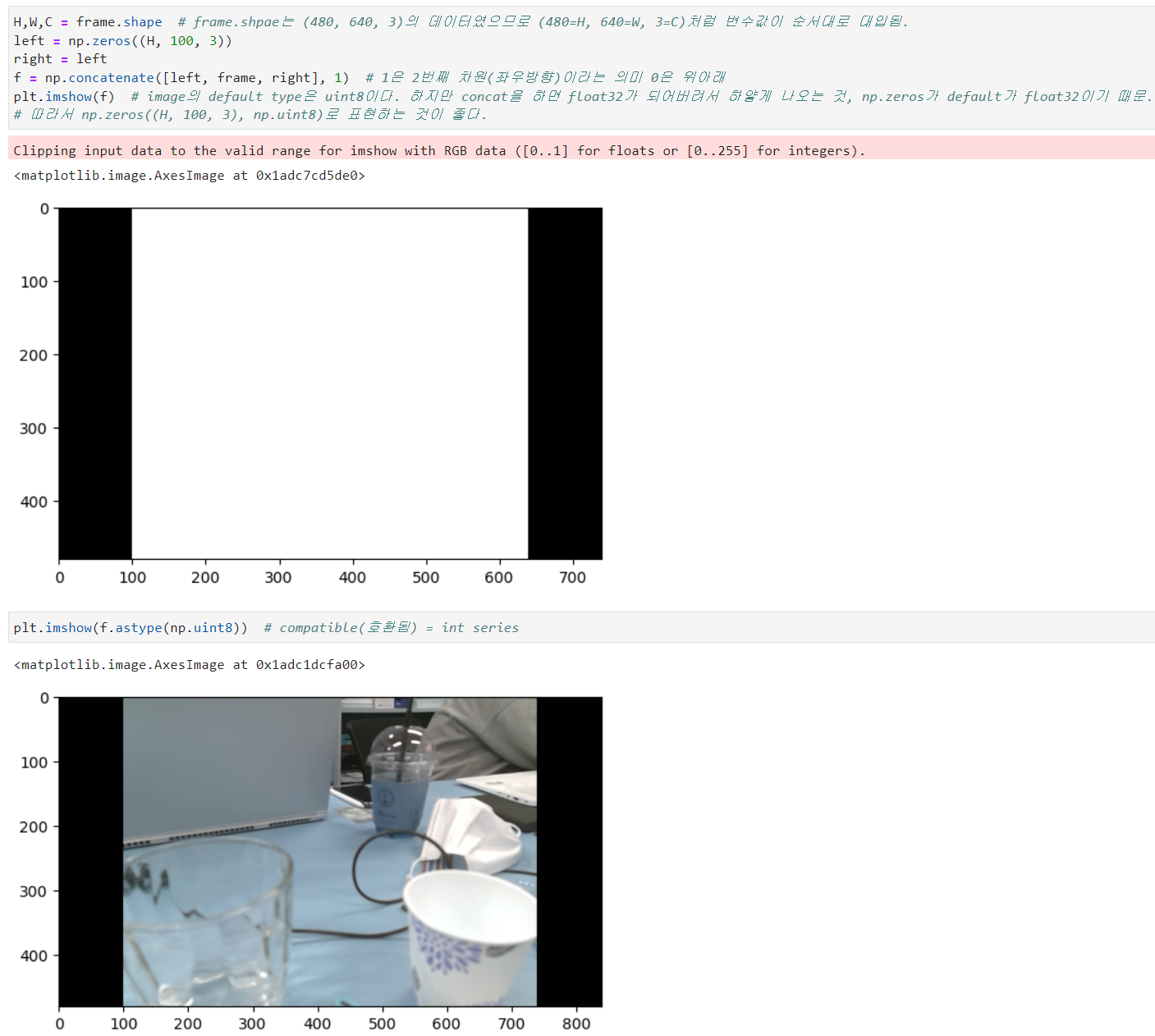
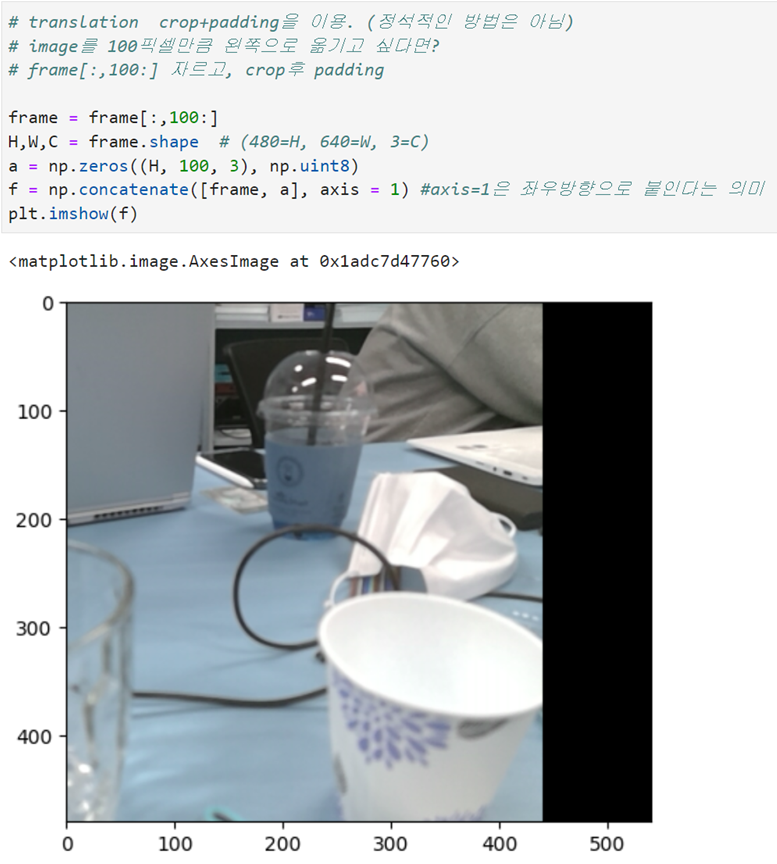
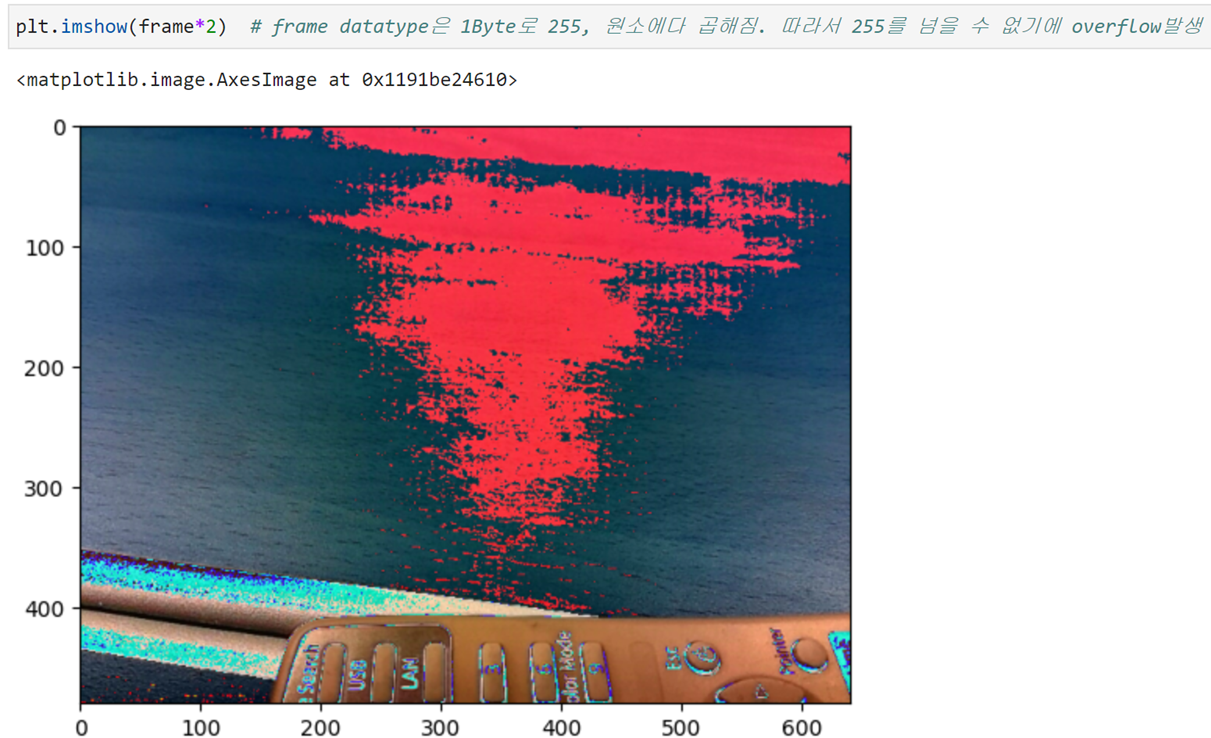
