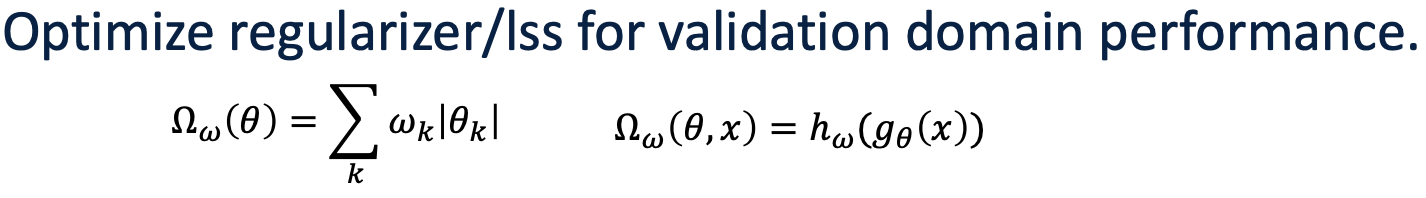🏢 ETRI (2024.01.05)
📖 공부! (9:00-12:00)
먼저 읽을 논문 리스트부터 뽑아보았다.
∙ Unsupervised Domain Adaptation of Object Detectors: A Survey (IEEE 2023)
∙ Deep Domain Adaptive Object Detection: a Survey (IEEE 2020)
∙ Domain Adaptive Faster R-CNN for Object Detection in the Wild (CVPR 2018)
∙ Multi-Source Domain Adaptation for Object Detection (ICCV 2021)
∙ Multi-Granularity Alignment Domain Adaptation for Object Detection (CVPR 2022)
∙ Progressive Domain Adaptation for Object Detection (WACV 2020)
∙ SimROD: A Simple Adaptation Method for Robust Object Detection (ICCV 2021)
∙ ConfMix: Unsupervised Domain Adaptation for Object Detection via Confidence-based Mixing (WACV 2023)
∙ Domain Contrast for Domain Adaptive Object Detection (IEEE 2021)
∙ Unsupervised Domain Adaptive Object Detection using Forward-Backward Cyclic Adaptation (ACCV 2020)
∙ One-Shot Unsupervised Domain Adaptation for Object Detection (IEEE 2020)
∙ A Free Lunch for Unsupervised Domain Adaptive Object Detection without Source Data (AAAI 2021)
∙ Object detection based on semi-supervised domain adaptation for imbalanced domain resources (Machine Vision and Applications 31 2020)
∙ Cross-domain adaptive teacher for object detection (CVPR 2022)
🍚 밥이다 밥!

마찬가지로 동편제(한식)... ETRI표 떡갈비 진짜 맛있었다!!(사실 경양식 불고기? 느낌이었지만)
🛠️ 서버 작업! (14:00-18:00)

GPU 넣고 새로 OS(Linux) 깔고 작업하는데 힘들어 죽는줄ㅠㅠ
GUI에 문제가 있는 서버, Linux 접속이 안되는 서버 등등 GPU도 장착하고 약간 밑바닥부터 시작하는 느낌이어서 새롭기도 했고, 그동안 이미 만들어진 서버로 🍯빨고 있었던 것 같아서 좀 반성(?)도 되었던 시간이었다ㅎㅎ
🍚 밥이다 밥!
ETRI동기분들이랑 간단한? 식사를 가졌다.
미소야라는 곳에서 먹었었는데 총 12명(나포함)이 식당에 들어서니 한 공간을 다 차지해 버렸다.
식사로는 우삼겸 덮밥을 골랐다. (이름만 보고 골랐던게 진짜진짜 실수였다.)

우삼겸 덮밥....이게...?
내가 아는 우삼겹 덮밥은 간장소스 베이스로 만들어져야하는데
분명히 사진속에서는 약간 갈색빛이 돌았던 것 같았는데... 시뻘건 무언가가 왔다.
진짜 처음에는 다른사람 메뉴가 나한테 잘못 배달온줄 알았다.
매워 죽는줄 알았는데 감사하게도 물을 따라주셔서 살았다.(사실 이 글을 적는 지금도 배 아픈 것 같다)
🚲 퇴근! (21:00 -)
2차로 카페에서 아이스크림까지 먹고(다이어트 실패ㅋㅋㅋ)
당연히 자전거 타슈타고 퇴근했다. 퇴근길에 찍은 신세계 백화점은 멋있구만...

