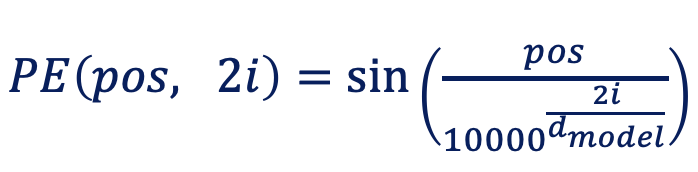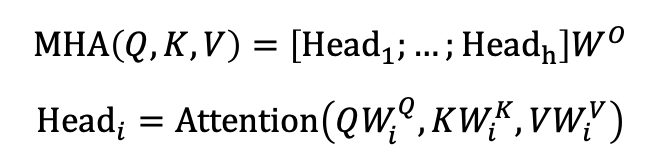이제, NMT performance를 끌어올리기 위한 고급기법들을 설명해보려 한다. 하나의 end2end모델에서 여러 언어쌍의 번역을 동시에 제공하는 mulilingual NMT에 대해 알아보자.
1.1 Zero-Shot Learning NMT에서 Zero-Shot Learning이라는 흥미로운 논문이 제안되었다.[Enabling Zero-shot translation; 2017] 이 방식의 특징은 여러 언어쌍의 parallel corpus를 하나의 모델에 훈련하면 부가적 학습에 참여한 corpus에 존재하지 않는 언어쌍도 번역이 가능하다는 점이다. 즉, 한번도 NMT에 data를 보여주지 않아도 해당 언어쌍 번역을 처리할 수 있다. (쉽게 말하자면, 모델이 train data에 직접 노출되지 않은 클래스를 인식하고 분류할 수 있는 능력을 의미)
[구현방법] ∙ 기존 병렬코퍼스의 맨 앞에 특수 token을 삽입, 훈련하면 된다. ∙ 이때, 삽입된 token에 따라 target언어가 결정된다.
src언어
target언어
기존
Hello, how are you?
Hola, ¿ cómo estás?
Zero-Shot
<2es> Hello, how are you?
Hola,¿ cómo estás?
위의 목표는 단순히 다국어 NMT end2end모델구현이 아닌, 서로 다른 언어쌍의 corpus를 활용해 NMT의 모든 언어쌍에 대해 전체적인 성능을 올릴 수 있는지 확인하려는 관점이다. 이에 대해 아래 4개의 관점으로 실험이 진행될 것이다.
Many-to-One ∙ 다수의 언어를 encoder에 넣고 train
이 방법은 실제문제로 주어진 언어 dataset외에도, 동시에 훈련된 다른언어의 dataset을 통해 해당 언어의 번역성능을 높이는 정보를 추가로 얻을 수 있다.
One-to-Many ∙ 다수의 언어를 decoder에 넣고 train
이 방법은 위의 방법과 달리, 성능향상이 있다보긴 어렵다. 게다가 양이 충분한(ex. ENG-FRA) corpus의 경우, oversampling을 하게되면 더 큰 손해를 보게 된다.
Many-to-Many ∙ 다수의 언어를 encoder, decoder 모두에 넣고 train
이 방법은 대부분의 실험결과가 하락세이다. (다만 다양한 언어쌍을 하나의 모델에 넣고 훈련한 것 치고는 BLEU Score는 괜츈한편)
Zero-Shot.NMT test ∙ 위의 방법으로 train된 모델에서 train corpus에 없는 언어쌍의 번역성능을 평가
Method
Zero-Shot 유무
BLEU
(a)
PBMT. Bridge
X
28.99
(b)
NMT. Bridge
X
30.91
(c)
NMT. POR→SPA
X
31.50
(d)
모델1]POR→ENG,ENG→SPA
O
21.62
(e)
모델2]ENG↔POR,SPA
O
24.75
(f)
모델2 + 점진학습
X
31.77
(a), (b) Bridge방법은 중간언어를 영어로 하여 2단계에 걸쳐 번역한다. 구문기반기계번역(PBMT: Phrase-Based Machine Translation)방식은 통계기반기계번역(SMT)의 일종이다.
(c) NMT '포르투갈어→스페인어'는 단순병렬코퍼스를 활용해 기존 방법대로 훈련한 baseline이다. 물론, zero-shot 훈련방식으로는 넘을 수 없는 수치이다.
(d), (e) 모델 1은 POR→ENG,ENG→SPA을 단일모델에 훈련한 방법이고 모델 2는 ENG↔POR, ENG↔SPA를 단일모델에 훈련한 방법이다.