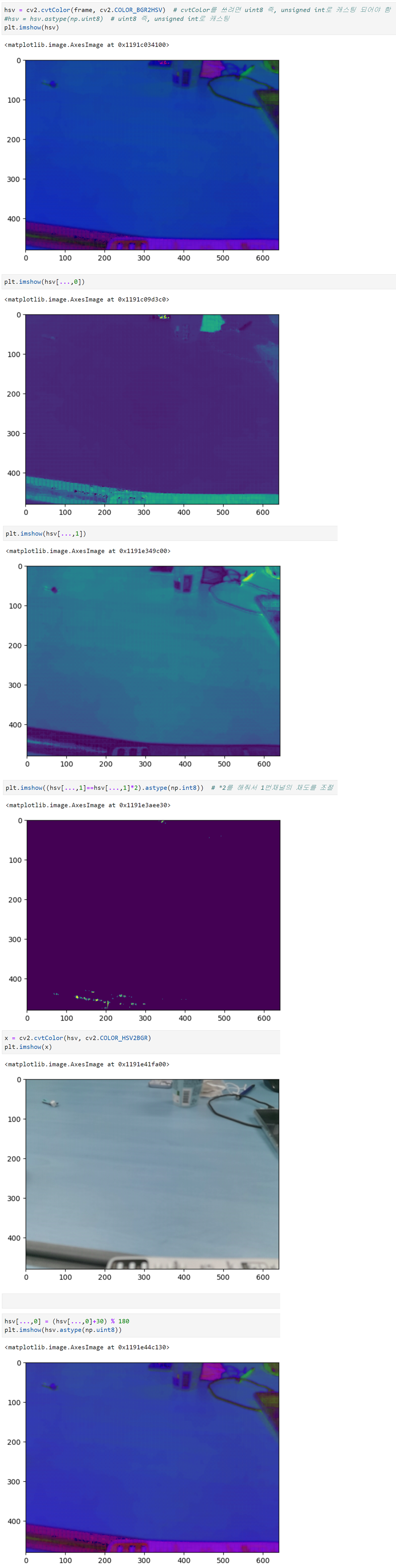
장점: 빠르다. (inference(추론), 즉 학습이 끝난 후 결과를 낼 때 많이 사용)
단점: memory가 비교적 많이 필요하다.