🏋🏻 운동! (22:00 -)
열심히 벤치프레스만 했다ㅎㅎ (하체는 자전거로 이미 유산소겸 하체운동겸 끝이라...)
현대인은 운동부족이랬나... 당연히도 매일같이 헬스장에 가서 운동을 하니까 난 상관없겠지?
근데 헬스장 밖에서 이렇게 찍으니 감옥같....ㅋㅋㅋ

📌 TODO List:
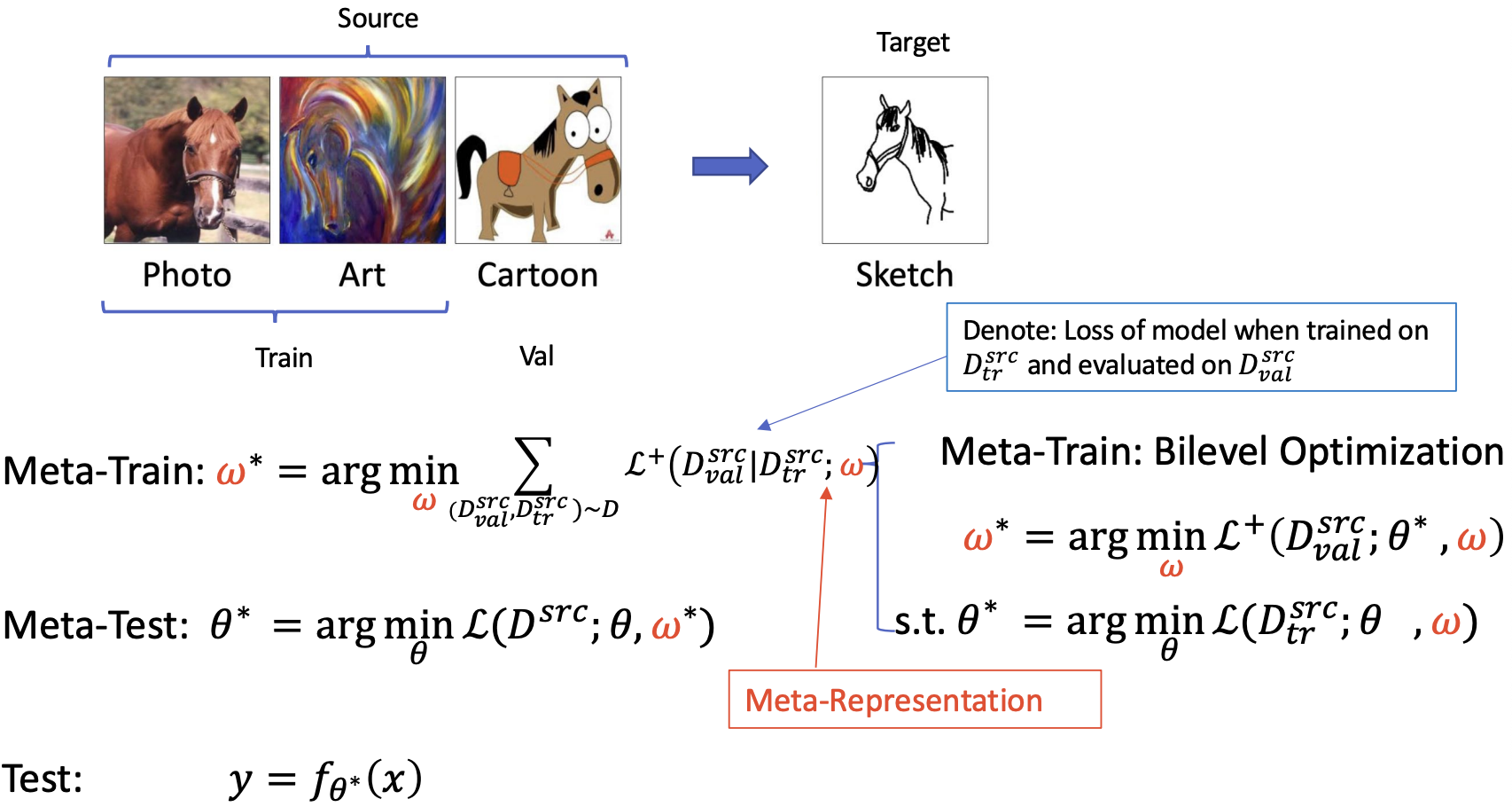
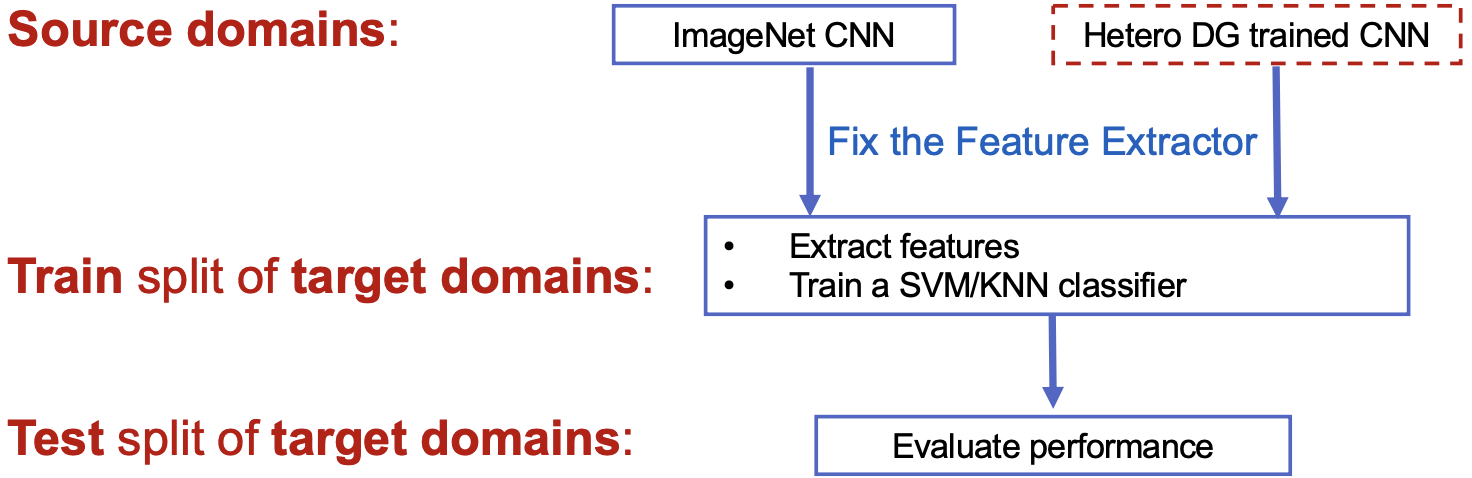
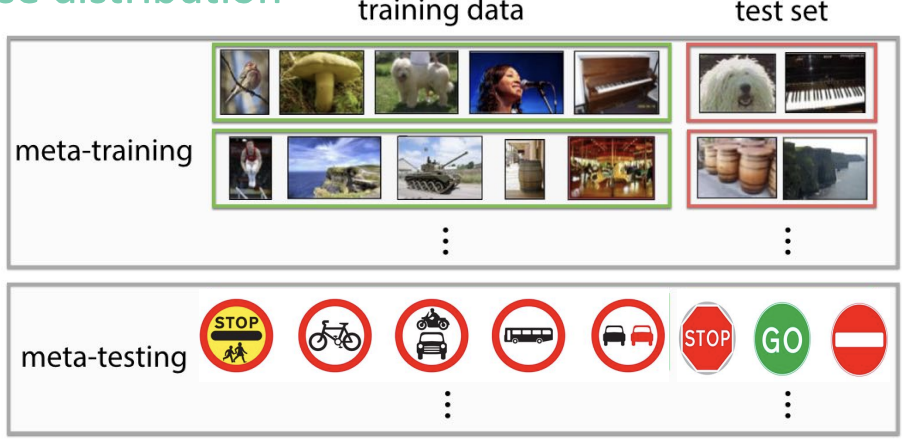
1. Detection분야 Domain Adaptation 논문 List:
∙ Abstract, Conclusion 정리 → ppt만들기
2. Deep Learning 2024(Bishop): Chapter 2 읽고 공부하기
'2024 winter > ETRI(일상)' 카테고리의 다른 글
| [ETRI]2024.01.10 (4) | 2024.01.10 |
|---|---|
| [ETRI]2024.01.09 (2) | 2024.01.09 |
| [ETRI]2024.01.08 (4) | 2024.01.08 |
| [ETRI]2024.01.04 (0) | 2024.01.04 |
| [ETRI]2024.01.03 (4) | 2024.01.03 |