(f) 모델2 + 점진(incremental)학습방식은 (c)보다 적은 양의 corpus로 훈련한 기존 모델에 추가로 모델 2방식으로 훈련한 모델이다.
비록 모델1과 모델2는 훈련중 한번도 POR→SPA parallel corpus를 보지 못했지만, 20이 넘는 BLEU를 보여준다. 하지만, 물론 (a), (b)보다는 성능이 떨어진다. 다행히도 (f)의 경우, (c)보다 큰 차이는 아니나 성능이 뛰어남을 확인할 수 있다.
∴ parallel corpus의 양이 얼마되지않는 언어쌍의 번역기 훈련 시, 이 방법으로 성능을 끌어올릴 수 있다. (특히 한국어-일어, 스페인어-포르투갈어 와 같이 매우 비슷한 언어쌍을 같은 src, tgt언어로 사용 시 그 효과가 증폭된다.)
2. Mono-Lingual Corpus
NMT훈련을 위해 다량의 parallel corpus가 필요하다. 보통 완벽하지는 않지만 나름 사용할만한 번역기가 나오려면 최소 300만 문장 쌍이상이 필요하다.
하지만, 인터넷에서 monolingual corpus는 많지만 multilingual corpus를 대량으로 얻기란 매우 힘든 일이다. 또한, 단일 언어 corpus가 양이 더욱 많기에 실제 우리가 사용하는 언어의 확률분포에 가까울 수 있고 따라서 더 나은 LM을 학습하기에 monolingual corpus가 훨씬 유리하다.
이번 Section에는 저렴한 monolingual corpus를 활용해 NMT성능을 쥐어짜보는 방법을 알아보자.
2.1 LM Ensemble
위의 방법은 딥러닝의 거두, Yoshua Bengio교수님께서 제안하신 방법이다. 여기서 LM을 명시적으로 앙상블하여 Decoder성능을 올리고자 했다.