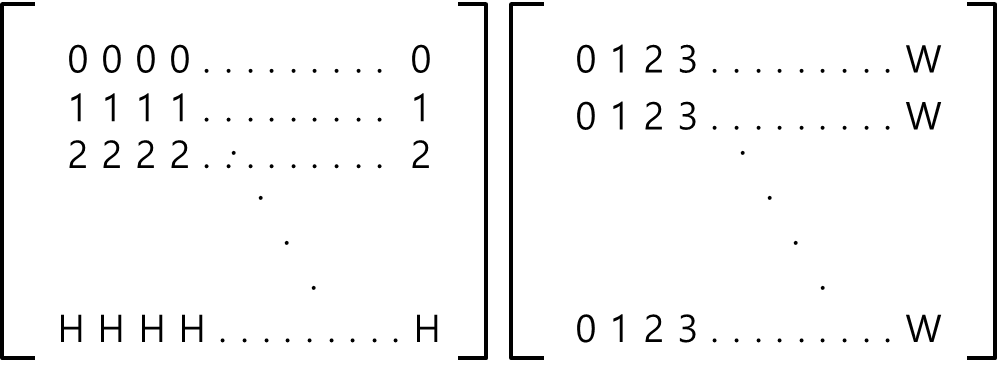
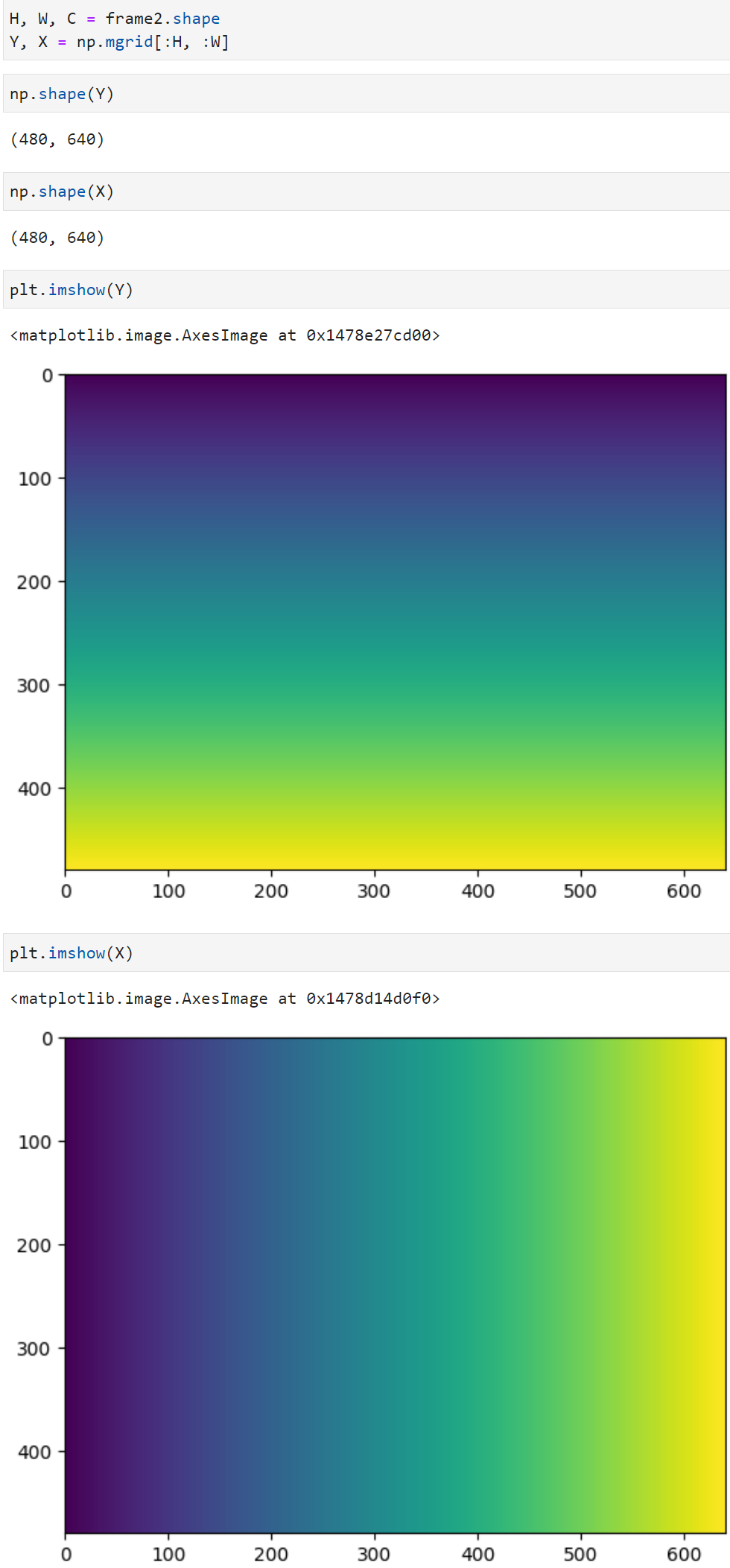
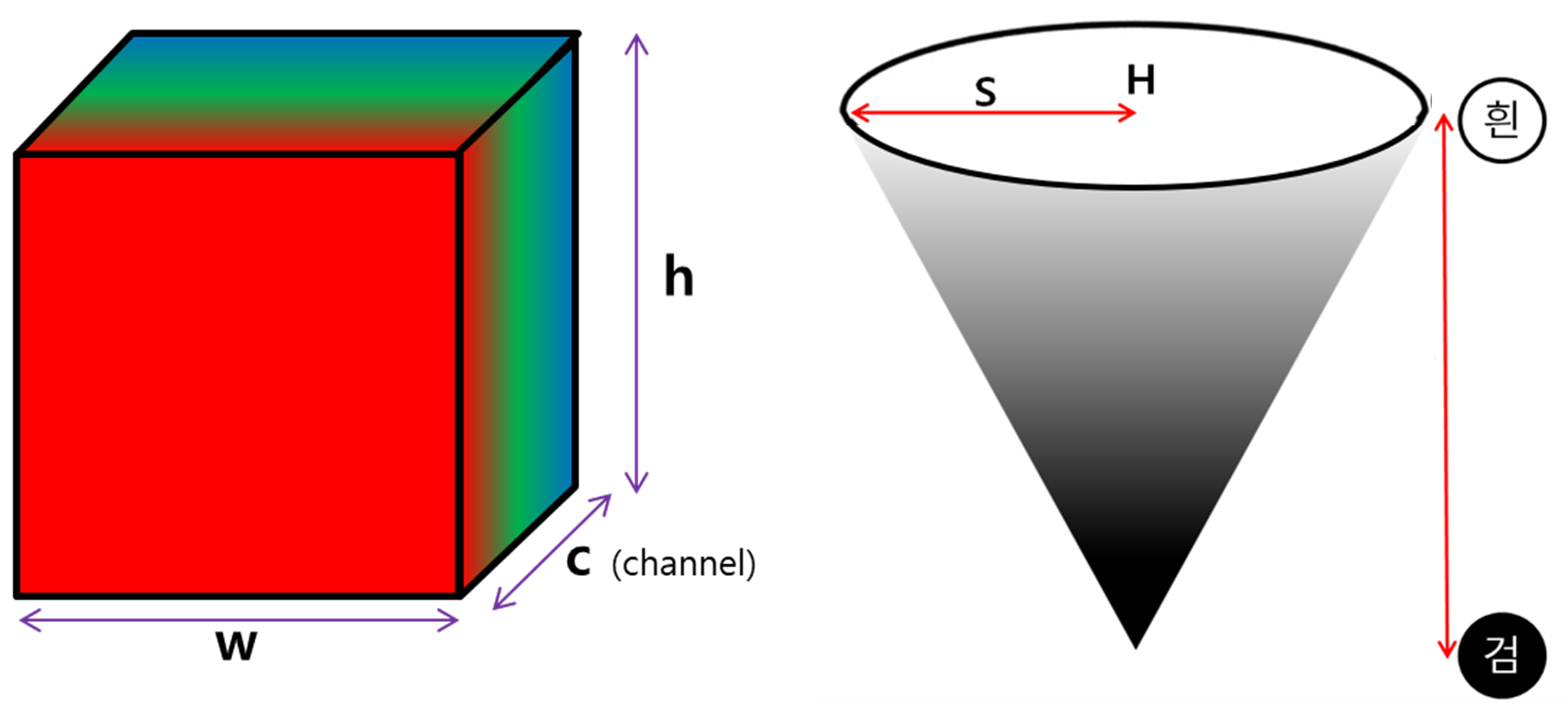
※ 배열의 축, axis이해하기.
배열에는 축이라는 개념이 있는데, 이 축이 헷갈리는 이유는 행렬개념과는 조금 다르게 받아들여야 하기 때문이다.
1차원 배열 먼저 1차원 배열의 경우, 축은 axis 0 하나뿐이다. (행열의 개념이 없음) array([0, 1, 2, 3, 4 ,5])
2차원 배열 다음으로 2차원 배열의 경우, 축은 axis 0, axis 1 두 가지가 있다. array([[0, 1, 2], [3, 4 ,5]]) 위의 경우, 우리는2행 3열로 배열을 해석하는데 행과 열에 대한 축의 매칭은 아래와 같다. 행: axis 0 열: axis 1 이때, 무작정 axis0을 행이라 외우는 것은 주의해야 한다. 고차원으로 갈수록 규칙이 깨지기 때문이다.