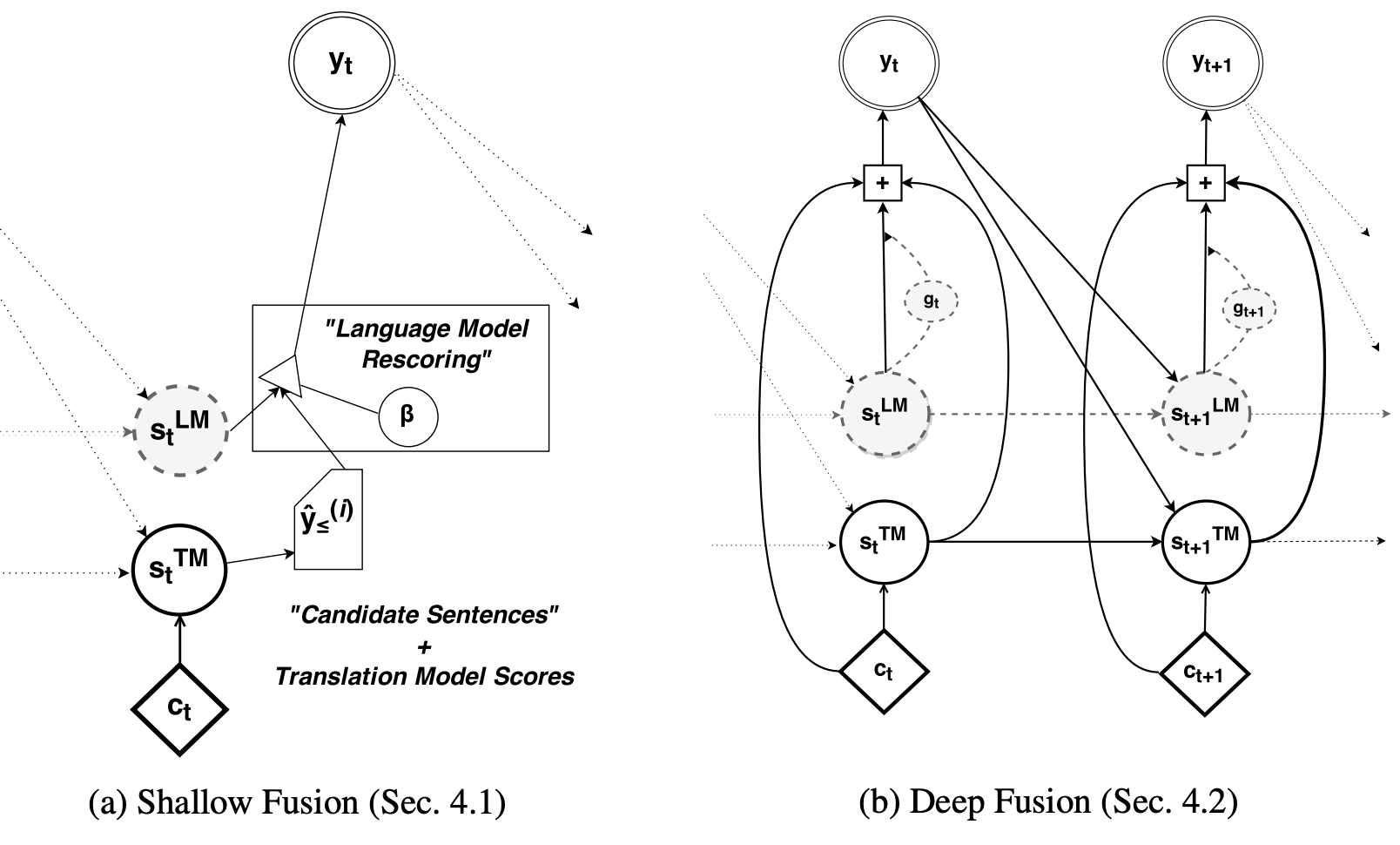
[Shallow Fusion 방법] ∙ 2개의 서로 다른 모델을 사용하는 방법
[Deep Fusion 방법] ∙ LM을 seq2seq에 포함시켜 end2end학습을 통해 하나의 모델로 만드는 방법
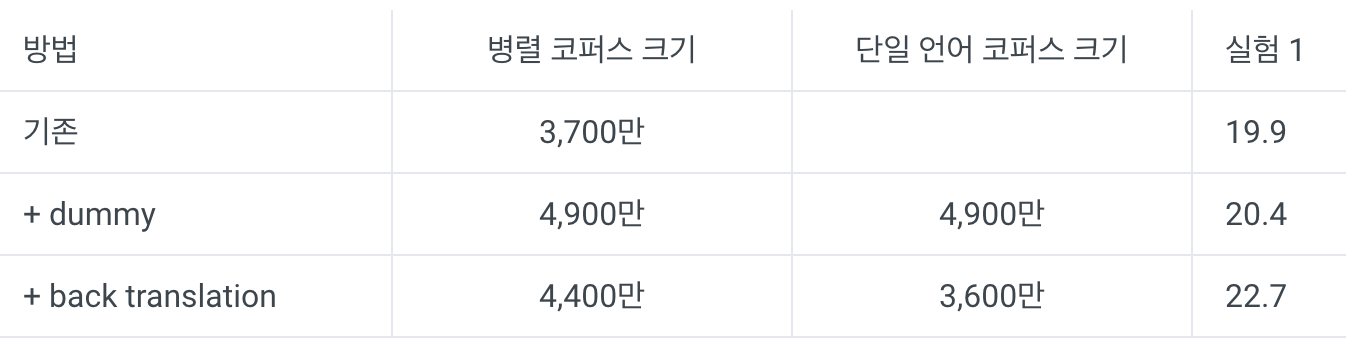
위의 두 방식에서 Deep Fusion방법이 더 나은 성능을 나타냈다. 두 방식 모두 monolingual corpus를 활용해 LM을 학습, 실제 번역기 훈련 시 신경망의 파라미터값을 고정한 채로 seq2seq모델을 학습시킨다. 아래 표는 '터키어→영어' NMT 성능을 각 방법을 적용해 실험한 결과이다. 뒤에 나올 back-translation이나 copied-translation들 보다 성능적 측면에서 이득이 적다. 하지만 수집한 단일언어코퍼스를 전부 활용할 수 있다는 장점이 존재한다.
2.2 Dummy-Sentence 활용 위의 명시적으로 LM을 앙상블하는 대신 Decoder로 하여금 단일언어코퍼스를 학습하는 방법의 논문을 제시했다.[https://arxiv.org/abs/1508.07909, https://arxiv.org/abs/1511.06709] 이 방법의 핵심은 src문장인 X를 빈 입력으로 넣어줌으로써, 그리고 attention등을 모두 Dropout으로 끊어줌으로써 Encoder로부터 전달되는 정보들을 없애는 것이다. 이 방법을 사용하면 Decoder가 단일언어코퍼스를 활용해 LM학습하는 것과 같다.
2.3 Back-Translation 한편, 위의 논문들에서 좀 더 발전된 다른 방법도 함께 제시되었다. 기존의 훈련된 역방향번역기(Back-Translation)를 사용해 mono-lingual corpus를 기계번역 후 합성병렬코퍼스(synthetic parallel corpus)를 만든 후, 이를 기존 양방향병렬코퍼스에 추가해 훈련에 사용하는 방식이다. ❗️중요한 점은 NMT로 만들어진 합성병렬코퍼스 사용 시, Back-Translation의 훈련에 사용한다는 점이다.
사실, 번역기를 만들면 하나의 parallel corpus로 2개의 NMT모델을 만들 수 있다. 따라서 이렇게 동시에 얻어지는 2개의 모델을 활용해 서로 보완을 통해 성능을 높이는 방법이다. 즉, Back Translation은 반대방향의 번역기를 통해 얻어지는 합성병렬코퍼스를 target신경망에 넣는다.
예를들어, KOR단일코퍼스가 있을 때, 아래 과정을 따른다. ∙ 기존에 훈련된 한→영 번역기에 기계번역을 시킴 ∙ 한영 합성 병렬코퍼스를 생성 ∙ 이를 기존에 수집한 한영 병렬코퍼스와 합친다. ∙ 이를 영→한 번역기를 훈련시키는 데 사용한다. 즉, 일종의 Augmentation 효과를 얻을 수 있다.
다만, 지나치게 많은 합성 병렬 코퍼스의 생성을 사용하면, 주객전도 현상이 될 수 있어 그 양을 제한해 훈련에 사용해야한다.
2.4 Copied Translation 이 방식은 Sennrich교수님이 제안한 방법으로 앞서 설명한 기존의 Dummy문장을 활용한 방식에서 좀 더 발전한 방식이다. 기존의 Dummy방법대신, src와 tgt쪽에 같은 data를 넣어 훈련시킨다.
∙기존의 Dummy문장을 Encoder에 넣는 방식은 Encoder에서 Decoder로 가는 경로를 훈련 시, DropOut이 필요 ∙이 방식은 그럴 필요가 없지만, src언어의 vocabulary에 tgt언어의 어휘가 포함되는 불필요함을 감수하긴 해야한다. 따라서 보통 Back-Translation방식과 함께 사용된다.
Method
TUR→ENG
ENG→TUR
Back-Translation
19.7
14.7
Back Translation + Copied
19.7
15.6
Conclusion 위와 같이 여러 방법들이 제안되었다. 다만, 소개된 여러 방법들 중, 구현의 용이성 및 효율성으로 인해 아래 2가지가 많이 사용된다. ∙ Back Translation ∙ Copied Translation 위의 두 방법들은 매우 직관적이고 간단하면서 효과적인 성능향상을 얻을 수 있다.
3. Transformer (Attention is all you need)
제목에서부터 알 수 있듯, 기존의 attention연산만을 활용해 seq2seq를 구현, 성능과 속도 둘 다 모두 성공적으로 잡아냈다.
3.1 Architecture
Transformer는 오직 attention만을 사용해 Encoding과 Decoding을 전부 수행한다. 이때, Skip-Connection을 활용해 신경망을 깊게 쌓도록 도와준다. Transformer의 Encoder와 Decoder를 이루는 Sub-Module은 크게 다음 3가지로 나뉜다. ∙ Self-Attention: 이전 층의 출력에 대해 attention연산을 수행 ∙ Attention: 기존 seq2seq와 같이 encoder의 결과에 대해 attention연산을 수행 ∙ Feed-Forward: attention층을 거쳐 얻은 결과물을 최종적으로 정리
Position Embedding 기존 RNN은 순차적으로 받아 자동으로 순서에 대한 정보를 기록한다.
하지만 Transformer는 RNN을 사용하지 않는다. 따라서, 순서정보를 단어와 함께 제공해야 된다. (같은 단어라도 위치에 따라 쓰임새, 역할이 달라질 수 있기 때문.) 결과적으로 위치정보를 Positional Embedding이라는 방법으로 나타낸다.