3차원 배열 다음으로 3차원 배열의 경우, 축은 axis 0, axis 1, axis 2 세 가지가 있다. array([[[ 0, 1, 2, 3], [ 4 ,5, 6, 7], [ 8, 9, 10, 11]],
[[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) 위의 경우, 3행 4열의 행렬이 2층으로 배열을 해석하는데 행과 열, 높이에 대한 축의 매칭은 아래와 같다. 높이: axis 0 행: axis 1 열: axis 2
• Computer Vision -> 자연어 처리 -> 오디오 부분 순으로 발전하였기에 가장 발전된 분야
• 시각적 세계를 해석하고 이해하도록 컴퓨터에 학습시키는 인공지능 분야로 컴퓨터를 이용한 정보처리를 진행한다.
• 따라서 컴퓨터 비전은 정보를 데이터로 표현하기 매우 적절한 구조를 갖고 있다.
cf. 만약 It's late를 데이터로 표현하려면...? (feat. 자연어 처리) 자연어의 경우, 자연어는 데이터로 표현하기 어려운데, (데이터를 많이 갖고 있기 때문)
예시에서 It's의 t와 late의 t가 똑같은 용도로 사용될까? 이런 저런 이유로 컴퓨터비전은 데이터를 표현하기 매우 좋다.