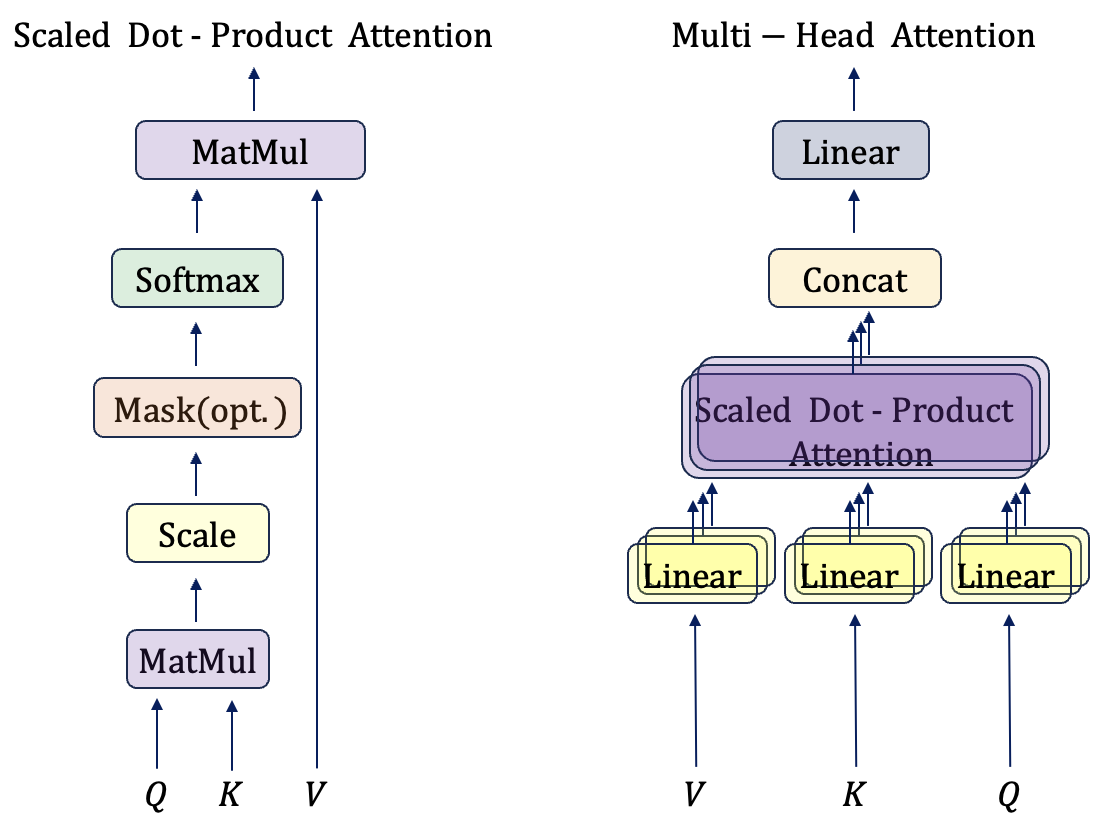
Attention Transformer의 Attention구성[MHA] Transformer는 여러개의 Attention으로 구성된 Multi-Head Attention(MHA)방식을 제안한다. 마치 CNN에서 여러 kernel이 다양한 feature를 추출하는 것과 같은 원리라 볼 수 있다. 이전시간, Q를 생성하기 위한 linear transformation을 배우는 과정이라 소개했다.
이때, 다양한 Q를 생성해 다양한 정보들을 추출한다면, 더욱 유용할 것이다. 따라서 Multi-Head로 여러 attention을 동시에 수행한다. Q,K,V를 입력으로 받는 기본적인 Attention 수식은 다음과 같다.
앞의 Attention함수를 활용한 MHA 수식은 다음과 같다.
∙ Self-Attention의 경우, Q,K,V 모두 같은값으로써 이전층의 결과를 받아온다. 그리고 일반 Attention의 경우, Q는 이전층의 결과이고 K, V는 encoder의 마지막 층 결과가 된다.
이때, Q,K,V의 tensor_size는 다음과 같다. (이때, n = src_length, m = tgt_length) ∙ |Q| = (batch_size, n, hidden_size) ∙ |K| = |V| = (batch_size, m, hidden_size)
또한, MHA의 신경망 가중치 WiQ, WiK, WiV, WO의 크기는 아래와 같다. ∙ |WiQ|=|WiK|=|WiV| = (hidden_size, head_size) ∙ |WO| = (hidden_size×h , hidden_size) 이때, hidden_size=head_size×h이며 보통 512값을 갖는다. transformer에서는 tgt_sentence의 모든 time-step을 encoder나 대상 tensor의 모든 time-step에 대해 한번에 attention을 수행한다. 이전장의 attention결과, tensor의 크기는 (batch_size, 1, hidden_size)였지만 MHA의 결과 tensor의 크기는 (batch_size, m, hidden_size)가 된다. Self-Attention도 K,V가 Q와 같은 tensor일 뿐, 원리는 같기에 m=n이다.