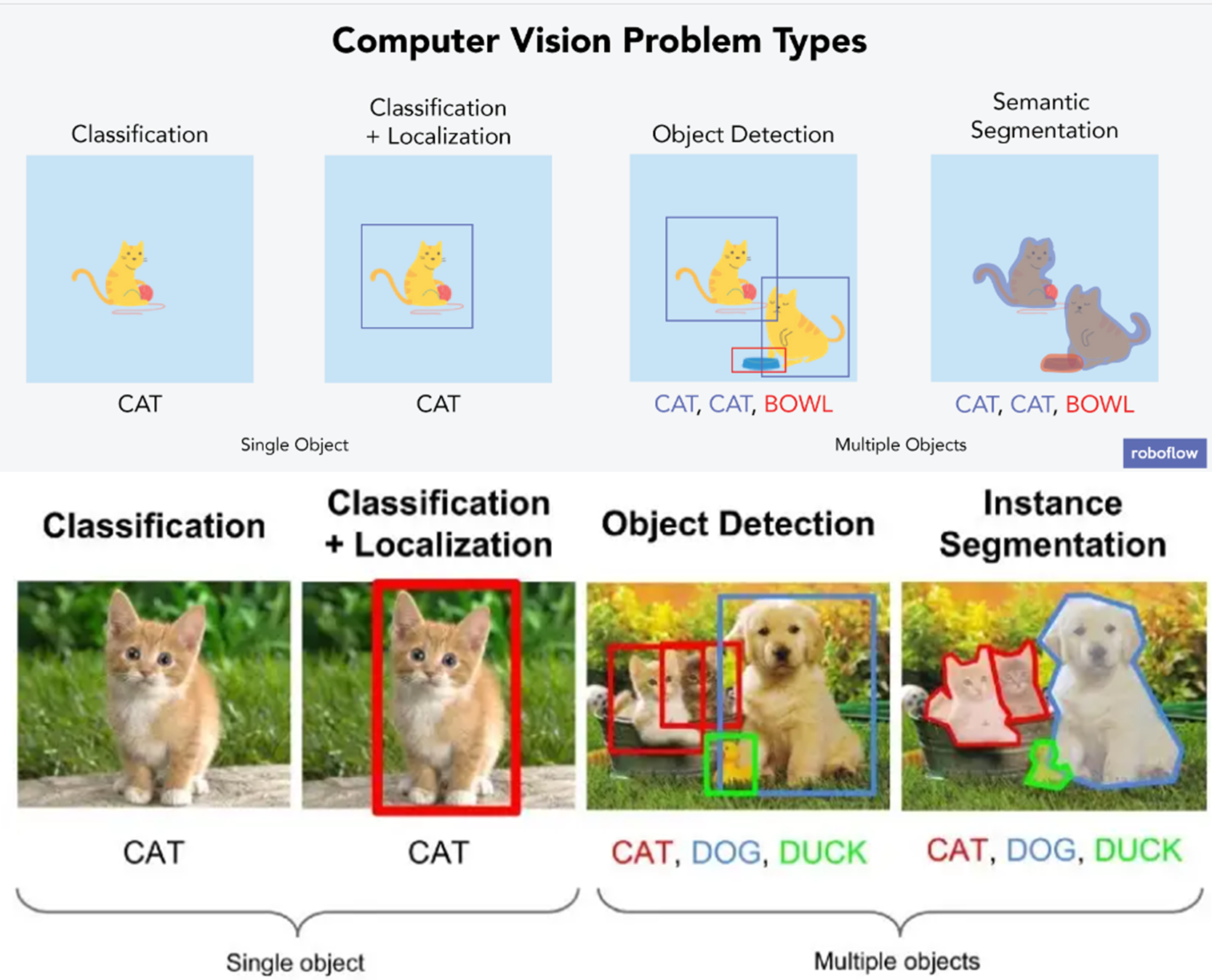
※ PASCAL VOC challenge 문제
초창기 이미지 dataset에 대해 인식성능을 겨루는 대회가 열렸고,
가장 대표적인 PASCAL VOC(Visual Object Classes) Challenge 로 이 대회를 기점으로 이미지 인식에서 다루는 문제들이 아래와 같이 정형화 되었다,
• Classification
• Detection
• Segmentation
Classification
※ Classification 특정 class에 해당하는 사물이 포함되어 있는지 여부를 분류하는 모델 classification은 Detection, Segmentation문제를 향한 출발점이기에 더더욱 중요하며 다음 2가지로 나눌 수 있다.
§ 단일 사물 분류 문제 - 모든 이미지가 반드시 하나의 사물만 존재 - 전체 class에 대한 confidence score S를 비교, 가장 큰 confidence score를 지니는 class로 선정하는 방법
§ 복수 사물 분류 문제 - 이미지 상에 여러개의 사물들이 포함되어 있음 - 단순히 가장 큰 confidence score를 갖는 class 하나만을 선정하는 방법은 합리적이지 않게 된다. - 방식이 조금씩은 다르나 class별 threshold를 정해놓고 S > threshold 일 때 ==> "주어진 이미지 안에 해당 class가 포함되어 있을 것이다" 라고 결론지음
▶ 평가척도 • accuracy = 올바르게 분류한 이미지 수 / 전체 이미지 수 - accuracy는 classification문제에서 일반적으로 test를 위해 측정한다. - 이 방법은 단일 사물 분류문제에서는 즉각사용해도 별 문제가 없다. - 하지만 복수 사물 분류문제에서는 곤란해질 수 있어서 아래와 같은 평가척도를 사용한다.
• precision과 recall은 class A에 대해 다음과 같이 측정한다. precision = 올바르게 분류한 A 이미지 수 / A로 예측한 이미지 수 recall = 올바르게 분류한 A 이미지 수 / 전체 A 이미지 수
Detection
※ Detection image localization이라고도 불리며 classification에서 어느 위치에 포함되어 있는지 "박스형태"로 검출하는 모델을 만드는 것이 목표이다. 이 박스를 bounding box라 한다.
▶ 평가척도 IOU (Intersection Over Union) • 사물의 Class와 위치의 예측결과를 동시에 평가해야해서 사물의 실제 위치를 나타내는 실제 bounding box (GT bounding box)정보와 예측 bounding box가 얼마나 "겹쳐지는지"를 평가한다. Bp: 예측 bounding box Bgt: GT bounding box Bp와 Bgt의 IOU = Bp∩Bgt 영역넓이 / Bp∪Bgt 영역넓이 보통 이에 대한 threshold를 0.5로 정해놓고 있으며 여러개의 bounding box가 모두 IOU를 50%를 넘겨 매칭되면 결과적으로 매칭에 실패한것으로 간주한다. (즉, 복수 개의 매칭이 되면 안된다.)
Segmentation
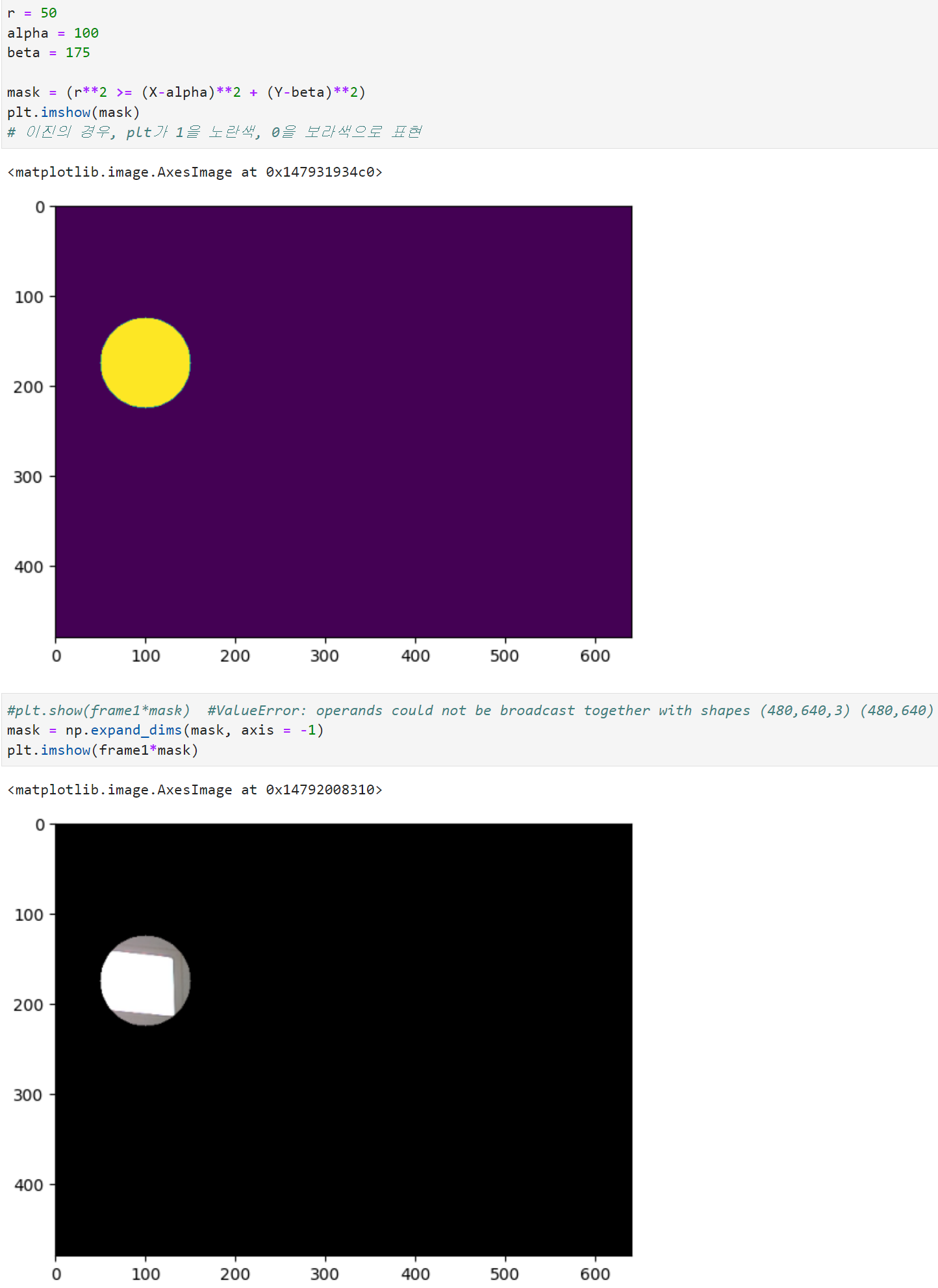
※ Segmentation 어느 위치에 있는지를 "Pixel 단위로 분할"하는 것으로 Detection보다 더 자세하게 위치를 표시한다. 이미지 내 각 위치상의 Pixel들을 하나씩 조사, 조사대상 Pixel이 어느 Class에도 해당하지 않으면? => background Class로 규정하여 해당 위치에 0을 표기하고 이 결과물을 mask라 부른다.
§ Semantic Segmentation - 분할의 기본단위: Class - 동일한 Class에 해당하는 사물은 동일한 색상으로 예측하여 표시
§ Instance Segmentation - 분할의 기본단위: 사물 - 동일한 Class에 해당하더라도 서로 다른 사물이면 다른 색상으로 예측하여 표시 ▶ 평가척도 IOU (IntersectionOverUnion) Ap: 예측 mask의 특정 Class 영역 Agt: GT(실제) mask의 해당 Class 영역 Ap와 Agt의 IOU = Ap∩Agt 영역넓이 / Ap∪Agt 영역넓이
※ Pixel (픽셀)이란?
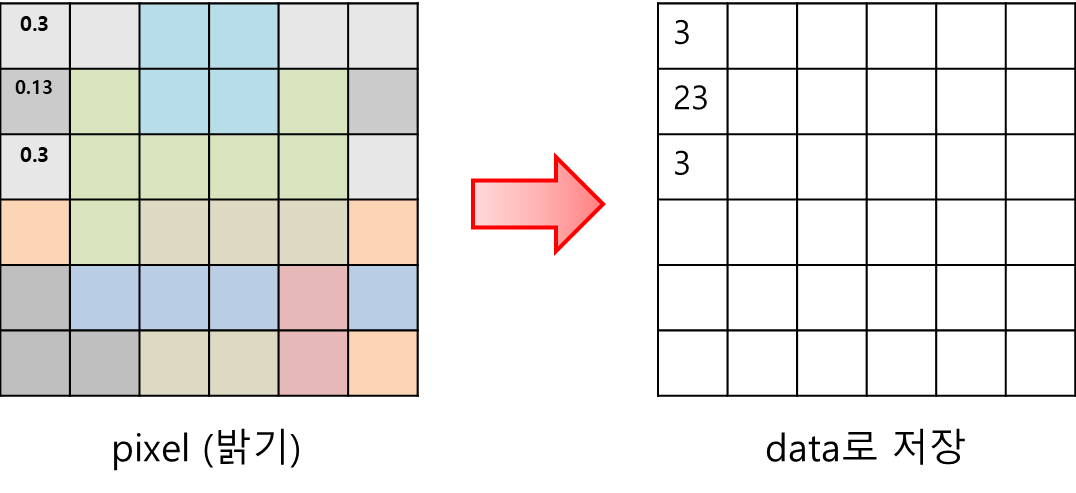
• 픽셀을 이용해 정보를 표현하기에, 픽셀은 한 단위(unit)로 "인간이 정의한 것"이다.