Decoder의 Self-attention Decoder에서 Self-Attention은 Encoder와 결이 살짝 달리하는데, 이전 층의 출력값으로 Q,K,V를 구성하는 것 같지만 약간의 제약이 가미된다. 왜냐하면 inference time에서 다음 time-step의 입력값을 당연히 알 수 없기 때문이다.
따라서 train에서도 이전 층의 결과값을 K와 V로 활용하는 self-attention을 수행하더라도 미래의 time-step에 접근할 수 없도록 똑같이 구현해줄 필요가 있다. 이를 위해 attention연산 시, masking을 추가해줘야한다. 이를 통해 미래의 time-step에 대해 attention_weight를 가질 수 없게 한다.
[Attention을 위한 Mask생성 방법] mini-batch내부의 문장들은 길이가 서로 다를 수 있는데, masking을 통해 선택적으로 attention수행이 가능하다. mini-batch의 크기는 mini-batch 내부의 가장 긴 문장의 길이(max_length)에 의해 결정된다. 길이가 짧은 문장들은 문장의 종료 후에 padding으로 채워진다. 문장 길이에 따른 mini-batch 형태 따라서 해당 mini-batch가 encoder를 통과하고 decoder에서 attention연산을 수행 시 문제가 발생한다. padding이 존재하는 time-step에도 attention가중치가 넘어가 Decoder에 쓸데없는 정보를 넘겨줄 수 있다. 따라서 해당 time-step에 attention가중치를 추가적으로 다시 0으로 만들어줘야 한다. mask 적용 시 attention
Google은 transformer가 기존 여타 알고리즘들보다 훨씬 좋은 성능을 달성했음을 밝혔는데, 기존 RNN 및 meta(facebook)의 ConvS2S(Convolutional Sequence to Sequence)보다 훨씬 빠른 속도로 훈련했음을 밝혔다(FLOPs).
이런 속도의 개선의 원인 중 하나로 transformer구조와 함께 input feeding의 제거 2가지 요인이 기인했다 보는 시각이 많은데, 기존 RNN 기반 seq2seq방식은 input feeding이 도입되면서 decoder훈련 시 모든 time-step을 한번에 할 수 없게 되었다. 따라서 FLOPs 대부분의 bottleneck문제가 decoder에서 발생하게 된다. 하지만 transformer의 경우, input feeding이 없기에훈련 시 한번에 모든 time-step에 대한 병렬처리가 가능하다.
Conclusion transformer의 혁신적인 구조적 차이는 seq2seq를 활용한 NMT 및 자연어 생성에도 사용되었다. 또한, BERT와 같은 자연어이해의 범주로까지 폭넓게 사용되고 있다.
이번시간에는 NMT의 성능을 더 향상시키는 방법들을 다루었다. 신경망은 data가 많아질수록 그 성능이 향상되는데, 번역과 같은 seq2seq를 활용한 문제를 해결할 때, train data인 parallel corpus가 많을수록 좋다. 다만, parallel corpus는 매우 수집이 어렵고 제한적이다. (보통 완벽하지는 않지만 나름 사용할만한 번역기가 나오려면 최소 300만 이상의 문장 쌍이 필요)
따라서 zero-shot learning을 사용한다. zero-shot learning은 모델이 train data에 직접 노출되지 않은 클래스를 인식하고 분류할 수 있는 능력으로 parallel corpus의 양이 얼마되지않는 언어쌍의 번역기 훈련 시, 이 방법으로 성능을 끌어올릴 수 있다. (특히 한국어-일어, 스페인어-포르투갈어 와 같이 매우 비슷한 언어쌍을 같은 src, tgt언어로 사용 시 그 효과가 증폭된다.) 이런 제한적인 상황에 대해 단일언어(monolingual corpus)를 활용해 NMT 성능을 향상하는 방법 또한 다뤄보았다. 뒤에서 단일언어코퍼스를 활용한 성능향상에 대해서도 중점적으로 다룰 것이다. 또한 transformer라는 모델구조로 인해 seq2seq가 더욱 다양하게 구현될 수 있었다. 특히 transformer는 attention만으로 seq2seq를 구현하였기에 속도와 성능 둘 다 잡아냈다.