• 또한 pixel = brightness (밝기)를 이용해 표현하는데 이를 통해 알 수 있는 중요한 사실이 있다.
즉,픽셀은 이미지의 최소단위이다! (픽셀이 나타내는 값 = 밝기.)
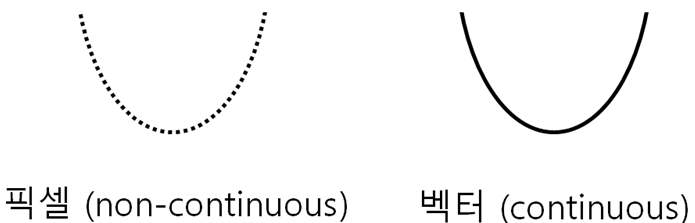
픽셀 함수에서 표현되는 데이터의 느낌과 정 반대가 있다.
↔ vector(수학적 의미가 아닌, vision information 측면의 벡터), 벡터는 함수같은 형식
픽셀: noncontinuous (어떤 unit을 정해 vector의 특정 부분을 묶은 것) 벡터: continuous한 것
실제 존재하는 사물들은 vector자체로 저장하기는 너무 방대하고 연속적이기에
이를 grid로 모두 잘라 pixel로 하여 특정범위별로 밝기를 0.1, 0.9처럼 하여 그 값들을 data로 3, 23처럼 저장하는 것
이렇듯 pixel은 숫자여서 우리가 보고 있는 모든 것들을 숫자로 표현가능하기에 컴퓨터 비전이 발전할 수 있었다.
※ Pixel과 RGB
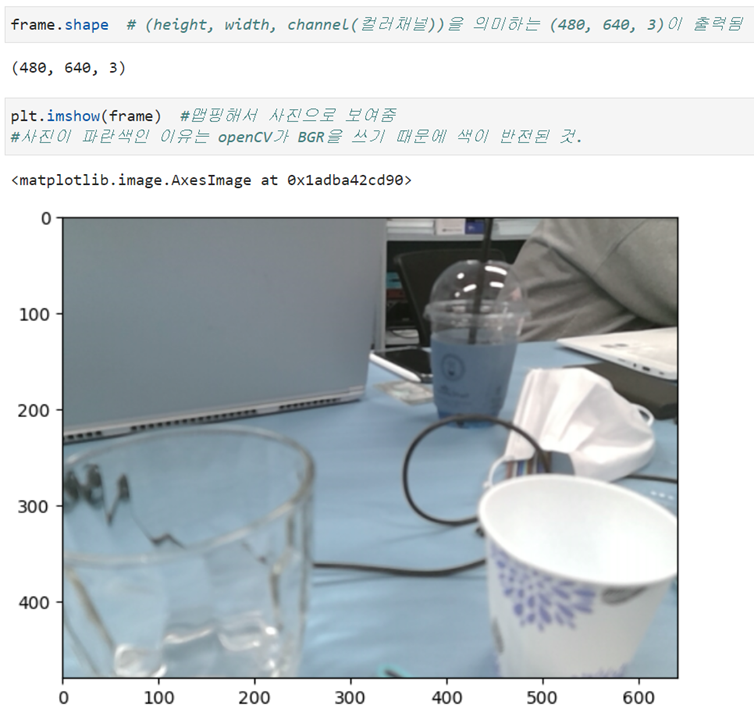
pixel은 숫자로 이루어져 있는데 그 크기가 1 Byte이다. (0~255의 숫자) R(1 Byte) G(1 Byte) B(1 Byte) 이렇게 (1Byte)^3으로 총 1600만가지 색을 표현할 수 있다.
A(1 Byte): Alpha, 즉 투명도까지 이용한다면?
결과적으로 image는 4 Byte로 표현이 가능하며 이것이 바로 1 Pixel 이다.
[실습]
<import 부분>
import numpy as np
import cv2 # camera, image 등 conputer vision을 쓰기 위한 openCV
import numpy as np # 빠른 계산을 위한 라이브러리
import matplotlib.pyplot as plt # visualization을 위한 matplotlib
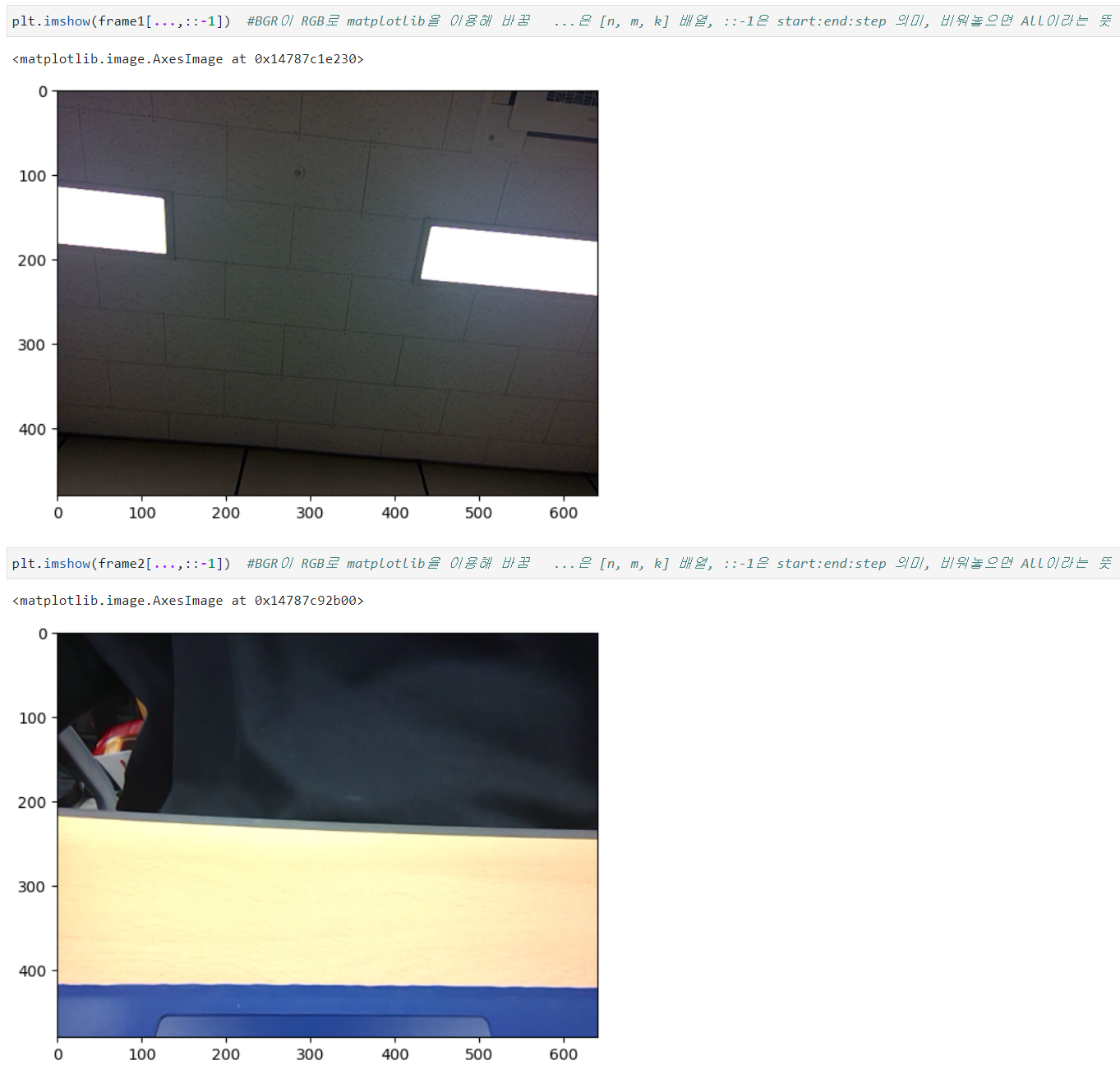
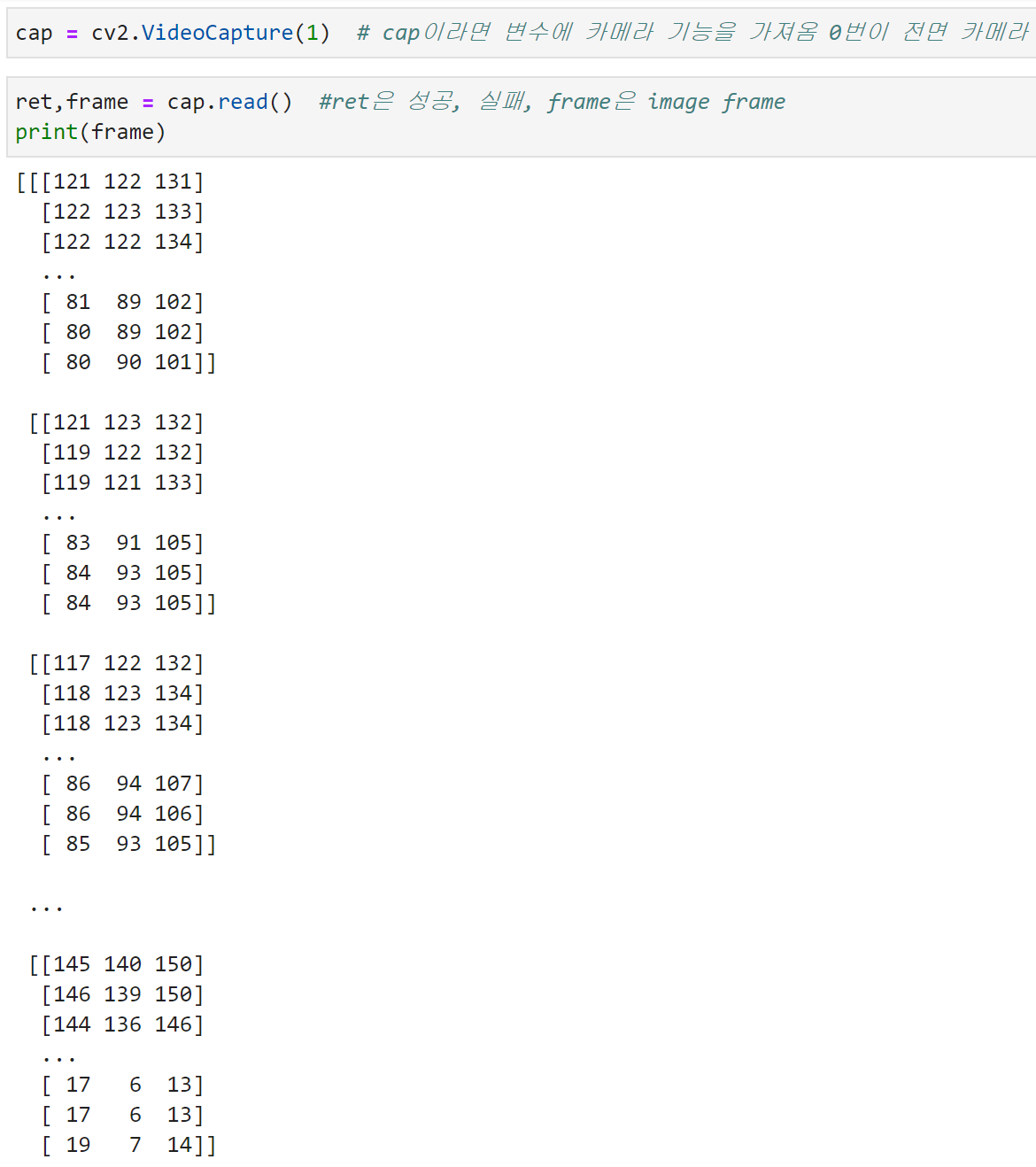
cap = cv2.VideoCapture(1) # cap이라면 변수에 카메라 기능을 가져옴 0번이 전면 카메라